1.学習用データが非常に少ない言語で機械翻訳を実現した手法(1/2)まとめ
・機械翻訳サービスは大多数の人が話す言語をカバーしているが数としては合計100言語程度
・100言語は世界で話されている言語の1%強に過ぎず地域もヨーロッパ系に偏っている
・これはデータの不足とパラレルテキスト(翻訳元文と翻訳済文のペア)の不足による制限
2.Zero-Resource Machine Translationとは?
以下、ai.googleblog.comより「Unlocking Zero-Resource Machine Translation to Support New Languages in Google Translate」の意訳です。元記事は2022年5月11日、Isaac CaswellさんとAnkur Bapnaさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Mpumelelo Macu on Unsplash
機械翻訳(MT:Machine Translation)技術は、ディープラーニングが自然言語処理(NLP:Natural Language Processing)と統合されたことで、近年大きな進歩を遂げました。
WMTなどの研究用ベンチマークにおける性能は急上昇し、翻訳サービスは品質が向上し、新しい言語が含まれるようなりました。しかし、既存の翻訳サービスは、世界の大多数の人が話す言語をカバーしているものの、合計で約100言語しかカバーできておらず、世界で活発に話されている言語の1%強に過ぎません。また、収録されている言語は圧倒的にヨーロッパ系が多く、アフリカや南北アメリカなど言語的多様性の高い地域は見落とされているのが現状です。
話者の少ない言語に対して翻訳モデルを構築する上で、2つの重要なボトルネックがあります。1つ目は、データの不足です。多くの言語のデジタルデータは限られており、言語識別(LangID:Language Identification)モデルの品質上の問題から、ウェブ上で見つけることが困難な場合があります。
2つ目の課題は、モデルの限界に起因するものです。MTモデルは通常、大量のパラレルテキスト(翻訳元文と翻訳済文のペア)で学習しますが、そのようなデータがない場合、モデルは限られた量の単一言語テキスト(monolingual text)から翻訳を学習しなければならず、これは新しい研究領域となります。翻訳モデルが十分な品質に達するためには、この両方の課題を解決する必要があります。
論文「Building Machine Translation Systems for the Next Thousand Languages」では、翻訳データセットを持たない1000以上の言語について、高品質の単一言語データセットを構築する方法を説明し、単一言語データのみを用いてMTモデルを学習する方法を実証しています。
この取り組みの一環として、私達はGoogle翻訳を拡張し、利用可能なリソースが不足している24の言語を翻訳対象に追加しています。これらの言語については、特殊なニューラル言語識別モデルと新しいフィルタリングアプローチを組み合わせて開発・使用することで、単一言語データセットを作成しました。
私たちが紹介する技術は、ゼロリソース翻訳を可能にするために、自己教師タスクで大規模な多言語モデルを補足します。最後に、この成果の実現にネイティブスピーカーがどのように貢献したかを紹介します。
データとの出会い
リソースが不足している言語について、使えるテキストデータを自動的に収集することは、見た目よりもずっと難しいことです。LangIDのようなタスクは、リソースが多い言語には有効ですが、リソースが少ない言語ではうまくいきません。また、ウェブから収集した多くの公開データセットには、サポートしようとする言語のデータよりもノイズが多く含まれていることがよくあります。
私たちの初期の試みは、標準的なCompact Language Detector v3(CLD3)LangIDモデルを訓練することによって、Web上のリソース不足の言語を識別することでしたが、私たちもそのようにして収集したデータセットがあまりにもノイズが多いために使えないことを発見しました。
その代わりに、私達は1000以上の言語に対してTransformerベースの半教師付きLangIDモデルを学習させました。このモデルはLangIDタスクをMASS(Masked Sequence-to-Sequence)タスクで補完し、ノイズの多いウェブから収集したデータに対する汎用性を高めています。
MASSは入力からランダムにトークンの一部を削除することで入力の一部を空白化し、これらの空白部分を予測するようにモデルを学習させます。私達はCLD3モデルでフィルタリングされ、類似言語のクラスタを認識するように訓練されたデータセットに、Transformerベースのモデルを適用しました。
次に、オープンソースのTerm Frequency-Inverse Internet Frequency(TF-IIF)フィルタリングを結果のデータセットに適用し、実際には高リソース言語に関連する文章であった場合は破棄し、特定の異常を排除するために様々な言語固有のフィルタを開発しました。
その結果、1000を超える言語の単一言語テキストを含むデータセットが完成し、そのうち400は10万文以上の文章を含んでいました。このうち68言語について人間による評価を行った結果、大多数(70%以上)が高品質の言語内コンテンツを反映していることが分かりました。
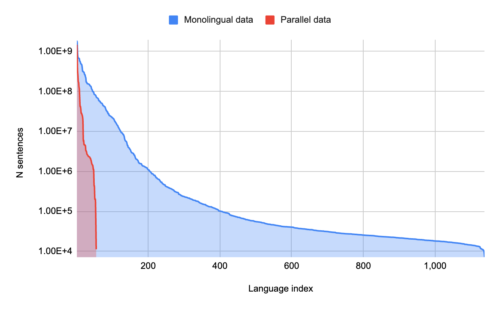
1言語あたりのモノリンガルデータ量と1言語あたりのパラレル(翻訳)データ量。少数の言語が大量のパラレルデータを持つが、モノリンガルデータしか持たない言語がロングテールとして存在する。
3.学習用データが非常に少ない言語で機械翻訳を実現した手法(1/2)関連リンク
1)ai.googleblog.com
Unlocking Zero-Resource Machine Translation to Support New Languages in Google Translate
2)arxiv.org
Building Machine Translation Systems for the Next Thousand Languages
