
1.BERT:自然言語処理のための最先端の事前トレーニングまとめ
・自然言語処理は学習に使えるデータが少ない事が問題になっている
・言語構造を事前トレーニングさせる事によりデータ不足問題を大きく改善できる
・双方向型の事前トレーニングであるBERTは従来の事前トレーニングモデルを圧倒
2.BERTとは?
以下、ai.googleblog.comより「Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing」の意訳です。元記事の投稿はNovember 2, 2018、Jacob DevlinさんとMing-Wei Changさんです。記事中で言及されているSquad v1.1は今年1月に「人工知能(AI)が読解力テストで世界で初めて人間を凌駕」とニュースになった有名な読解力テストなのですが、当時のスコアを圧倒的に上回る性能を持ったモデルが1年もたたずにオープンソース化されるとは本当に凄まじい進化です。ちなみにSquad自体も2.0に更新されており、Squad2.0では人間が一位を奪還しています。一般向けにもう少しわかりやすいBERTの記事はニューヨークタイムスのこちらの記事です。
2020年4月追記)本文中には「BERTはアイディアとしては昔から存在していたのですが、実現はハードウェアの進歩によってはじめて可能になった」と書いてありますが、2020年4月現在、わずか76分でBERTをトレーニング出来るくらいテクノロジーが進化しています。
自然言語処理(NLP)における最大の課題の1つは、トレーニングデータが不足していることです。NLPは多くの異なるタスクを持つ多様な分野であるため、ほとんどのタスクは固有のデータセットを必要としますが、それらの固有のデータセットは数千または数十万程度しかラベル付きデータは含まれていません。しかし、現代のディープラーニングベースのNLPモデルは、より沢山の、数百万~数十億のラベル付きデータセットで学習させた場合に品質の改善が見られます。
研究者は、このようなデータ量のギャップを埋めるために、膨大な量のウェブ上のラベルなしテキストを使用して、汎用言語表現モデルを訓練(事前トレーニングと呼ばれます)するためのさまざまな手法を開発しました。事前に訓練されたモデルは、質問回答や感情分析などの小規模のNLPタスクで微調整することができ、モデルをゼロから訓練するよりも大幅に精度を向上する事ができます。
今週、トランスフォーマーを用いたBidirectional Encoder Representations(BERT)と呼ばれるNLPを事前トレーニングする新しいテクニックを公開しました。このリリースでは、世界の誰もが、単一のCloud TPUで約30分で、または1つのGPUを使用して数時間で、独自の最新の質問回答システム(またはその他のさまざまな自然言語に関するモデル)を訓練することができます。
このリリースには、TensorFlowの上に構築されたソースコードと、事前にトレーニングされた多言語の表現モデルが含まれています。BERTに関する論文内では、デモのため、非常に人気のあるスタンフォードの質問回答データセット(Squad v1.1)を含む11のNLPタスクで最高スコアを更新しています。
BERTは何が違うのですか?
BERTは、文脈表現を事前トレーニングに関する最近の研究、Semi-supervised Sequence Learning、Generative Pre-Training、ELMo、およびULMFitなどをベースとして構築されています。しかし、これらの以前のモデルとは異なり、BERTは、平易なテキストコーパス(この場合はWikipedia)のみを使用して事前にトレーニングされた、最初のdeeply bidirectional(深く双方向)な、教師なしの言語表現です。これにはどんな違いがあるのでしょうか?事前トレーニングされた表現は、context-freeモデルまたはcontextualモデルのいずれかであり、contextualモデルは、単方向または双方向のいずれかになります。
word2vecやGloVeのようなcontext-freeモデルは、文脈を無視(context-free)して単語単位にembeddingを生成します。例えば、「bank(銀行)」という言葉は「bank account(銀行口座)」でも「bank of the river(川の土手)」でも、context-freeなために両文とも同じ文章表現になってしまいます。
それに対して、文脈(contextual)モデルは、文中の他の単語も考慮してモデルを生成します。たとえば、「I accessed the bank account.」という文章では、一方向のcontextualモデルでは単語より前にある「I accessed the」の部分を用いて「bank」を表現します。後半の「account」の部分は使われません。
しかし、BERT(Bidirectional Encoder Representations)は双方向(Bidirectional)であるため「I accessed the … account.」という前後の文章を使用して「bank」を表現します。ディープニューラルネットワークの最下層から始める事により、それを深く双方向にできるのです。
BERTのニューラルネットワークアーキテクチャを従来の最先端のコンテキスト事前トレーニング方法と比較した図は以下です。矢印は、あるレイヤーから次のレイヤーへの情報フローを示します。上部の緑色のボックスは、各入力単語の最終的な文脈表現を表します。
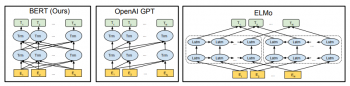
BERTは双方向性、OpenAI GPTは単方向、ELMoは浅い双方向です。
強力な双方向モデル
双方向モデルが非常に強力であるならば、何故、以前から行われていなかったのでしょうか?理由を理解するために、単方向モデルは、文中の前の単語に基づいて訓練させる事で効率的に各単語を予測できていると考えてください。しかし、双方向モデルを訓練するために各単語を前後の単語だけを用いて訓練させる事は不可能です。何故なら、多層モデルでは間接的に「自分自身を見る」事によって予測できてしまうからです。
この問題を解決するために、入力された文章の単語の一部をマスクし、マスクされた単語を予測するために各単語を双方向に用います。
Input : The man want to the [MASK1]. He bought a [MASK2] of milk.
