
1.Jukebox:歌声を含む生のオーディオを生成可能なニューラルネット(1/2)まとめ
・音楽におけるスタイル転送が歌声を含む生の音声データで可能なOpen AIのJukeboxの紹介
・CD品質の音楽は1,000万を超えるタイムステップになりGPT-2の1000と比較しても膨大
・モデルに非常に離れた位置同士の依存関係を処理させるために様々な工夫が必要になった
2.Jukeboxとは?
以下、openai.comより「Jukebox」の意訳です。元記事の投稿は2020年4月30日、Prafulla Dhariwalさん, Heewoo Junさん, Christine McLeavey Payneさん, Jong Wook Kimさん, Alec Radfordさん, Ilya Sutskeverさん, Ashley Pilipiszynさん, Justin Jay Wangさん, Brooke Chanさん, Ben Barryさんによる投稿です。
音楽におけるスタイル転送、すなわち様々な楽曲のスタイルを他の楽曲に適用する事が出来るMuseNetは衝撃的でしたが、扱える音は機械が奏でる音に留まっていました。その後続研究であるJukeboxは歌声を含む生の音声を扱える事が特徴で、更に衝撃的な研究なのですが、発表時期がコロナの真っ最中で更に直後にGPT-3が発表された事なども重なり、衝撃度の割にあまり注目を集めていないモデルです。
アイキャッチ画像は本物のJukebox(日本ではあまり見かけないのでご存じない方もおられるかもしれませんが、娯楽施設内などに置かれているお金を入れると好きな曲を再生できる機械です)でクレジットはPhoto by Tom Grove on Unsplash
2021年1月追記)Jukeboxを使ってみた結果はこちら。
様々なジャンルやアーティスト風に、MIDIデータではなく、初歩的な歌声を含む生のオーディオを生成可能なニューラルネットであるJukebox紹介します。生成されたサンプルを探索するためのツールとともに、モデルの重みとコードを公開します。
厳選したサンプル
ジャンル、アーティスト、歌詞を入力として提供されたJukeboxは、ゼロから作成された新しい音楽サンプルを出力します。以下に、お気に入りのサンプルをいくつか示します。
学習データ内にない歌詞を作詞
ジュークボックスは、幅広い音楽と歌のスタイルを生み出す事が可能で、トレーニング中に提供されなかった歌詞を作り出す事ができます。以下の歌詞はすべて、言語モデルとOpenAIの研究者によって共同作詞されたものです。
Rock, in the style of Elvis Presley – Jukebox
再解釈
トレーニング中に提供された歌詞を使う事を条件にすると、Jukeboxはトレーニングされた元の曲とは非常に異なる曲を作成する事ができます。
Country, in the style of Alan Jackson – Jukebox
引き継ぎ
条件付けのために12秒間のオーディオを最初に提供すると、Jukeboxは残りを指定されたスタイルで書き上げます。最初のサンプルでは、モデルは、ポリリズムとヒップホップをジャンルを超えた方法でブレンドすることにより、OpenAIミュージシャンのWill Gussの導入部を引き継いで作曲を続けています。
Hip Hop, in the style of 2Pac – Jukebox
楽しい曲
デュエット、人気のある歌詞、ディープラーニングに関する曲、子供向けの音楽をサンプリングします。
Jazz, in the style of Frank Sinatra & Ella Fitzgerald – Jukebox
