
1.AudioLM:スピーチの続きもピアノの続きも生成可能なオーディオ言語モデル(1/2)まとめ
・オーディオ言語モデルは文章ではなくオーディオを使って学習した言語モデル
・GPT-3のような言語モデルが出来る事がオーディオを使ってできるモデル
・スピーチやピアノの音を入力として与えると自然な感じで続きを生成可能
2.AudioLMとは?
以下、ai.googleblog.comより「AudioLM: a Language Modeling Approach to Audio Generation」の意訳です。元記事の投稿は2022年10月6日、Zalán BorsosさんとNeil Zeghidourさんによる投稿です。
オーディオ言語モデル(Audio Language Models)とは、聞きなれない言葉ですが、入力として与えた音の続きを、人の声だろうが、楽器だろうが、その音の続きを生成できてしまうモデルです。
生のオーディオを直接生成可能なモデルにはOpenAIのJukeBoxなどがありましたが、JukeBoxはまだ音楽の範囲に留まっていました。しかし、AudioLMは音楽以外も対応しています。
つまり、偽文章を幾らでも生成出来てしまうと危惧されたGPT-3のオーディオ版ですね。おそらく、音楽や声の分野にも、イラスト界やデザイン界に大きなインパクトを与えたStable Diffusionのようなオープンソースのオーディオモデルが遠からずして出現するのではないかと感じています。
アイキャッチ画像はstable diffusionの生成で森の仲間と音楽会をやっているトトロ
リアルな音声を生成するには、異なる規模で表現された情報をモデリングする必要があります。例えば、音楽が個々の音符から複雑な音楽フレーズを構築するように、音声は音素や音節などの時間的な位置を固定した構造を組み合わせて単語や文にします。
このようなすべての規模において、構造化された一貫性のある音声の並びを作成することは、音声合成用のテキスト原稿やピアノ用のMIDI表現など、生成プロセスを導くことができる原稿と音声を結合することで対処されてきた課題です。
しかし、この方法は、音声障害者の声の回復に必要な話者の特徴や、ピアノ演奏の様式的要素など、音声の転写されていない部分をモデル化しようとすると破綻します。
論文「AudioLM: a Language Modeling Approach to Audio Generation」では、オーディオを聞くだけでリアルな音声やピアノ曲を生成できるように学習する、新しいオーディオ生成のフレームワークを提案します。AudioLMによって生成された音声は、長期的な一貫性(例:音声の構文、音楽の旋律)と高い忠実度を示し、従来のシステムを凌駕し、音声合成やコンピュータ支援音楽への応用など、音声生成の最前線を切り開いています。また、「AI原則」に従い、AudioLMが生成した合成音声を識別するモデルも開発しました。
文章言語モデルからオーディオ言語モデルへ
近年、非常に大規模なテキスト資料で学習させた言語モデルが、自由形式の対話から機械翻訳、さらには常識に関する推論まで、その優れた生成能力を発揮しています。さらに、テキスト以外の信号、例えば自然界の画像もモデル化できることが分かってきました。AudioLMは、このような言語モデリングの進歩を利用して、注釈付きデータから学習せずともオーディオを生成することを目的としています。
しかし、文章言語モデル(text language models)からオーディオ言語モデル(audio language models)へ移行する際には、いくつかの課題があります。まず、オーディオはデータ量が多いため、データ長が長くなります。文章が数十文字であるのに対し、オーディオは数十万の値を持ちえます。
第二に、文章とオーディオの間には一対多の関係があります。つまり、同じ文章でも、話し方や感情表現、録音条件などが異なれば、異なる話者によって表現される可能性があります。
この2つの課題を克服するために、AudioLMは2種類のオーディオトークンを活用します。まず、自己教師付き音声モデルであるw2v-BERTから意味トークン(semantic tokens)を抽出します。このトークンは、局所的な依存関係(例:オーディオの音韻、ピアノ音楽の局所的な旋律)と大域的な長期構造(例:音声の言語構文と意味内容、ピアノ音楽の和音とリズム)の両方を捉えるとともに、長く連続するデータをモデル化できるようオーディオ信号を大きくダウンサンプリングしています。
しかし、これらのトークンから再構成されたオーディオは、忠実度が低いという欠点があります。そこで、意味トークンに加えて、音声波形の詳細(話者の特徴や録音条件など)を捉え、高品質な合成を可能にするSoundStreamニューラルコーデックによる音響トークン(acoustic tokens)を利用することで、この限界を克服します。意味トークンと音響トークンの両方を生成するシステムを訓練することで、高い音質と長期的な一貫性を同時に実現することができます。
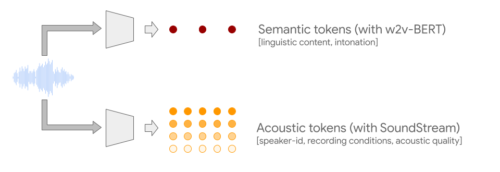
オーディオのみで言語モデルを学習させる
AudioLMは純粋なオーディオモデルであり、オーディオに関する文章やシンボル表現を一切使わずに学習します。AudioLMは、複数のTransformerモデルを連結することで、意味トークンから細かい音響トークンまで、連続するオーディオを階層的にモデル化します。各ステージは、テキスト言語モデルを訓練するように、過去のトークンに基づいて次のトークンを予測するために訓練されます。最初のステージは、連続するオーディオの上位構造をモデル化するために、意味トークンに対してこのタスクを実行します。

第2段階では、意味トークンの並びと過去の粗い音響トークンを連結し、両方を条件付けとして粗い音響モデル(coarse acoustic model)に与え、将来のトークンを予測させます。この段階では、音声における話者の特徴や音楽における音色などの音響特性をモデル化します。

第3段階では、粗い音響トークンを細かい音響モデル(fine acoustic model)で処理し、最終的な音声にさらなる細部を追加します。最後に、音響トークンをSoundStreamデコーダーに送り、波形を再構築します。
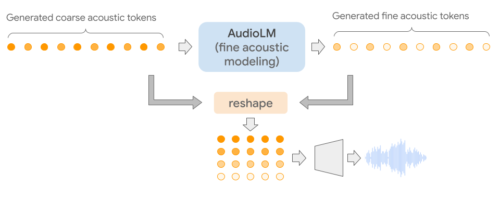
3.AudioLM:スピーチの続きもピアノの続きも生成可能なオーディオ言語モデル(1/2)関連リンク
1)ai.googleblog.com
AudioLM: a Language Modeling Approach to Audio Generation
2)arxiv.org
AudioLM: a Language Modeling Approach to Audio Generation
3)google-research.github.io
AudioLM

