
1.2018年のGoogleの研究成果を振り返って(1/6)まとめ
・Googleの2018年のAI関連の研究や成果の振り返り
・まずは倫理原則とAI、社会的利益のためのAI、アシスタントテクノロジー
・原理原則の決定と「ユーザーがより早くより効果的に物事を成し遂げるのを助ける」ための技術
2.2018年のGoogleの研究成果のまとめ
以下、ai.googleblog.comより「Looking Back at Google’s Research Efforts in 2018」の意訳です。久々のJeff Deanによる投稿です。
Googleの研究チームにとって2018年はエキサイティングな年であり、さまざまな方法で技術を進化させました。
コンピュータサイエンスの基礎研究や出版物、Googleにとって新しい分野(ヘルスケアやロボットなど)への進出と応用、オープンソースソフトウェアへの貢献、Googleの製品チームとのと強力なコラボレーション、これらは全て、有用なツールやサービスの提供を目的としています。以下では、2018年からの取り組みのほんの一部に焦点を当て紹介します。私達は新たな年に達成される事を楽しみにしています。より包括的な概要については、2018年の私たちのPublication databaseを参照してください。
倫理原則とAI
ここ数年、私たちはAIの大きな進歩と、AIがGoogle製品を改良し、何十億ものユーザーの日常生活に良い影響を与える事を目の当たりにしてきました。AIに携わる私達にとって、AIが世界で良い事に使われる力である事と、AIが倫理的に社会に有益な問題に適用されるかどうかは深く気にかかる事です。
2018年は、Google AIの原則を発表しました。これは、実装に関する技術的な推奨事項をまとめた一連の「責任あるAIの実践(responsible AI practices)」でサポートされています。これらを組み合わせることで、私たちがAIの独自の開発を評価するためのフレームワークを提供します。他の組織もこれらの原則を使用して自分たちの思考を形作ることができます。
この分野は急速に進化しているため、「不公平な偏りを防止する事、隠れた偏りを増幅させない事」や「AIがどうしてそのように動作したのか人々に対して説明責任を負う事」などのいくつかの原則も、機械学習における公平性やモデルの解釈可能性などの新しい研究の発展とともに変更し改善していまきす。
この研究は、Google翻訳でジェンダーの偏りを減らした私たちの実装のように、製品をより包括的で偏りの少ないものにするための進歩や挑戦に繋がります。そしてこれは、包括的な画像データセットとモデルの探査に繋がり、コンピュータが世界中の多様な文化を画像から認識して有益な作業を行う事を可能にします。更に、この作業により、Machine Learning Crash CourseのFairness Moduleを使用して、より幅広い研究コミュニティとベストプラクティスを共有することができます。
社会的利益のためのAI
AIが社会的および社会的に重要な多くの分野に劇的な影響を与える可能性は明らかです。 実世界の問題にAIをどのように適用できるかの一例は、洪水予測に関する私たちの研究です。グーグルの多くのチームと共同して、この調査は洪水の起こりそうな範囲と範囲について正確でタイムリーにきめ細かい情報を提供し、洪水が発生しやすい地域の人々が自分自身と自分の財産を保護するための最善の方法についてより適切な決定を下せるようにする事をることを目指しました。
2つ目の例は、AIによる余震予測に関する研究です。ここでは、機械学習(ML)モデルが従来の物理ベースのモデルよりもはるかに正確に余震位置を予測できることを示しました。おそらく更に重要な事は、MLモデルが解釈可能になるように設計されているので、科学者たちは余震の振る舞いについて新しい発見をすることができ、より正確な予測だけでなく新しいレベルの理解につながった事です。
また、TensorFlowのようなオープンソースソフトウェアを使い、時にはGoogle内部の研究者やエンジニアと共同で、沢山の社外の方たちと様々なさまざまな科学的問題や社会的問題に取り組みました。
ザトウクジラの呼び声を識別するための畳み込みニューラルネットワークの使用、新しい太陽系外惑星の検出、病気のキャッサバの識別などがあります。
この分野での創造的な活動を促進するために、Google.orgと共同で、Google AI for Social Impact Challengeを発表しました。これにより、個人および組織は総額2500万ドルの基金から助成金を受ける事ができ、更に大きな潜在的な社会的影響を伴うプロジェクトのために働いているGoogleの研究者、エンジニア、その他の専門家からの指導とアドバイスを受ける事ができます。
アシスタントテクノロジー
私たちの研究の多くは、「ユーザーがより早くより効果的に物事を成し遂げるのを助ける」事に集中しており、そのためにMLとコンピュータサイエンスを使いました。多くの場合、これらの研究成果は様々な製品チームがそれぞれの製品の機能や設定に採用し公開されます。
その一例が、Google Duplexです。自然言語と対話の理解、音声認識、文章読み上げ、ユーザーの理解、効果的なUIデザインのすべてを組み合わせました。これにより、ユーザーは「今日の午後4時にヘアカットを予約できますか?」とアシスタントに依頼する事ができ、バーチャルエージェントがあなたの代わりに電話でやり取りして必要な詳細情報を処理し実際に電話で予約を行います。
他の例としては、Smart Compose(予測モデルを使用して電子メールの作成を迅速かつ容易にするために適切な返信文案の提案を行うツール)やSound Search(Now Playing機能に基づいて実装されたテクノロジで、現在演奏されている曲が何であるのかを素早く正確に検出可能)があります。
さらに、AndroidのSmart Linkify機能では、スマートフォンに格納されているMLモデルを使用して、選択しているテキストの種類を理解することで、携帯電話の画面に表示されるさまざまな種類のテキストをより便利にする方法を示します。例えば、住所が検出されたらその住所の部分をタップするとGoogleMapが起動するようなリンクやショートカットを提供できます。
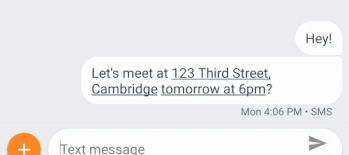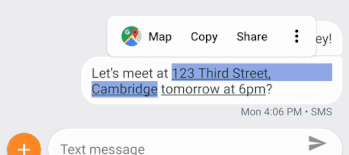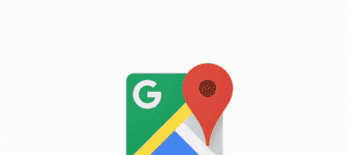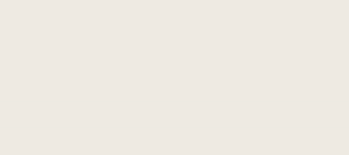
私たちの研究の重要な焦点は、同じ概念やアイデアを表現する非常に異なる方法が使用されている場合でも、グーグルアシスタントのような製品がより多くの言語をサポートし、意味の類似性をよりよく理解できるようにすることです。このような新しい製品機能の基礎となったのは、利用可能なトレーニングデータがあまりなくても、言語の音声合成システムと音声読み上げシステムの両方の品質を向上させるために行った研究です。
(2018年のGoogleの研究成果を振り返って(2/6)に続きます)
3.2018年のGoogleの研究成果を振り返って(1/6)関連リンク
1)ai.googleblog.com
Looking Back at Google’s Research Efforts in 2018
2)ai.google
Publication database
3)www.blog.google
Google AI Principles updates, six months in

コメント