
1.Google Assistantをマルチリンガルに育てるまとめ
・世界ではマルチリンガルな、複数言語を話せる人の方が多数派になってきている
・その潮流に対応するためにGoogle Assistantも二か国語に対応できるようになった
・使用されている言語の特定は簡単ではなく様々な入力を元にランダムフォレストで決定している
2.Google Assistantの二か国語対応を実現する技術
以下、ai.googleblog.comよりTeaching the Google Assistant to be Multilingualの意訳です。
マルチリンガル世帯、すなわち自国語以外にも複数言語を使っている家庭は増えてきています。多言語を話せる人の人数が既に単一言語しか話せない人の人数を上回っていることを示すいくつかの調査もあり、この数は増加し続けるでしょう。
このように多言語ユーザーの人口が急増している現在、Googleにとってユーザーの利便性向上のために複数の言語を同時にサポートできる製品を開発することがこれまで以上に重要になっています。
本日、GoogleはGoogle Assistantの2言語同時サポートを開始します。これにより、ユーザーは言語設定に戻ることなく、2つの異なる言語を使ったさまざま問い合わせを自由に行う事ができます。
サポートされている言語のうち、英語、スペイン語、フランス語、ドイツ語、イタリア語、日本語の2言語を選択して、アシスタントと話すことができます。
以前は、アシスタントの言語設定は1つしか選択できず、別の言語を使用するためには一々設定を変更する必要がありました。しかし、これからは、多言語の家庭はそのような手間をかけずに2つの言語を使って簡単に操作できます。
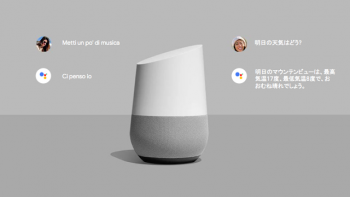
Google Assistantでは、アシスタントの設定を変更せずとも、言語を識別し、問い合わせを解釈し、適切な言語で回答を提供できるようになりました
しかし、マルチリンガル機能は簡単に実現できたものではありません。実際、これは数年にわたる努力の成果であり、多くの困難な問題を解決する必要がありました。最終的に私達はこの問題を3つの個別の問題に分割し、個々に解決していきました。「使用されている言語の識別」、「複数の言語の理解」、「多言語認識の最適化」をGoogle Assistantユーザーのために行っています。
使用されている言語の識別
人間であれば、スピーチの音響(イントネーション、発音の記憶など)に注意を払うだけで、誰かが別の言語を話している事を認識することができます。しかし、全自動音声認識システムを流用しても、自動で音声から言語を認識する事は困難でした。
Googleは2013年にディープラーニングを使用してLangID(language identification:言語を特定するシステム)の研究開発を開始しました。現在の我々の最先端のLangIDモデルは、リカレントニューラルネットワークを用いて2000以上の言語ペアを識別することができます。リカレントニューラルネットワークは音声認識、音声検出、話者認識などのシーケンス(連続する)データの問題解決に特に成功しているニューラルネットワークの一種です。
私たちが遭遇した課題の1つは、音声認識人工知能を学習させるために高品質な音声データセットを大量に用意する事でした。大量の学習データにより複数の言語を自動的に理解する事ができるようになり、高品質な学習データにより人工知能がより適切に言語を認識するようになります。
複数の言語の理解
一度に複数の言語を理解するには、複数のプロセスを並行して実行する必要があります。それぞれのプロセスでユーザからの問い合わせを段階的に処理していきます。Google Assistantは問い合わせに使用された言語を特定し、問い合わせを解析し、ユーザが求める具体的なアクションを実行するためのコマンドを作成する必要があるのです。
たとえば、モノリンガル、つまり単一言語しか使用していない環境であっても、ユーザーが「OK google, 午後6時にアラームを設定して」とGoogle Assistantに頼んだ時、アシスタントは頼まれた内容を理解し、時計アプリケーションを開いてパラメータ「6pm」をセットし、今日の6時にアラームが鳴るように設定する必要があります。
マルチリンガル環境の場合、上記と同様な作業を行う事に加えてLangIDを識別する作業と、複数言語を具体的なコマンドに解釈する作業を同時並行で動かさねばなりません。これはとてもチャレンジングな事であり、この記事の後半で2言語対応の制限について詳しく説明します。
重要な事は、Googleアシスタントはユーザーの問い合わせを、非同期的にリアルタイム処理し、インクリメンタルな結果を数ミリ秒で生成する必要があると言う事です。
(注:ユーザの問い合わせは突然発声されるので事前にわからないし、その問い合わせの言い回しや長さもわからないけれど、人工知能は数ミリ秒でコマンドとして解釈し応答しなければならない)
