
1.2018年のGoogleの研究成果を振り返って(3/6)まとめ
・Googleの2018年のAI関連の研究や成果の振り返り
・コンピュテーショナルフォトグラフィー、アルゴリズム、ソフトウェア
・研究開発の結果から実際の製品として世に出たものまで幅広く紹介
2.2018年のGoogleの研究成果のまとめ
以下、ai.googleblog.comより「Looking Back at Google’s Research Efforts in 2018」の意訳です。久々のJeff Deanによる投稿です。
コンピュテーショナル フォトグラフィー
ここ数年の携帯電話カメラの品質と汎用性の向上は特筆すべき事です。
スマートフォンで使われている各種の物理センサーの改良に負うところもありますが、その大部分はコンピュテーショナル フォトグラフィー(コンピューターで写真を扱う科学技術)の進歩によるものです。
私達の研究チームは新しく研究したテクニックを公開し、GoogleのAndroidおよび一般向けハードウェアチームと緊密に連携し、この研究結果を最新のPixelおよびAndroid携帯電話やその他のデバイスであなたの手に提供します。
2014年に、HDR+を導入しました。これは、カメラが連続したフレームを撮影し、ソフトウェアでフレームを整列させ、それらをソフトウェアでマージする手法です。もともとHDR+が期待されていた効果は、単一の露光で撮影可能なダイナミックレンジ(明るさの範囲)をより広げる事でした。
しかし、このフレームを連続して撮影してからこれらのフレームをコンピューター解析し、処理を実行する手法は、2018年にはカメラの多くの進歩を可能にする一般的なアプローとなりました。例えば、Pixel2ではMotion PhotosやMotion Stillsの拡張現実(Augmented Reality)モードの開発を可能にしました 。
![]()
Google PhotoにアップされたPixel 2のMotion Photos

Motion Stills ARモードの拡張チキンファミリー。
(訳注:現実世界の中にヴァーチャルなものを入れ込むのが拡張現実であり、このヴァーチャルな鶏は地面をちゃんと認識していて、ちゃんと地面の部分を突きます)
今年、私たちのコンピュテーショナル フォトグラフィー研究における主な取り組みの1つは、Night Sightと呼ばれる新しい機能を開発することでした。Night Sightは、Pixelスマートフォン搭載カメラで「暗闇を見る」ことを可能にします。
もちろん、Night Sightは私たちのチームが開発した新しいソフトウェアによるカメラ機能の1つであり、その他にも、機械学習を使用してより良いポートレートモードの撮影を可能にしたり、Super Res Zoomを使用してより遠くを撮影できたり、Top ShotやGoogle Clipsでベストショットを自動で撮影するなど、完璧な写真を撮るための様々な進歩がありました。
![]()
左:iPhone XS、右:Pixel 3 Night Sight
アルゴリズムと理論
アルゴリズムは、Googleシステムのバックボーンであり、Google Trips(Googleの旅行計画作成アプリ)の背後にある経路選択アルゴリズムからGoogleクラウドの一貫したハッシングまで、Googleの全ての製品に適用されます。この1年間、私たちは理論的基礎から応用アルゴリズムまで、そしてグラフマイニングからプライバシー保護計算まで、幅広い分野をカバーするアルゴリズムと理論の研究を続けてきました。
最適化における私たちの研究は、機械学習のための最適化処理から分散型組み合わせ処理の最適化まで広範囲にわたります。前者の分野では、ニューラルネットワークを訓練するための確率的最適化アルゴリズムの収束に関する研究(ICLR 2018最優秀論文賞を受賞)は、一般的な勾配ベースの最適化法(ADAMの変種など)に関する問題を示し、新しい勾配ベースの最適化手法のための強固な基盤を提供しました。
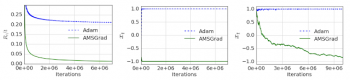
非収束性の例に触発された単純な一次元凸問題の合成例に対するADAMとAMSGRADの性能比較。最初の2つのグラフ(左と中央)はオンライン設定用で、最後のグラフ(右)は確率的設定用です。
分散最適化では、よく研究された組み合わせ最適化問題である巡回問題と通信の複雑さを改善するように努めました。丸め圧縮とコアセットによるグラフのマッチング、劣モジュラ最大化、kコア分解などです。
より応用的な側面として、我々はスケッチを介した大規模な集合被覆問題の解決、そして何兆もの辺を持つグラフの均衡分割と階層クラスタリングを解くためのアルゴリズム的手法を開発しました。オンライン配信サービスに関する私たちの仕事は、WWW’18で最優秀論文賞にノミネートされました。 最後に、Googleのオープンソースの最適化プラットフォームであるOR-toolsは、2018年のMinizinc制約プログラミングコンペティションで4つの金メダルを獲得しました。
アルゴリズム選択理論では、新しいモデルを提案し、再構成の問題と多項ロジットの混合学習を調べました。また、ニューラルネットワークで学習可能な機能とは何であるかと、古典的なオンラインアルゴリズムを改善するために機械学習の診断結果を活用する方法についても研究を行いました。
強力なプライバシー保護を保証する学習テクニックを理解することは、Googleにとって非常に重要です。これに関連して、私達は差分プライバシー(differential privacy)を反復とシャッフリングによってどのように増幅できるかを分析する2つの新しい方法を開発しました。また、ゲームに対して堅牢なインセンティブを意識した学習方法を設計するために、差分プライバシー技法を適用しました。
このような学習技術は、効率的なオンライン市場設計において有望です。市場アルゴリズムの分野におけるGoogleの新しい研究には、広告主が広告オークションにおいて誘因両立性(Incentive Compatibility)をテストできる事(要は広告費に必要以上にお金をかけている感が出ないようにする事)やアプリ内広告の広告更新頻度を最適化するのに役立つ手法も含まれています。
