
1.オンデバイス用に機械学習モデルを圧縮するLearn2Compressまとめ
・既存の学習済みモデルをスマホ用に圧縮してくれるLearn2Compressが発表
・予測精度は少し下がるが、サイズ、実行速度、消費電力を大幅に改良
・近日中にML Kitと言うクラウドサービスの中で利用可能になる予定
2.Learn2Compressとは?
ディープラーニングを使った人工知能をアプリケーションで実行する際、沢山の計算機パワーやメモリを必要とする事が多い。この事は、パソコンより性能が制限されているスマートフォンやIoT機器で人工知能を実行させる時に障害となる。
「On device」、つまりパソコンより性能が制限されたスマホやIoTデバイスで人工知能を実施させると、個人情報関連規制を考慮する必要がなく、ネット接続がなくてもどこでも実行できるなどの利点がある。オンデバイスな人工知能には、MoblieNetやProjectNetsなど先行プロジェクトが存在し、性能が制限された環境でも動作させる事が出来るように最適化された機械学習モデルが提供されている。しかし、もし、貴方が貴方自身がカスタマイズした機械学習モデルをオンデバイスでモバイルアプリケーションとして動かしたいとしたらどうだろうか?
先日、Googleは、Googleの主催する開発者向けイベントGoogle I/Oにて、ML Kitをアナウンスした。ML Kitの主要機能の1つは、Learn2Compress技術により、既存の学習モデルを自動で圧縮できる事である。Learn2Compressは、貴方が作成したカスタムな機械学習モデルをTensorFlow Liteで効率的に動かす事を可能にする。開発者は自身が作成した機械学習モデルが問題なくスマホ上で動作するか、メモリや速度に関して心配する必要はない。Learn2Compressは当初は少数のデベロッパーのみに公開されるが、数か月後にはもっと広く公開される予定である。興味がある人は末尾のFirebase featuresページよりサインアップする事ができる。
3.Learn2Compressはどのように働くのか?
Learn2CompressはProjectionNetのような先行プロジェクトで紹介された手法をより一般化し、ニューラルネットワークモデルを圧縮するための最先端技術を組み込んでいる。ユーザーが提供するパソコン動作用の大規模な学習済モデルを入力として受け取り、トレーニングと最適化を実行し、サイズを小さくし、メモリ効率を改良し、電力効率を高くし、高速ですぐに使えるオンデバイスモデルを自動生成する。圧縮した事により性能の劣化は最小限に抑えられる。

具体的には、下記のテクニックが用いられている。
1)切り取り
ニューラルネットワークモデルからあまり重要でない重みや紐づけを削除し、モデルサイズを縮小させる。この手法はオンデバイス用にモデルを再作成する際は非常に有効で、性能の低下をオリジナルの97%に抑えたまま、サイズを半分にする事ができる。
2)量子化
桁数の多い浮動小数点演算を8ビット固定の小数点演算に変更する。この手法も速度及び消費電力、サイズの削減に結びつく。
3)ジョイントトレーニング
ユーザが提供するオリジナルのPC用モデルを教師、圧縮したモデルを生徒として、同じ入力データを使用して出力結果を比べられるように接続する。同時に複数の異なった生徒モデルを学習させる事もできる。
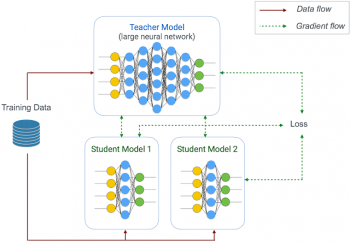
4.Learn2Compressはどのくらい有効なのか?
Learn2Compressのデモのために、既存の画像認識や自然言語解析のモデルである、MobileNets, NASNet, Inception, ProjectionNetと圧縮モデルの比較を行った。
ImageNetを使った画像分類では、Inception v3ベースのモデルの1/22サイズ、MobileNet v1ベースのモデルの1/4サイズに圧縮する事が出来、画像予測の性能劣化は4.6-7%程度であった。CIFAR-10を使った画像分類では、ジョイントトレーニングを使い、3つのモデルを同時に学習させたが、学習に必要な時間は1つのモデルを学習させる時間より10%増えただけであった。出来たモデルは1/94のサイズで27倍速く、1/36のコストで、正答率は90-95%の結果となった。
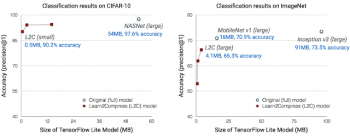
既存の作りこまれたモデルでこのように優れた結果を出せたため、ユーザーが作ったカスタムモデルではもっと劇的なパフォーマンス改善が出来るのではないかとGoogleは考えている。例えば、ある釣りアプリ用の機械学習モデルは80MBのサイズで91.8%の正答率であったが、Learn2Compressでサイズを5MB以下に抑え、ほぼ同等の正答率にする事ができた。幾つかのケースでは、Learn2Compressによって圧縮されたモデルは圧縮時により良い正則化が行われるため、元のモデルより高い正答率を出す場合もあった。
Googleは、Learn2Compressの改良を続け、画像分類に留まらず様々な分野に拡張する事を目指す。近い将来、ML Kitはクラウドサービスとして提供され、広く一般に利用できるようになる。開発者は、自社のオンデバイス機械学習モデルを自動的に最適化し、開発者がアプリケーションや使い勝手の向上に集中できるようになる事を願っている。
5.オンデバイス用に機械学習モデルを圧縮するLearn2Compress感想
今回、比較実験したMobileNetはv1で、既にMobileNet v2が発表されているので最新版に比べると性能差は縮まっているかもしれませんが、それにしても凄い圧縮効率です。予測性能と速度やサイズはトレードオフの関係にあるし、スマホのハードウェアの進化も早いので、Learn2Compressが今後どこまで広く使われるようになるかはわかりません。しかし、モバイルファースト、PCよりスマホでのアクセスを最初に考えるべきと言われる現在のWeb業界では、比較的簡単にスマホ用に最適化できるLearn2Compressのような手段がある事は知っておくべきなのだろうな、と思います。
6.オンデバイス用に機械学習モデルを圧縮するLearn2Compress関連リンク
1)ai.googleblog.com
Custom On-Device ML Models with Learn2Compress
2)docs.google.com
Sign up for new Firebase features (Google I/O ’18)

コメント