
1.2018年のGoogleの研究成果を振り返って(2/6)まとめ
・Googleの2018年のAI関連の研究や成果の振り返り
・量子コンピューターと自然言語理解と知覚について
・研究開発の結果から実際の製品として世に出たものまで幅広く紹介
2.2018年のGoogleの研究成果のまとめ
以下、ai.googleblog.comより「Looking Back at Google’s Research Efforts in 2018」の意訳です。久々のJeff Deanによる投稿です。
量子コンピューティング
量子コンピューティングは、古典的なコンピュータでは解決できない困難な問題を解決する能力を約束する、新しいパラダイムです。私たちは過去数年間この分野で積極的に研究を進めてきました。そして少なくとも一つの問題(いわゆる量子超越性)を証明する競争の先頭集団に位置していると信じています。この問題は量子コンピューティングの分水嶺となるでしょう。
2018年、私たちは、量子超越性を証明するために量子コンピュータで取り組むことができる問題の規模を拡大する新しい72量子ビット量子計算装置であるBristleconeの開発を含む、多くのエキサイティングな新しい成果を生み出しました。

サンタバーバラの量子AIラボで研究者のMarissa GiustinaによってインストールされるBristleconeチップ
また、量子コンピュータ用のオープンソースプログラミングフレームワークであるCirqをリリースし、量子コンピュータをニューラルネットワークにどのように使用できるかを調査しました。
最後に、我々は量子プロセッサにおける性能変動を理解するための我々の経験と技術を共有し、そして量子コンピュータがニューラルネットワークのための計算基板としてどのように有用であるかについてのいくつかの考えを共有しました。私たちは、2019年に量子コンピューティング分野で素晴らしい成果を期待しています!
自然言語理解
Googleにおける自然言語研究は2018年はエキサイティングなものとなり、基礎研究だけでなく製品への応用もありました。2017年から引き続きトランスフォーマーが改善され、その結果、ユニバーサルトランスフォーマーと呼ばれる新しいパラレルインタイムバージョンのモデルが生まれました。これは、翻訳や言語推論を含む多数の自然言語タスクで大きな効果を発揮します。
また、プレーンテキストコーパスのみを使用して事前トレーニングするBERTも開発しました。事前トレーニング後、転移学習を用いてさまざまな自然言語タスクを実行する事ができます。
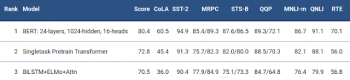
BERTは非常に困難なGLUEベンチマーク(9つの多様な自然言語理解タスクのセット)で、最先端技術のスコアを7.6%向上させました。
Smart ComposeとDuplex(前述)を実現するためにさまざまな調査チームと共同で作業することに加えて、Googleアシスタントがすべてのユーザーと自然に会話できるようにするためにGoogleアシスタントを複数言語に同時に対応できるようにしました。
知覚
私たちの知覚研究は、コンピュータが画像、音声、音楽、ビデオを理解することを可能にし、画像キャプチャ、圧縮、処理、創造的表現、そして拡張現実(AR)のためのより強力なツールを提供するという難しい問題に取り組んでいます。
2018年、我々の技術により、ユーザーやペットなど、ユーザーが最も気にかけているコンテンツを整理するためにGoogleフォトの機能を向上させました。
Google LensとGoogle アシスタントはリアルタイムで質問に答える事が出来るので、ユーザーは動物や植物など自然界について調べ、Google ImagesでLensを使ってより多くのことができるようになりました。Google AIの使命の重要な側面は、他の多くの人達が私たちのテクノロジから恩恵を受けることができるようにすることです。今年、Google APIの一部は機能向上と土台構築で大きな進歩を遂げました。
例としては、Cloud ML APIのビジョンおよびビデオの改善された新機能、およびMLキットによる顔関連のオンデバイスの要素があります。
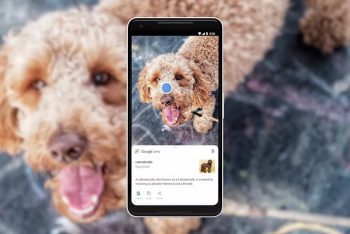
Google Lensはあなたがあなたの周りの世界についてもっと学ぶのを助けることができます。 ここでは、レンズはこの犬の品種を識別しています。
2018年、Googleの学術研究への貢献には、ステレオ拡大(stereo magnification)などの、3Dシーン理解のためのディープラーニングの進歩が含まれていました。これは新しいフォトリアリスティックなビューを合成することを可能にします。画像やビデオの理解を深めるための継続的な研究により、ユーザーは写真、YouTube、検索などのGoogleサービスで画像やビデオを検索、整理、拡張、改善することができます。
2018年の注目すべき進歩には、関節姿勢の推定や人物が写っている箇所を瞬時に切り出すための高速ボトムアップモデルが含まれています。複雑な動きを視覚化するシステム、人と物の間にある空間的関係をモデル化するシステム、そして3D畳み込みに基づくビデオアクション認識の改良など。
音声関係では、セマンティックな音声特徴表現の教師なし学習と、より人間らしく表現力豊かに聞こえる音声合成のための大幅な改善手法を提案しました。マルチモーダル知覚(視覚や聴覚を含めた複数の手段でコミュニケーションをとる事)はますます重要な研究トピックです。
Looking to Listenはビデオの視覚的および聴覚的な変化を組み合わせて、ビデオ内の希望する話者の発声を分離して強調する事ができる技術です。この技術は、特に複数の人が話しているような状況で、スピーチの強調や認識、ビデオ会議から補聴器の改良に至るまで、さまざまなアプリケーションをサポートできます。
リソースに制約のあるプラットフォームで知覚を可能にすることはますます重要になっています。 MobileNetV2はGoogleの次世代モバイルコンピュータビジョンモデルであり、MobileNetは学術界や産業界で広く使用されています。
MorphNetは、ディープニューラルネットワークの構造を最適化する効率的な手法を提案します。これにより、計算機パワーの制約を尊重しながら、画像および音声モデルの性能を全面的に向上させる事ができます。そして、モバイルネットワークアーキテクチャの自動生成に関する最近の研究は、さらに高い性能が可能であることを実証しています。
(2018年のGoogleの研究成果を振り返って(1/6)からの続きです)
(2018年のGoogleの研究成果を振り返って(3/6)に続きます)
3.2018年のGoogleの研究成果を振り返って(2/6)関連リンク
1)ai.googleblog.com
Looking Back at Google’s Research Efforts in 2018
2)openaccess.thecvf.com
MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks
3)arxiv.org
Stereo Magnification: Learning View Synthesis using Multiplane Images