また、リピーテドオークション(Google広告のように同じ商品に対して繰り返し開催するオークション)の最先端の動的メカニズムの境界を押し広げ、将来の予測の欠如や、ノイズの混ざる予測に対して、または異種バイヤーの行動に対して、耐性のある動的オークションを提示し、私たちの研究結果をダブルオークション(売り手と買い手双方が値段を出し合い条件の合う相手と取引を成立させる手法がダブルオークション)にダイナミックに拡張します。
最後に、オンライン最適化およびオンライン学習における耐障害性向上の目的で、トラフィックの急増を伴う確率的入力のための新しいオンライン割り当てアルゴリズム、および破損データに対して耐久性のある新しい強盗アルゴリズム(bandit algorithms)を開発しました。
Software Systems
ソフトウェアシステムに関する私たちの研究の大部分は、機械学習モデルの構築、特にTensorFlowに関するものです。 たとえば、TensorFlow 1.0の動的制御フローの設計と実装について発表しました。
私たちの最近の研究のいくつかは、私たちがMesh TensorFlowと呼ぶシステムを導入しています。それは、モデルの並列性、時には何十億ものパラメータで大規模分散計算を簡単に指定することを可能にします。 別の例として、TensorFlowを使用した大規模なランク付けを可能にするディープニューラルランク付けライブラリをリリースしました。
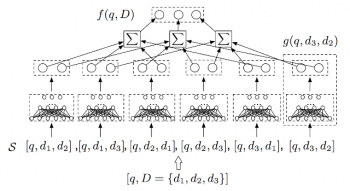
TFランキングライブラリは、マルチアイテムスコアリングアーキテクチャをサポートしています。これは、従来のシングルアイテムスコアリングの拡張です。
また、backpropagationや、GPUやTPUアクセラレータでサポートされるNumPyの亜種であるJAXもリリースしました。JAXはTensorFlowの一部ではありませんが、同じ基本的なソフトウェアインフラストラクチャ(XLAなど)の一部を利用しており、そのアイデアとアルゴリズムの一部はTensorFlowプロジェクトに役立ちます。最後に、機械学習のセキュリティとプライバシーなど、AIシステムにおける安全性とプライバシーのためのオープンソースフレームワークの開発に関する研究を続け、CleverHansやTensorFlow Privacyなどのフレームワークを公開しました。
私たちにとってもう一つの重要な研究の方向性は、多くの場面の様々な状況でソフトウェアシステムにMLを適用することです。たとえば、階層モデルを使用してメモリアクセスパターンの学習に貢献し、デバイス設計の改良に繋がりました。また、学習した索引をデータベースシステムやストレージシステムの従来の索引構造に置き換えるためにどのように使用できるかについても調査を続けました。私が昨年書いたように、コンピューターシステムに機械学習を適用するという点で、まだ表面的な部分しか実現できてないと信じています。
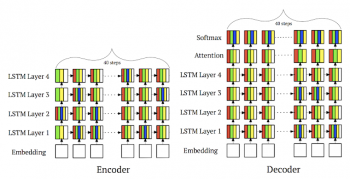
階層プランナーによるNMT(4層)モデルの配置。
白はCPUを表し、4色はそれぞれGPUの1つを表します。 すべてのレイヤのすべてのステップが複数のGPUにまたがって割り当てられていることに注目してください。この配置は、人間の専門家によって生成された配置よりも53.7%高速です。
2018年、GoogleのProject Zeroチームや他の人々との共同作業により、現代のコンピュータプロセッサにおける新しい深刻なセキュリティ脆弱性であるSpectreおよびMeltdownについて学びました。これらおよび関連する脆弱性により、コンピュータアーキテクチャの研究者はかなり忙しくなります。
CPU動作をモデル化するための継続的な取り組みの中で、当社のCompiler Researchチームは、マシン命令の待ち時間とポートプレッシャーを測定するためのツールをLLVMに統合し、より良いコンパイル決定を可能にしました。
Googleの製品、クラウド、および機械学習モデルに関する推論は、コンピューティング、ストレージ、およびネットワーキングのための大規模で信頼性が高く効率的な技術インフラを提供する能力に大きく依存しています。
昨年のいくつかの研究のハイライトは、Softwareで定義された広域ネットワーク経由でインフラを作動させる事や、多くのストレージシステム(BigTable、Spanner、Google Spreadsheetsなど)に格納されている、さまざまなファイルベースの形式で格納されているデータに対してSQLクエリを実行する、スタンドアロンのフェデレーションクエリ処理プラットフォームなどです。また、Google社内でのコードレビューの広範な使用、Googleでのコードレビューの背後にある動機、現在の慣行、および開発者の満足度と課題について調査しました。
コンテンツホスティングなどの大規模Webサービスを実行するには、動的環境における安定性を備えたロードバランシングが必要です。私たちは各サーバーの最大負荷を確実に証明できる一貫したハッシュスキームを開発し、それをGoogle Cloud Pub / Subのクラウドユーザーに展開しました。以前のバージョンの論文を公開した後、オンライン動画関連サービスを提供するVimeoのエンジニアはその論文を見つけてhaproxyで実装および公開し、Vimeoの負荷分散プロジェクトに使用しました。結果は劇的でした。これらのアルゴリズムのアイデアを適用することで、キャッシュの帯域幅を約8分の1に減らし、スケーリングのボトルネックを解消することができました。
(2018年のGoogleの研究成果を振り返って(2/6)からの続きです)
(2018年のGoogleの研究成果を振り返って(4/6)に続きます)
3.2018年のGoogleの研究成果を振り返って(3/6)関連リンク
1)ai.googleblog.com
Looking Back at Google’s Research Efforts in 2018

コメント