他のサンプルを聞くには、jukebox.openai.comをチェックしてください。(全ての曲を聴くには10日かかります)
本研究の動機と以前の研究
自動音楽生成の研究は半世紀以上前にさかのぼります。
顕著なアプローチは、演奏される各音符のタイミング、ピッチ、ベロシティ、および楽器を指定するピアノロールの形で象徴的に音楽を生成することです。これにより、バッハのコラール、複数の楽器を使用したポリフォニック音楽、微細な長さの楽曲などの印象的な結果が得られました。
ただし、シンボリックジェネレータには制限があります。人間の声や、音楽に不可欠なより繊細な音色、ダイナミクス、表現力の多くを捕捉する事はできません。
別のアプローチは、音楽を生のオーディオとして直接モデル化することです。しかし、入力データが非常に長くなるため、オーディオレベルで音楽を生成することは困難です。
CD品質(44 kHz、16ビット)の典型的な4分間の曲には、1,000万を超えるタイムステップがあります。参考までに、GPT-2のタイムステップは1000であり、OpenAI Fiveにはゲーム毎に数万のタイムステップがありました。従って、高いレベルで音楽の意味を学習するためには、モデルは非常に離れた位置同士の依存関係を処理する必要があります。
長い入力の問題に対処する1つの方法は、知覚的に無関係な情報の一部を破棄することにより、生のオーディオを低次元空間に圧縮するオートエンコーダーを使用することです。 次に、この圧縮された空間でオーディオを生成するようにモデルをトレーニングし、生のオーディオ空間にアップサンプリングして戻すことができます。
生成モデルの限界を押し広げたいと思ったので、音楽に取り組むことにしました。MuseNetに関するこれまでの作業では、大量のMIDIデータに基づいて音楽を合成する方法について説明しました。 生のオーディオでは、モデルは非常に長距離の構造だけでなく、高い多様性に取り組むことを学ぶ必要があり、特に短期、中期、または長期のタイミングでのエラーを生のオーディオは許容しません。
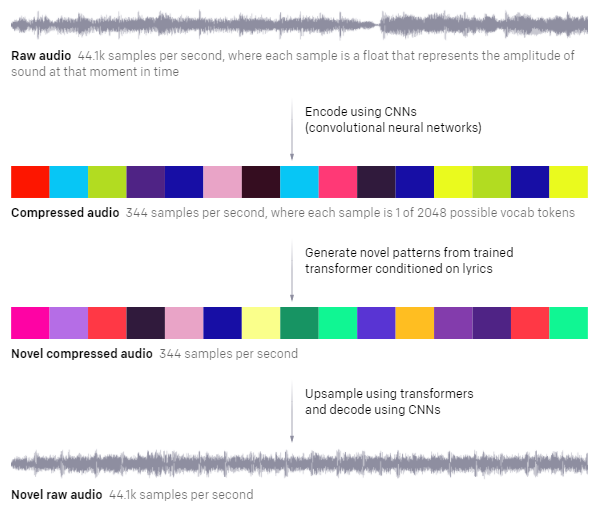
上から、
(1)生のオーディオ:1秒あたり44.1kサンプル。各サンプルは、その瞬間の音の振幅を表す浮動小数点です。
(2)畳み込みネットワークを使ってエンコードした圧縮オーディオ:毎秒344サンプル。各サンプルは2048個の語彙トークンの中の1つです。
(3)歌詞を使って訓練されたtransformerから新しいパターンを生成。新しい圧縮オーディオは344サンプル/秒
(4)トランスフォーマーを使用してアップサンプリングし、CNNを使用してデコード。新しい生のオーディオ:44.1kサンプル/秒
手法
音楽を個別のコードに圧縮
Jukeboxのオートエンコーダモデルは、VQ-VAEと呼ばれる量子化ベースのアプローチを使用してオーディオを離散空間に圧縮します。階層型VQ-VAEsは、いくつかの楽器セットから短い楽器を生成できますが、連続するエンコーダを自動回帰デコーダーと組み合わせて使用するため、階層が崩壊してしまいます。
VQ-VAE-2と呼ばれる単純化された改良型は、フィードフォワードエンコーダーとデコーダーのみを使用することでこれらの問題を回避し、忠実度の高い画像を生成する印象的な結果を示しています。VQ-VAE-2からインスピレーションを得て、そのアプローチを音楽に適用しました。このアーキテクチャを次のように変更します。
・VQ-VAEモデルに共通するコードブック(codebook)の崩壊を軽減するために、ランダムリスタートを使用して、その使用量がしきい値を下回るたびに、コードブックベクトルをエンコードされた非表示状態の1つにランダムにリセットします。
・上位レベルを最大限に活用するために、個別のデコーダーを使用し、各レベルのコードから独立して入力を再構築します。
