
1.PaLM:5400億パラメータを持つ革新的なパスウェイ言語モデル(1/3)まとめ
・昨年、Googlは領域やタスクを横断して汎化できる高効率な単一モデルPathways構想を発表
・PaLMはPathwaysシステムで学習した5,400億のパラメータを持つ密なTransformerモデル
・ほとんどのタスクにおいて、大きな差をつけて、最先端の少数ショット学習性能を達成
2.PaLMとは?
以下、ai.googleblog.comより「Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance」の意訳です。元記事は2022年4月4日、Sharan NarangさんとAakanksha Chowdheryさんによる投稿です。
以前から、Googleの次世代大規模モデル構想としてチラチラと単語だけは出てきていたPathwaysが遂に登場。DALL·E 2とほぼ同時期に紹介されたため「Deep Learningは最近、壁にぶつかっている説」を吹き飛ばしたかのように驚きをもって受け止められていましたが、DALL·E 2と同様に論文内に書かれている事だけでは再現が難しいという批判もあるようです。
以下にもPaLMの能力を示す例をアップしてあります
「2022年のAIの進歩は汎用人工知能に手が届くところまで来ているのか?」
Pathways=小道と言う事からアイキャッチ画像のクレジットはPhoto by Stephen Leonardi on Unsplash
近年、言語理解と言語生成のために訓練された大規模なニューラルネットワークは、幅広いタスクで素晴らしい成果を上げています。GPT-3は、大規模言語モデル(LLM:Large Language Models)が小数ショット学習が可能で、大規模なタスク固有のデータ収集やモデルパラメータの更新なしに素晴らしい結果を達成できることを初めて示しました。
GLaM、LaMDA、Gopher、Megatron-Turing NLGなどの最近のLLMは、モデルサイズを拡大し、疎に活性化したモジュールを使用し、より多様なソースからの大規模データセットで学習することにより、多くのタスクで少数ショットで最先端の結果を達成することができるようになりました。しかし、モデル規模拡大の限界に挑戦しながら少数ショット学習を実現する能力を理解しようとしても、まだ多くの課題が残っています。
昨年、Google Researchは、領域やタスクを横断して汎化でき、かつ高効率な単一モデルであるPathwaysの未来像を発表しました。この未来像の実現に向けた重要なマイルストーンは、アクセラレータ用の分散計算を統合するために新しいPathwaysシステムを開発することでした。
論文「PaLM: Scaling Language Modeling with Pathways」では、Pathwaysシステムで学習した5,400億のパラメータを持つ、密なデコーダのみのTransformerモデル、Pathways Language Model(PaLM) を紹介します。
Pathwaysシステムは複数のTPU v4 Podsにわたって単一のモデルを効率的に学習させることを可能にします。PaLMを数百の言語理解・生成タスクで評価した結果、ほとんどのタスクにおいて、多くのケースで大きな差をつけて、最先端の少数ショット学習性能を達成することがわかりました。
Pathwaysを用いた5,400億パラメータの言語モデルの学習
PaLMは、Pathwaysシステムを初めて大規模に使用し、これまでトレーニングに使用したTPUベースのシステム構成としては最大の6144チップにトレーニングを規模拡大できる事を実証しています。
このトレーニングは、2つのCloud TPU v4 PodsにまたがるPodレベルのデータ並列化と、各Pod内での標準的なデータおよびモデル並列化を用いて規模を拡大しています。これは、単一のTPU v3 Pod(GLaM、LaMDAなど)でトレーニングするか、パイプライン並列処理を使用してGPUクラスタ全体を2240枚のA100 GPUにスケールアップするか(Megatron-Turing NLG)、複数のTPU v3 Podを使用して最大4096 TPU v3チップの規模(Gopher)であるこれまでのLLMの大半に比べて、大幅にスケールが向上したことを示しています。
PaLMは、ハードウェアFLOPs利用率57.8%という学習効率を達成しました。この規模のLLMではこれまでで最高の学習効率です。これは、並列化手法とTransformerブロックの再定式化により、attention層とフィードフォワード層の並列計算が可能となり、TPUコンパイラの最適化により高速化されたことによります。
PaLMは、高品質のウェブ文書、書籍、Wikipedia、会話、GitHubコードを含む英語と多言語のデータセットを組み合わせて学習されました。また、「データ損失のない(lossless)」語彙を作成し、すべての空白(プログラミングコード内では意味を持つため特に重要)を保存し、語彙外のユニコード文字をバイトに分割し、数字を各桁ごとに個々のトークンに分割しました。
言語・推論・コードの各タスクで画期的な能力を発揮
PaLMは、数多くの難易度の高いタスクで画期的な能力を発揮しています。ここでは、言語理解・生成、推論、コード関連タスクについて、いくつかの例を取り上げます。
言語理解・生成
広く使われている29の英語自然言語処理(NLP:Natural Language Processing)タスクでPaLMを評価しました。
その結果、GLaM、GPT-3、Megatron-Turing NLG、 Gopher、 Chinchilla、 LaMDAといった先行大型モデルの少数ショット学習性能をPaLM 540Bは29タスク中28タスクで上回りました。
これらのタスクは、質問回答タスク(領域を限定しない、理解し難い問)、穴埋め・文補充タスク、代名詞から元の名詞を推論するタスク(Winograd-style tasks)、文脈内読解タスク、常識推論タスク、SuperGLUEタスク、自然言語推論タスクなど多岐にわたります。
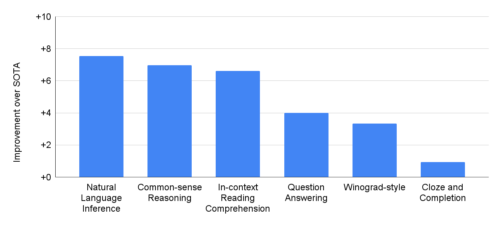
PaLM 540Bは、29の英語ベースの自然言語処理タスクにおいて、従来の最先端技術(SOTA)よりも性能が向上しています。
PaLMは英語NLPタスクだけでなく、翻訳を含む多言語NLPベンチマークにおいても、非英語のデータは学習コーパスの22%のみであるにもかかわらず、高い性能を示しています。
3.PaLM:5400億パラメータを持つ革新的なパスウェイ言語モデル(1/3)関連リンク
1)ai.googleblog.com
Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance
2)arxiv.org
PaLM: Scaling Language Modeling with Pathways


モデルの規模が大きくなるにつれて、タスク全体のパフォーマンスが向上し、同時に新しい機能が解放されます