
1.AdaNet:高速かつ柔軟な学習保証付きでAutoMLをアンサンブルするまとめ
・AdaNetではAutoMLで自動構築したモデルを自動的にアンサンブル学習に組み込む事ができる
・AutoMLの動作やAdaNetによるアンサンブル手法についても使用者が細かく設定できる
・アンサンブルの汎化誤差と訓練誤差のトレードオフも学習保証として考慮されている
2.AdaNetとは?
以下、ai.googleblog.comより「Introducing AdaNet: Fast and Flexible AutoML with Learning Guarantees」の意訳です。元記事の投稿はOctober 30, 2018、Google AIのCharles Weillさんの投稿です。AdaNetとは自動でニューラルネットワークを進化させるAutoMLの考え方をアンサンブル学習に拡張したものです。アンサンブル学習とは、複数の人工知能でコンサートを行って単一の人工知能より優れた音色を出す手法と理解するとイメージしやすいです。
アンサンブル学習は、複数の機械学習の出力をまとめて一つの出力として利用する手法です。様々な種類の機械学習を組み合わせる事により、単一の機械学習より良いパフォーマンスを出す事が理論的にも確かめられており、歴史的にもNetflixが過去に開催した$100万ドルの賞金がかかったコンペや多数のKaggleのコンペで勝利をもたらした実績があります。
しかし、複数のモデルをトーレニングする必要があるのでトレーニング時間が長くなるのと、複数の機械学習モデルを使いこなすにはそれぞれのモデルについて独自の専門知識が必要になるため、実務の場ではそれほど沢山使われていません。
実務の場ではあまり使われていないとは言え、計算機パワーの向上とTPUなどのディープラーニング学習用に特化したハードウェアがより容易に利用できるようになれば、個々の機械学習モデルはより強力になり、その結果、アンサンブル学習もより効果的になります。さてここで、ニューラル・アーキテクチャーを自動的に探索し、最良のモデルを自動的に作り上げ、それを高品質なアンサンブル学習に自動的に組み込むツールを想像してみてください。
本日、私達は高品質なモデルを自動的に学習する軽量のTensorFlowベースのフレームワークであるAdaNetを共有できることに興奮しています。AdaNetは機械学習の専門家の支援が必要になる箇所を最小限に抑えており、誰でも使えるようになる事を目指しています。
AdaNetは、直近の強化学習と自己進化型AutoMLの成果を基盤に構築されており、迅速で柔軟な学習を実現しつつ、学習保証も提供しています。重要なことは、AdaNetはニューラルネットワークアーキテクチャを自動で探索し、学習するだけでなく、さらに優れたモデルを得るためにアンサンブル学習に組み込むための一般的なフレームワークも提供します。
AdaNetは初心者にも使いやすく高品質なモデルを作成可能です。本来ならば最適なニューラルネットワークアーキテクチャの選択に費やされた時間や、機械学習ネットワークをサブネットワークとしたアンサンブル学習を実現するためのアルゴリズムを実装する時間を節約できます。AdaNetはさまざまな深度と幅のサブネットワークを追加して多様なアンサンブルを作成し、パラメータの数とパフォーマンスの向上を達成することができます。
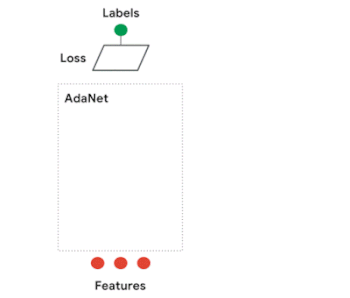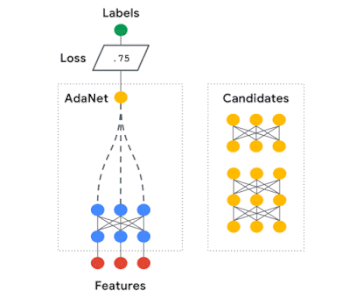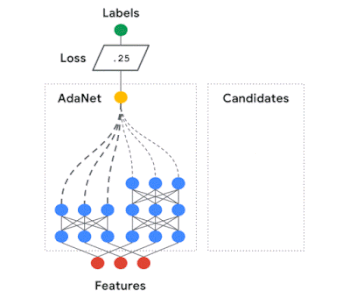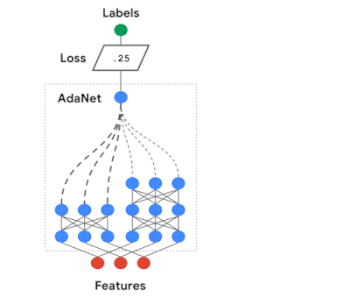
AdaNetはニューラルネットワークのアンサンブルを自動的に構築し、各候補の組み合わせによるアンサンブル損失を測定します。最適な構成が出来るまでサブネットワーク構築と損失測定を繰り返すのです。
高速で使いやすい
AdaNetはTensorFlow Estimatorインターフェイスを実装しており、トレーニング、評価、予測、およびサービスとしてエクスポートする事をカプセル化しており機械学習プログラミングを大幅に簡素化します。TensorFlow Hub modules、TensorFlow Model Analysis、Google CloudのHyperparameter Tunerなどのオープンソースツールと統合されています。分散型トレーニングのサポートにより、トレーニング時間が大幅に短縮され、利用可能なCPUやGPUなどのアクセラレータを増やせば性能は直線的に向上します。
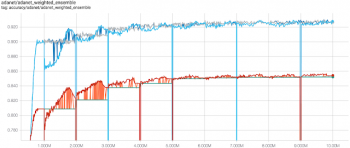
CIFAR-100でのAdaNetの精度(y軸)とトレーニングステップ(x軸)。
青線はトレーニングセットの精度、赤線はテストセットの性能です。新しいサブネットワークが100万ステップずつトレーニングを行い、最終的にアンサンブル学習のパフォーマンスが向上します。灰色と緑の線は、新しいサブネットワークを追加する前のアンサンブルの精度です。
TensorBoardは、トレーニング中にモデルを視覚化するTensorFlowの機能の1つで、サブネットワークのトレーニング、アンサンブルの構成、およびパフォーマンスを監視するために、AdaNetとシームレスに統合されています。AdaNetのトレーニングが終了すると、TensorFlow Servingで展開できるSavedModelがエクスポートされます。
学習保証
ニューラルネットワークのアンサンブルを構築するにはいくつかの課題があります。最適なサブネットワークアーキテクチャとは何でしょうか?同じアーキテクチャを再利用する方が良いのでしょうか?それとも様々なアーキテクチャーを採用し、多様性を優先する事が最善でしょうか?
