
1.2018年のGoogleの研究成果を振り返って(4/6)まとめ
・Googleの2018年のAI関連の研究や成果の振り返り
・AutoML、TPU、オープンソースソフトウェアとデータセット
・研究開発の結果から実際の製品として世に出たものまで幅広く紹介
2.2018年のGoogleの研究成果のまとめ
以下、ai.googleblog.comより「Looking Back at Google’s Research Efforts in 2018」の意訳です。久々のJeff Deanによる投稿です。
AutoML
AutoMLは、メタラーニングとも呼ばれ、より良い機械学習モデルを機械学習を使って自動で探索する試みです。私達はこの分野で長年研究を続けており、長期的な目標は、既に解決済み他の問題から導き出された洞察と能力を学習して、新しい問題を自動的に解決する学習システムを開発することです。
この分野での私達の初期の研究は主に強化学習を使っていましたが、私達は遺伝的アルゴリズムの使用にも興味を持っています。昨年は、遺伝的アルゴリズムを使用して、最先端のニューラルネットワークアーキテクチャ探索システムを使ってさまざまな視覚的タスクに最適化されたモデルを自動的に発見する方法を説明しました。
また、強化学習がニューラルネットワークアーキテクチャ探索以外の問題にどのように適用できるかを調査し、それが
1)多種多様な画像モデルの精度を改善するために画像変換シーケンスを自動的に生成できることを示しました。
2)一般的に使用されている最適化よりも効果的な新しい最適化式を見つけました。
AdaNetに関する私たちの研究は、学習保証付きの高速で柔軟なAutoMLアルゴリズムを開発する方法を示しました。
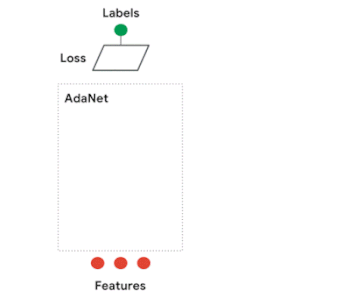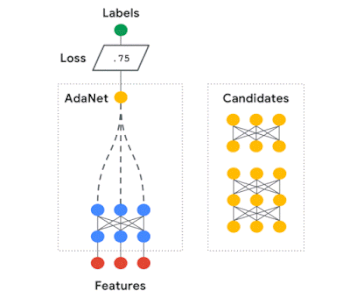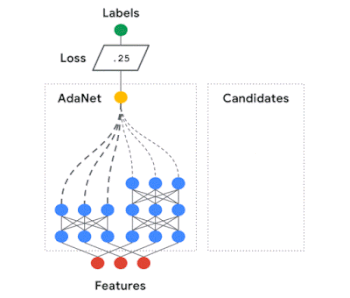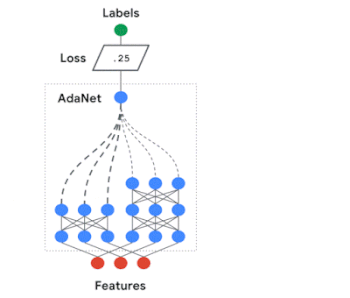
AdaNetはニューラルネットワークの集合を適応的に成長させます。
反復ごとに、各候補のアンサンブル損失を測定し、次の反復に採用する最適な候補を選択します。
私たちにとってもう1つの焦点は、計算上の効率や応答時間に厳しい制約があるスマートフォンや自動運転自動車などの環境で実行できるように、計算効率の高いニューラルネットワークアーキテクチャを自動的に発見することでした。
このために、強化学習アーキテクチャ検索のための報酬関数におけるモデルの精度とその推論計算時間を組み合わせることで、特定のパフォーマンスの制約を満たしながら非常に正確なモデルを見つけることができることを示しました。また、MLを使用して、MLモデルを自動的にパラメータを少なくして圧縮し、計算リソースを少なくする方法を学習しました。
TPUs
Tensor Processing Unit(TPU)は、Googleが自社開発した機械学習専用ハードウェアアクセラレータで、トレーニングと推論の両方を大規模に強化するためにゼロから設計されています。TPUはBERT(前述)などのGoogleの研究をブレークスルーさせる事を可能にし、また世界中の研究者がオープンソースを介してGoogleの研究を発展させ、独自の新しいブレイクスルーを追求することを可能にします。
たとえば、誰でもColabを介してTPUのBERTを無料で微調整できます。TensorFlowResearch Cloudは、何千人もの研究者にさらに大量の無料のクラウドTPUコンピューティング能力から利益を得る機会を与えました。
複数世代のTPUハードウェアをCloud TPUとしてクラウド利用可能にし、大規模な機械学習トレーニングをより実行しやすくしました。Cloud TPUサービスにはTPU Podと呼ばれるTPUを複数組み合わせた機械学習用スーパーコンピュータを含みます。
社内的にも、機械学習研究の迅速な進歩を可能にすることに加えて、TPUは、検索、YouTube、Gmail、Googleアシスタント、Google翻訳、その他を含むGoogleのコア製品全体にわたって大きな改善をもたらしました。

