
1.dopamine:柔軟で再現可能な強化学習のための新フレームワークまとめ
・強化学習を簡単に体験できるTensorFlowベースの新フレームワーク、dopamineが公開
・明瞭且つシンプルで再現性を意識し、サンプルもドキュメントも豊富
・60のゲームについて4種のエージェントの完全なトレーニングデータも提供
2.強化学習のための新フレームワークdopamine
以下、ai.googleblog.comよりIntroducing a New Framework for Flexible and Reproducible Reinforcement Learning Researchの意訳です。
強化学習(RL:Reinforcement learning)の研究は、ここ数年、多くの重要な進歩を見せています。これらの進歩により、人工知能は対戦ゲームで人間に勝つようになりました。碁のAlphaGoやAlphaGo Zero、Dota2のOpenAI Five、AtariレトロゲームではDeepMindのDQNが注目されています。
具体的には、DQNにリプレイメモリを導入することで以前の学習体験を活用したり、大規模な分散トレーニングを利用して複数のワーカーで分散学習をさせたり、分散手法により人工知能は単なる期待値ではなく確率分布をモデル化して、世界のより完全なイメージを学ぶことができるようになりました。
これらのアルゴリズムの進歩は、ロボット工学のような他の領域にも適用可能であるため、重要です(最近のロボットに一般化スキルを学ばせる手法と視覚的自己適応のためのロボットの自己学習を参照)。
これらの進歩を更に発展させるには、しばしば明確な方向性なしに、すばやく学習を反復し、確立した構造に揺らぎを与える必要があります。
しかし、既存の強化学習フレームワークのほとんどは、研究者が強化学習を効果的に反復できる柔軟性と安定性の組み合わせを提供していません。そのため、新しい研究の方向性が模索されていますが、その試みはすぐには効果的な手法に繋がらない可能性があります。さらに、既存のフレームワークからの結果を再現することはしばしば時間がかかりすぎるため、科学的な再現性の問題が生じる可能性があります。
本日、我々は初心者にも経験豊富なRL研究者にも、同様の柔軟性、安定性、再現性を提供することを目的とした新しいTensorflowベースのフレームワーク、dopamineを紹介します。
脳における報酬動機付け行動の主要な要素の1つに触発され、神経科学と強化学習研究の間の強い歴史的関係を反映して、このプラットフォームは、過激な発見を引き起こすような投機的研究を可能にすることを目指しています。このリリースには、フレームワークの使用方法を明確にする一連のコラボラトリーのファイルも含まれます。
使いやすさ
明瞭さと単純さがこのフレームワークの設計時に2つの重要な考慮事項でした。私たちが提供するコードはコンパクトで(約15個のPythonファイル)、ドキュメントも良く整備されています。これは、成熟したベンチマークとして知られているArcade Learning Environmentと、以下の4種類のエージェントに集中する事で達成されました。
・DQN
・C51
・Rainbowエージェントの簡略版
・Implicit Quantile Networkエージェント(先月のICMLで先月発表されたばかりです)
このシンプルさにより、研究者が強化学習人工知能の内部の仕組みを理解し、新しいアイデアをすばやく試すことが容易になることを願っています。
再現性
私たちは、強化学習研究における再現性の重要性に特に気を使いました。この目的のために、私たちはコードに完全なテストカバレッジを提供します。これらのテストは、追加のドキュメントとして扱う事もできます。さらに、我々の実験的枠組みは、Machado等が論文で発表したArcade Learning Environmentで経験的評価を標準化する際の推奨に従っています。
ベンチマーキング
新しい研究者が既に確立された方法を使って彼らのアイデアを迅速に評価できることは重要です。そのため、Arcade Learning Environmentでサポートされている60のゲームについて4種のエージェントの完全なトレーニングデータを提供しています。Pythonのpickleファイル(今回紹介するフレームワークで訓練されたエージェント用)、JSONデータファイル(他のエージェントとの比較用)としてです。
さらに、60のゲームすべてで、提供されているすべてのエージェントの学習を迅速に視覚化できるWebサイトを提供しています。以下に、Arcade Learning EnvironmentでサポートされているAtari 2600ゲームの1つであるSeaquestを4種のエージェントで学習させた結果を示します。
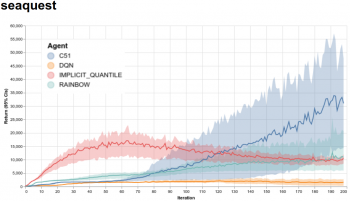
Seaquestを4種のエージェントで訓練させた結果の視覚化。 x軸は反復を表し、各反復は100万ゲームフレーム(4.5時間の連続プレイに相当)です。 y軸はプレイごとに得られる平均得点です。陰影の付いた領域は、5回の独立したプレイから求めた信頼区間を示します。また、これらのエージェントからのディープネットワーク、生の統計ログ、Tensorboardを利用してプロットするためのTensorflowイベントファイルも提供しています。これらはすべて、私たちのサイトのダウンロードセクションにあります。
私たちの希望は、フレームワークの柔軟性と使いやすさが、研究者が新しいアイデアを漸進的かつ根本的に試すことができるようにすることです。私たちはすでに研究に積極的に使用しており、多くのアイデアを迅速に反復する柔軟性を提供しています。大規模なコミュニティがそれをどのように作ることができるのかを見てうれしく思います。私たちのgithubレポでそれをチェックして、それと遊んで、あなたの考えを知らせてください!
謝辞
このプロジェクトは、Googleでのいくつかのコラボレーションのおかげで可能でした。コアチームにはMarc G. Bellemare、Pablo Samuel Castro、Carles Gelada、Subhodeep Moitra、Saurabh Kumarが含まれます。また、Sergio Guadamarra、Ofir Nachum、Yifan Wu、Clare Lyle、Liam Fedus、Kelvin Xu、Parisi Emilio、Hado van Hasselt、Georg Ostrovski、Will Dabney、Googleでテストしてくれた多くの方々に感謝します。
3.dopamine:柔軟で再現可能な強化学習のための新フレームワーク感想
なんかもう色々凄いです。コラボラトリーのfileも公開されているので、ブラウザからポチッと自分のGoogle DriveにNoteBook形式でコピーしてサクッと大抵のマシンより早く動かせてしまいます。あまりに簡単すぎて呆然として有難味がイマイチ感じられないレベルで凄いです。
それと元文書では「新フレームワーク」と言う表現で最後まで押し通してdopamineの名前が出てこないのですが、謙虚なのか何か意味があるのかちょっと不明です。dopamine、ドーパミンは中枢神経系に存在する神経伝達物質(ホルモン)で、運動調節、意欲、学習などに関わる物質だそうです。
4.dopamine:柔軟で再現可能な強化学習のための新フレームワーク関連リンク
1)ai.googleblog.com
Introducing a New Framework for Flexible and Reproducible Reinforcement Learning Research


コメント