Labels : [MASK1] = store; [MASK2] = gallon;
このアイディアは非常に長い間試行錯誤されてきましたが、BERTはディープニューラルネットワークの事前トレーニングにこのアイディアを上手に適用できた初めての成功事例です。
BERTはまた、任意の言語資料から生成することができる非常に簡単なタスクを用いて事前訓練することによって、文章の前後関係をモデル化することも学べます。例えば、以下のようにAとBの2つの文が与えられた時、BはAの後に来る文章でしょうか?それとも、ただのランダムな文章なのでしょうか?
文章A : The man went to he store.(その男は店に行った)
文章B : He bought a gallon of milk.(彼はミルクを一ガロン買った)
答え : InNextSentence(AとBは連続する文章です)
文章A : The man went to he store.(その男は店に行った)
文章B : Penguins are flightless.(ペンギンは飛べない)
答え : NotNextSentence(AとBは連続する文章ではありません)
クラウドTPUでBERTをトレーニングする
これまで説明してきた事を読むと、かなり簡単な事に思えてくるかもしれません。何故、こんなに簡単に上手くいったのでしょうか?クラウドTPUです。私達はクラウドTPUを用いて、素早く実験、デバッグ、チューニングをすることができました。クラウドTPUは、BERTを既存の事前トレーニングテクニックを超えて進化させることに重要な貢献をしました。2017年にGoogleの研究者によって開発されたTransformerモデルアーキテクチャも、BERTを成功させるために必要な基盤でした。Transformerは、tensor2tensorライブラリと共にオープンソース版もリリースされています。
BERTの成果
パフォーマンスを評価するため、BERTを他の最先端のNLPシステムと比較しました。重要なことは、BERTは個々のベンチマークテスト用に固有のチューニングをほとんど行わずに素晴らしい成果を達成した事です。読解力を試すSQuad v1.1では、BERTはF1スコア93.2(精度の基準)を達成し、従来の人工知能が出した最高のスコアである91.6や人間が記録した最高スコアである91.2を上回りました。
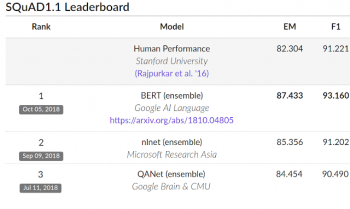
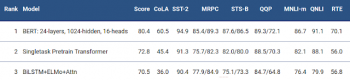
また、BERTは、非常に難しいベンチマークテストであるGLUEの9つの多様なNatural Language Understanding(NLU)タスクで、最高スコアを7.6%更新しました。これらの作業における人間がラベル付けした訓練データの量は2,500~400,000サンプルであり、BERTは9つ全てのタスクで精度を大幅に改善しました。
BERTを使ってみる
私たちが公開したモデルは、数時間で多種多様なNLPタスク用にチューニングできます。オープンソースとしてリリースされたBERTには、自分自身で事前トレーニングを実行するためのコードも含まれていますが、BERTを使用しているNLP研究者の大半は、自分自身でモデルを最初からトレーニングする必要はないと考えています。本日リリースしたBERTモデルは英語版のみですが、近い将来にさまざまな言語用に事前にトレーニングされたモデルをリリースしたいと考えています。
オープンソースのTensorFlowの実装と、事前に訓練されたBERTモデルは下部のリンクにあります。また、ノートブック「BERT FineTuning with Cloud TPUs」でColabからBERTを使用することもできます。BERTの詳細については、「BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding」という論文で確認する事もできます。
3.BERT:自然言語処理のための最先端の事前トレーニング関連リンク
1)ai.googleblog.com
Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
2)arxiv.org
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
3)github.com
google-research/bert
4)colab.sandbox.google.com
BERT FineTuning with Cloud TPUs.