第三世代のTPU(左)とTPU v3 Podの一部(右)。TPU v3は、Googleの最新世代のTensor Processing Unit(TPU)です。Cloud TPU v3として外部の顧客も利用可能なこれらのシステムは最大パフォーマンスを発揮させるために液冷され(コンピュータチップ+液体=エキサイティング!)、そして完全なTPU v3 Podは世界最大の機械学習問題解決のために100ペタフロップス以上の計算能力を発揮できます。
オープンソースソフトウェアとデータセット
オープンソースソフトウェアのリリースと新しい公共利用可能なデータセットの作成は、私たちが研究とソフトウェアエンジニアリングの両方のコミュニティに貢献する2つの主要な方法です。
この分野での最大の取り組みの1つは、TensorFlowです。これは、2015年11月にリリースされた機械学習計算用の広く普及したシステムです。2018年にTensorFlowの3回目の誕生日を迎えました。この間、TensorFlowは30万回以上ダウンロードされ、1700人を超える貢献者が45,000回のコミットを追加しました。2018年、TensorFlowには8つのメジャーリリースがあり、eager executionおよびDistribution Strategy APIなどの主要機能が追加されました。私達は、開発プロセスに携わっているコミュニティのためにパブリックデザインレビューを開始し、特別な利益団体を介して貢献者を巻き込みました。
TensorFlowが、トップクラスの機械学習とディープラーニングのフレームワークの中で、最も強力なGithubユーザー保持力を持っていることを嬉しく思います。TensorFlowチームはまた、Githubの問題に迅速に対処し、外部の貢献者にスムーズな道筋を提供するよう努めています。学術界でも、Google Scholarのデータによれば、Googleは世界の機械学習とディープラーニングの大部分の研究を論文で強化し続けています。
TensorFlow Liteはわずか1年で現在世界中の15億以上のデバイスに搭載されています。さらに、TensorFlow.jsはJavaScriptのナンバーワン機械学習フレームワークです。発表から9か月以内に、Githubで2百万を超えるContent Delivery Network(CDN)ヒット、25万ダウンロード、そして10,000以上の星を獲得しました。
既存のオープンソースエコシステムに関する継続的な作業に加えて、2018年に、私たちは柔軟で再現可能な強化学習のための新しいフレームワークや、データセットの特性を(コードを書く必要なしに)素早く理解するための新しい視覚化ツールを紹介しました。更に、ランキング付け(検索エンジン、推薦システム、機械翻訳、対話システム、さらには計算生物学を含むドメイン全体に適用可能な、リスト全体の有用性を最大化するような方法でアイテムのリストを順序付けるプロセス)を行うモデルを含む、機械学習の問題を表現するための高レベルライブラリを追加しました。
学習保証付きの高速で柔軟なAutoMLソリューションのフレームワーク、TensorFlow.jsを使用してブラウザ内でリアルタイムのt-SNEビジュアライゼーションを行うためのライブラリ、および電子ヘルスケアデータを扱うためのFHIRツールおよびソフトウェアを追加しました。
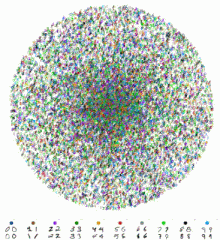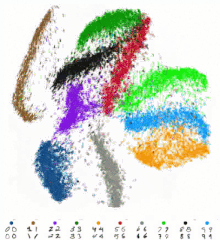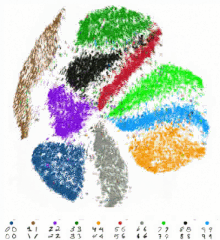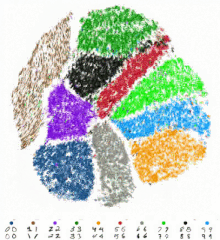
完全なMNISTデータセットのtSNE埋め込みへのリアルタイム視覚化。データセットには60,000の手書き数字の画像が含まれています。
