
1.Fluid Annotation:機械学習を用いて画像に高速にラベル付けする探索的インタフェースまとめ
・機械学習を用いて画像に画素単位でラベル付けする作業を容易にする手法が発表
・機械学習が画像をあらかじめ領域に分けてくれるので人間はそれを元にラベル付けに集中できる
・現状は領域選択が人間の手動より甘いが効率は3倍になるという
2.Fluid Annotation(流動的注釈)とは?
以下、ai.googleblog.comより「Fluid Annotation: An Exploratory Machine Learning–Powered Interface for Faster Image Annotation」の意訳です。
TensorFlow Object Detection APIで実装されているような近代的なディープラーニングベースの画像を扱う人工知能のパフォーマンスは、ラベル付きのトレーニング画像データセットをどれだけ大量に用意できるかに依存します。
Open Imagesなどのデータセットは日に日に大きくなっていますが、高品質のトレーニングデータを入手することは、画像を扱う人工知能の開発の際に大きな困難となる事が多いです。これは、特に、自動運転、ロボティクス、および画像検索などのアプリケーションで使用されるセマンティックセグメンテーション(境界ボックス単位ではなく画素単位で画像内の物体の領域を認識する事)で画像分類や画像認識を行う人工知能の場合に当てはまります。
実際、従来の手動ラベリングツールでは、画像内の各オブジェクトの輪郭を慎重にクリックしてその物体が何であるかラベル(注釈)を付ける必要がありました。退屈です。COCO-Stuffデータセットの画像一枚にラベルを付けるには19分かかりますが、もし、データセット全体をラベル付けするとなると、、、53,000時間以上です!

COCOデータセットの画像の例(左)とその画素単位のセマンティックラベル(右)
画像のクレジット:Florida Memory
論文「Fluid Annotation: A Human-Machine Collaboration Interface for Full Image Annotation」は、2018年のACMマルチメディア会議のBrave New Ideasトラックで発表される予定です。画像内のすべてのオブジェクトと背景部分に対して、領域とラベルを容易に作成できるように機械学習を用いた使い勝手の良いインターフェイスを提供し、ラベル付きデータセットの作成を3倍に加速します。
Fluid Annotationは、強力なセマンティックセグメンテーションを表示する事から開始されます。人間の注釈者は使い勝手の良いユーザーインターフェイスを用いて機械の支援の元に注釈付与作業を行う事ができます。
(つまり、最初に機械学習が画像内の領域を認識してピックアップし、人間はその領域が何であるか注釈をつけるという手順で作業を進めるので、人間がチマチマと領域を選択する必要がなくなり作業がスピードアップするのです)
私たちのインターフェースは、注釈をつける人が何を修正するか、どの順番で行うかを選択できるようにし、人工知能がまだ知らない未知のものに対して人間が効率的に注釈を付与する事に集中できるようにします。
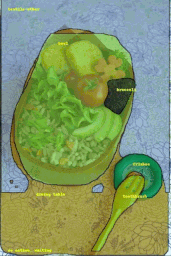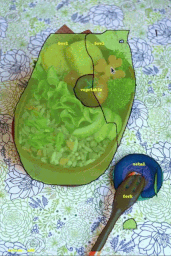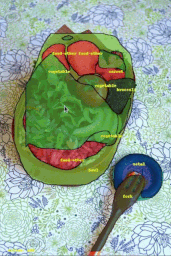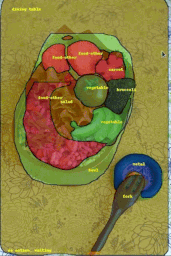
COCOデータセットの画像に対してFluid Annotationインタフェースを実行しているデモ
画像のクレジット:gamene
より正確には、画像に注釈を付けるために、事前に訓練されたセマンティックセグメンテーションモデル(Mask-RCNN)を用います。これはクラスラベルと信頼スコアを用いて画像内に約1000個のセグメント(領域)を生成します。最も信頼度の高いセグメントは、注釈作業者に提示されるラベリングを初期化するために使用されます。
その後、注釈作業者は、
(1)人工知能が生成した既存のセグメントのラベルをリストから選んで変更することができます。
(2)セグメントとして認識されていないオブジェクトを認識させるためにセグメントを追加する事ができます。人工知能は、有望なセグメントを順番に表示するので、それをベースに注釈者がスクロールして最良のセグメントを選択することができます。
(3)既存のセグメントを削除する事ができます。
(4)重複するセグメントの順番を変更することができます。
このインターフェースのより良い使い心地を体験するには、ページ下部のリンクからデモを試してみてください(デスクトップ版のブラウザのみで利用できます)。

3つのCOCO画像に対する従来の手動ラベリングツール(中段)とFluid Annotation(右)を使用した注釈の比較。手動のラベリングツールを使用する方がオブジェクトの境界はしばしばより正確ですが、注釈の違いの最大の原因は、人間の注釈者が提案されたオブジェクトクラスが正確な物であっても同意しないケースが多いためです。
画像クレジット:sneaka(上段)、Dan Hurt(中段)、Melodie Mesiano(下段)。
Fluid Annotation(流動的注釈)は、画像に対する注釈をより迅速かつ容易に実現するための最初の探索的ステップです。今後予定されている作業では、オブジェクト境界の認識精度を改善し、より多くのマシンインテリジェンスを活用することでインターフェイスを高速化し、最終的に効率的なデータ収集が最も必要とされる今まで機械学習が見た事がないオブジェクトを効率的に処理できるようにインターフェイスを拡張する予定です。
謝辞
この作業は、Misha Andrilukaと共同で行われました。Fluid Annotationのデモを作成してくれたChristine Sugrueに感謝します。また、貴重なご意見をいただいたAnna UkhanovaとDamien Henryにも感謝します。
3.Fluid Annotation:機械学習を用いて画像に高速にラベル付けする探索的インタフェース関連リンク
1)ai.googleblog.com
Fluid Annotation: An Exploratory Machine Learning–Powered Interface for Faster Image Annotation
2)fluidann.appspot.com
This is the demo of our Fluid Annotation paper
3)github.com
The COCO-Stuff dataset

訳注)COCO-Stuffデータセットは「164K complex images from COCO」、つまり164,000imagesなので1枚19分とすると3,116,000分、時間になおすと51,933時間。仮に165,000imagesとしても52,250時間なので53,000には届かないのに原文は「over 53k hours!」なので、微妙な所ですがおそらく、下記2つを意識した表現と思います。相当悩んでしまった・・・
英語圏では何故かとても人気のある表現
日本語圏ではとても人気のある表現