より多くのパラメータを持つ複雑なサブネットワークの方が、トレーニングデータを使った性能試験ではパフォーマンスが向上する傾向がありますが、複雑さが増しているために学習データに過度に最適化しないように一般化することが難しくなります。
これらの課題は、モデル性能の評価方法が起因となっています。トレーニングセットから更に分離したデータセット(ホールドアウトデータセット)を用いてパフォーマンスを評価する事もできますが、そうすると、ニューラルネットワークのトレーニングに使用できるサンプルの数が減ってしまいます。
代わりに、AdaNetの手法(ICML 2017で発表された「AdaNet: Adaptive Structural Learning of Artificial Neural Networks」)は、トレーニングセットに対するアンサンブルのパフォーマンスと一般化能力のトレードオフを最適化する事を目的とします。
直感的に言えば、アンサンブルの一般化能力に負の影響を与えるよりもアンサンブルの訓練の損失を改善する場合にのみ、サブネットワークを候補に含めます。
これにより、次のことが保証されます。
・アンサンブルの汎化誤差は、その訓練誤差および複雑さによって制限を受けます。
・このトレードオフの最適化を目標とし、この制限が小さくなるようにします。
この目的を最適化することの実際的な利点は、アンサンブルに追加するサブネットワーク候補を選択するためのホールドアウトデータセットの必要がなくなる事がです。これにより、サブネットワークのトレーニングにより多くのトレーニングデータを使用できるという利点があります。詳細については、AdaNetに関するチュートリアルをご覧ください。
拡張可能
研究開発と製品製造の両方場面で役立つAutoMLフレームワークを作成するための鍵は、考えられたデフォルト設定を提供するだけでなく、ユーザーがサブネットワークやモデルの定義を試すことができるようにすることです。その結果、機械学習の研究者、実践者、および愛好家は、tf.layersのような高レベルのTensorFlow APIを使用して、AdaNet adanet.subnetwork.Builderを定義する事ができます。
すでにTensorFlowモデルをシステムに統合しているユーザーは、TensorFlowコードをAdaNetサブネットワークに簡単に変換し、adanet.Estimatorを使用してモデルのパフォーマンスを向上させ、学習保証を得ることができます。AdaNetはサブネットワーク候補が定義された検索スペースを探索し、サブネットワークのアンサンブル方法を学習します。
たとえば、NASNet-A CIFARアーキテクチャのオープンソース実装をサブネットワークに変換したAdaNetによる8回の反復で、CIFAR-10の最先端のスコアを更新しました。更に、私達のAdaNetによるモデルは、より少ないパラメータでこの結果を達成したのです。
| Model | CIFAR-10 Classification Error Rate | Parameters |
| NASNet-A | 2.40% | 27.6M |
| AdaNet | 2.30% | 26.4M |
2018年のZophと共同執筆者によるNASNet-A modelのパフォーマンスとNASNet-Aサブネットワークの組み合わせで学習されたAdaNetモデルのCIFAR-10のパフォーマンス比較
ユーザは、回帰、分類、およびマルチタスク学習の問題を訓練するために、カスタム損失関数をあらかじめ用意したりtf.contrib.estimator.Heads経由でAdaNetの目標の一部として組み込む事ができます。adanet.subnetwork.Generatorクラスを拡張することで、サブネットワーク候補を検索する検索スペースを完全に定義することもできます。これにより、使用可能なハードウェアの性能に基づいて検索スペースを拡大または縮小することができます。サブネットワークの検索スペースは様々なランダムシードを持つ同じサブネットワーク構成を複製するシンプルなものにもできますし、異なるハイパーパラメータの組み合わせを使用して数十のサブネットワークをトレーニングすること、AdaNetに最終アンサンブルに含めるサブネットワークを選択させることなども可能です。
AdaNetのご利用をご希望の方は、Githubのレポジトリをご確認の上、チュートリアル用コラボノートブックをご覧ください。緻密なレイヤーと畳み込みを使用して、いくつかの実例を紹介しました。AdaNetは進行中の研究プロジェクトであり、貴方からの貢献を歓迎します。私たちは、AdaNetがどのように研究コミュニティに役立つかを見てうれしく思います。
謝辞
このプロジェクトは、Corinna Cortes、Mehryar Mohri、Xavi Gonzalvo、Charles Weill、Vitaly Kuznetsov、Scott Yak、Hanna Mazzawiなど、コアチームのメンバーの助力があってこそ可能でした。また、Gus Kristiansen、Galen Chuang、Ghassen Jerfel、Vladimir Macko、Ben Adlam、Scott YangなどGoogleの共同作業者、インターン、インターンにも特別な感謝をします。
3.AdaNet:高速かつ柔軟な学習保証付きでAutoMLをアンサンブルする関連リンク
1)ai.googleblog.com
Introducing AdaNet: Fast and Flexible AutoML with Learning Guarantees
2)github.com
tensorflow/adanet