パブリックデータセットは多くの分野で大きな進歩をもたらす大きなインスピレーションの源です。興味深いデータや問題へのアクセスと、さまざまなタスクでより良い結果を得るための健全な競争力の両方を提供します。今年は、すべてのWebから公開データセットを見つけるための新しいツールであるGoogle Dataset Searchをリリースしました。
何年にもわたって私たちは、何百万もの一般的な注釈付きの画像やビデオから、ロボットアームに掴む挙動を学習させるデータセット、音声認識のためにクラウドソースで集めたベンガル語データセットまで、たくさんの新しい斬新なデータセットを作成しました。 2018年に、我々はそのリストにさらに多くのデータセットを追加しています。

インドとシンガポールの写真がCrowdsourceアプリを使ってOpen Images Extendedに追加されました。
私たちは、Open Images V4をリリースしました。これには、600カテゴリの19万画像に154万の境界ボックスと、19,794カテゴリの301万の人間検証済みの画像ラベルを含みます。
また、crowdsource.google.comを使用して世界中から何万人ものユーザーによって提供された55万の注釈を追加することによって、世界中の地域の人々や風景の多様性を追加してこのデータセットを拡張しました。
私たちは、人間の行動やビデオのスピーチを理解するための最先端技術を向上させるために、ビデオの視聴覚注釈を提供するAtomic Visual Actions(AVA)データセットをリリースしました。 また、YouTube-8Mを最新に更新し、および第2回YouTube-8M大規模ビデオ理解チャレンジとワークショップを開催しました。
HDR+ Burst Photographyデータセットは、コンピューター写真の分野で多種多様な研究を可能にすることを目的としています。Google-Landmarksは、ランドマーク認識のための新しいデータセットと課題でした。
また、データセットのリリースではありませんが、画像に注釈を付ける作業を高速化するための実験的なML搭載インタフェースであるFluid Annotationを使用して、ビジュアルデータセットを迅速に作成できるようにする手法を検討しました。
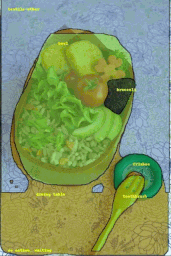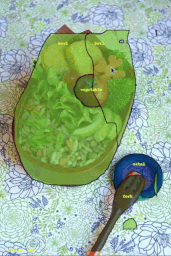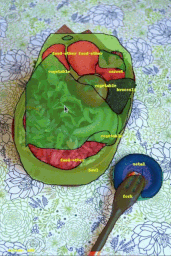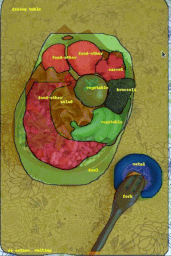
COCOデータセットの画像に対して実行中のFluid Annotation画面。画像クレジット:ガムネー。
時折、Googleはコンペを開催し、研究コミュニティが新しい種類の課題に挑戦する事を助けます。そして、私達全員が困難な研究問題の解決に一緒に取り組むことができるようにします。多くの場合、これらは新しいデータセットのリリースのタイミングで行われますが、必ずしもそうとは限りません。
今年は、地域的な偏りを無くした堅牢なモデルを作成することを目指して、Inclusive Images Challengeを開催しました。iNaturalist 2018 Challengeはコンピュータによる視覚認識で、よりきめ細かい識別(画像内の植物の種類など)を可能にすることを目的としたコンペでした。
Kaggleの “Quick、Draw!” QuickDrawチャレンジはお絵かきゲームで書かれた絵をより良く識別するための落書き認識チャレンジでした。Conceptual Captionsは、より大きな画像キャプションモデル研究を可能にすることを目的とした大規模な画像キャプションデータセットと課題でした。
(2018年のGoogleの研究成果を振り返って(3/6)からの続きです)
(2018年のGoogleの研究成果を振り返って(5/6)に続きます)
3.2018年のGoogleの研究成果を振り返って(4/6)関連リンク
1)ai.googleblog.com
Looking Back at Google’s Research Efforts in 2018