・モデルがより高い周波数を簡単に再構築できるようにするために、入力スペクトログラムと再構築されたスペクトログラムの距離差にペナルティを課すスペクトル損失を追加します。
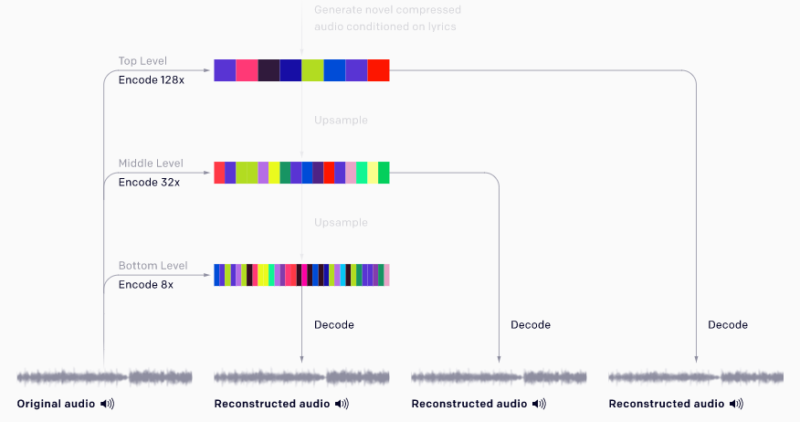
以下に示すVQ-VAEでは3つのレベルを使用します。これらのレベルは、44kHzの生のオーディオをそれぞれ8倍、32倍、128倍に圧縮します。各レベルのコードブックサイズは2048です。
このダウンサンプリングでは、オーディオの詳細の多くが失われ、レベルをさらに下げると、著しくノイズが多く聞こえます。ただし、オーディオのピッチ、音色、音量に関する重要な情報は保持されます。
(1)圧縮
各VQ-VAEレベルは、入力を個別にエンコードします。 最下位のエンコーディングは最高品質の再構成を生成し、最上位のエンコーディングは重要な音楽情報のみを保持します。
(2)生成
新しい曲を生成するために、transformer の連なりがトップレベルからボトムレベルにコードを生成し、その後、ボトムレベルのデコーダーがそれらを生のオーディオに変換します。
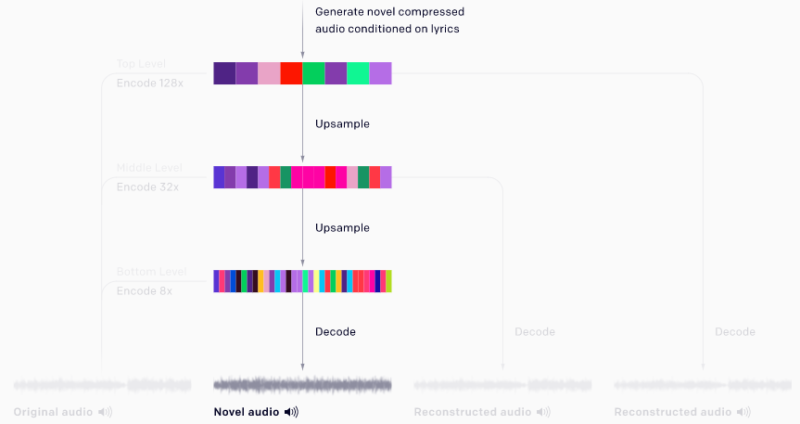
transformer を使用してコードを生成
次に、VQ-VAEによってエンコードされた音楽コードの分布を学習し、この圧縮された離散空間で音楽を生成することを目的とする従来のモデルをトレーニングします。
VQ-VAEと同様に、3つのレベルの事前確率があります。最も圧縮されたコードを生成するトップレベルの事前確率と、上記の条件で圧縮率の低いコードを生成する2つのアップサンプリング事前確率です。
トップレベルのモデルは楽曲の長距離構造をモデル化しており、このレベルからデコードされたサンプルは音質は低くなりますが、歌やメロディーなどの高レベルの意味を捕捉します。ミドルとボトムのアップサンプリングにより、音色などの局所的な音楽構造が追加され、オーディオ品質が大幅に向上します。
Sparse Transformersの簡略化された版を使用して、これらを自己回帰モデルとしてトレーニングします。これらの各モデルには、8192コードを使って、72層に因数分解されたself-attentionがあります。これは、それぞれトップ、ミドル、ボトムレベルで約24秒、6秒、および1.5秒の生の音声に対応します。
すべての事前トレーニングが完了すると、トップレベルからコードを生成し、アップサンプラーを使用してコードをアップサンプリングし、VQ-VAEデコーダーを使用して生のオーディオ空間にデコードして新しい曲をサンプリングできます。
データセット
このモデルをトレーニングするために、インターネットから、120万曲(うち60万曲は英語)の新しいデータセットを、LyricWikiの対応する歌詞とメタデータと組み合わせて収集しました。メタデータには、アーティスト、アルバムのジャンル、曲が発表された年、および各曲に関連付けられた一般的なムードやプレイリストのキーワードが含まれます。32ビットの44.1kHz生オーディオでトレーニングし、左右のチャネルをランダムにダウンミックスしてモノラルオーディオを生成することでデータの水増しを実行しました。
3.Jukebox:歌声を含む生のオーディオを生成可能なニューラルネット(1/2)関連リンク
1)openai.com
Jukebox
2)jukebox.openai.com
Jukebox Sample Explorer
3)arxiv.org
Jukebox: A Generative Model for Music
4)github.com
openai / jukebox