これは、LangIDとそれを補佐する追加のアルゴリズムで実現されます。LangIDは、現在使われている可能が高い言語の候補をそれぞれ確率で表現します。追加のアルゴリズムは(例えば、ユーザの好きなアーティストのような)ユーザの嗜好を考慮した上で各候補をランク付けします。
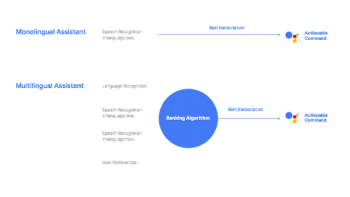
Google Assistantで使用されている多言語音声認識システムと、標準的な単一言語音声認識システムの対比の図です。ランキングアルゴリズムは、ユーザに関する関連情報とlangID結果を用いて、2つの単一言語音声認識装置から正しい言語認識を選択するために使用されます。
ユーザーが話すのをやめると、人工知能はどの言語が話されたのかの特定だけでなく、何が頼まれたのかを判断します。もちろん、これを行うためには、処理コストの増加や応答速度の不用意な遅延を防ぐ洗練された設計が必要です。
多言語認識の最適化
システムがより速くどの言語が話されているかを特定できれば、望ましくない影響を最小限に抑える事ができます。ユーザの発言が終わる前にシステムが現在話されている言語を特定できれば、システムは言語を特定する処理の実行を止める事ができるので、潜在的な待ち時間を減らす事ができます。これを念頭において、我々はシステムを最適化するいくつかの方法を見出しました。
私たちが検討したユースケースの1つは、ユーザーは通常、Google Assistantに対して同じ言語で話かけるということです。ユーザーは通常、アシスタントからも同じ言語を使って返答される事を期待しています。
(「ある単語を他の言語では何と発言するか?」と問い合わせるケースを除きます)
つまり、ほとんどの場合、問い合わせの最初の部分に集中することで、アシスタントは、異なる言語要素を含む文章であっても、話されている言語を推測する事ができます。この早期識別により、単一言語環境のように単一言語を認識する処理だけを実行するようにに切り替えることでき、タスクが単純化されます。
しかし、言語をいつ、どのように特定するか迅速に決定するのは簡単な話ではなく、技術的な紆余曲折がありました。具体的には、ランダムフォレストと言う手法を利用しています。
使用されているデバイスのタイプ、どの言語が使用されているかの仮説、仮説が提唱される頻度、個々の音声認識プログラムの不確実性、各言語が使われる頻度、などの複数の情報を組み合わせてもっとも確からしい言語を特定するのです。
システムの品質を簡素化し改善したもう一つの方法は、ユーザーが選択できる候補言語のリストを制限することでした。ユーザーは現在ホームデバイスがサポートしている6つの言語の中から2つを選択することができ、これは多言語を話すマルチリンガルユーザの大半のニーズをサポートする事ができます。しかし、私たちは技術を向上させ続け、次は3言語サポートに取り組んでいきたいと考えています。
二カ国語から三カ国語対応へ
当初より、私たちの目標は、Google Assistantが全てのユーザーと自然に会話できるようになることでした。多言語サポートは非常に求められている機能であり、数年前に私たちのチームが目指したものです。しかし、世界中の多くのバイリンガル・スピーカーが存在するだけでなく、2言語以上の言語が話されている家庭に住む3言語ユーザーや家族の生活をやりやすくしたいと考えています。
本日のアップデートで我々は正しい方向に進んでいます。これは、高度な機械学習、音声認識技術、LangIDモデルの改良に関するチームのコミットメントによって可能になりました。現在、Google Assistantに2つ以上の言語を同時に処理する方法を学ばせており、今後もサポート言語を追加するよう努めていきます!
3.Google Assistantをマルチリンガルに育てる感想
世界的にはマルチリンガルの人数の方が単一言語しか話せない人より多くなっている、と言う話に驚きました。まぁ、確かに外国で働く人は全員マルチリンガルでしょうし、日本でも都会のコンビニやマクドナルドは店員さんのほとんどが外国人である事は珍しくなくなってきており、皆さん母国語+簡単な日本語が話せるマルチリンガルなわけですから純粋に日本語しか話せない人は何時の間にやら少数派なのでしょう。
また、言語の特定にランダムフォレストが使われていると言う事が興味深かったです。
直近で少し関わったのが、ある数値を予測するプロジェクトだったのですがニューラルネットワークとランダムフォレストの2手法が比較検討されました。ニューラルネットワークはランダムフォレストより正確な値を出せる傾向があるのですが、稀に大きく外してしまう事があり、しかも外す理由が説明できないと言う事で、最終的にはランダムフォレストが採用されました。
「ランダムフォレストはGoogle Assistantやスマートスピーカーのような最新のデバイスでも使われている手法です」と言うフレーズは覚えておくと役に立つかもしれませんね。
4.Google Assistantをマルチリンガルに育てる関連リンク
1)ai.googleblog.com
Teaching the Google Assistant to be Multilingual
