
1.Panoptic-DeepLab:総括的に風景を理解する新手法(1/2)まとめ
・自動運転車やロボットはインスタンスとセマンティックの2つのセグメンテーションを実施
・インスタンスセグメンテーションは、画像内の個々の特定の物体を区別してラベル付けする
・セマンティックセグメンテーションは画像内の全画素にラベルを付けるが実体を区別しない
2.パノプティックセグメンテーションとは?
以下、ai.googleblog.comより「Improving Holistic Scene Understanding with Panoptic-DeepLab」の意訳です。元記事の投稿は2020年7月21日、Bowen ChengさんとLiang-Chieh Chenさんによる投稿です
セマンティックと言う単語はあまり馴染がないと思うのですが直訳すると「意味の」とか「意味論の」という意味です。更にAI関連分野だと「セマンティック検索」と「セマンティックセグメンテーション」という全く違う意味で使われるため、何とかしてわかりやすい日本語に訳してみようと考えていたのですが、今回のお話で自分が「セマンティックセグメンテーション」と「インスタンスセグメンテーション」の定義を誤解していた事がわかり、且つ、「パノプティックセグメンテーション」と言う第三勢力が登場したので、後日用語集で丸呑みするべき概念として改めてまとめる事にして今後は「セマンティックセグメンテーション」で統一する事にしました。
アイキャッチ画像のクレジットはPhoto by Douglas Bagg on Unsplash
2020年8月追記)後続研究としてより高い性能を持つAxial-DeepLabが発表されています。
自動運転車やロボット工学などの現実世界のコンピュータービジョンアプリケーションは、インスタンスセグメンテーション(instance segmentation、実体のセグメンテーション)とセマンティックセグメンテーション(semantic segmentation、意味的なセグメンテーション)という2つの主要なタスクに依存しています。
インスタンスセグメンテーションは、画像内の個々の「特定の物体(things)」(つまり、人、動物、車などの数える事が可能な物体)の種別と描画範囲を識別し、それぞれに一意の識別子(インスタンスID、car_1やcar_2など)を割り当てます。
次に、これがセマンティックセグメンテーションタスクによって補完されます。
セマンティックセグメンテーションは、「特定の物体(things)」とその周囲の「あやふやな物体(stuff)」(例えば、草、空、道路などの類似した質感または材質で構成されるが、定まった形を持たない物体)を含む、画像内の全ての画素にラベルを付けます。
ただし、この後者のラベルは物体が異なる実体か否かは区別しません(セマンティックラベルではcar_1もcar_2もcarとして画素がラベル付けされます)。
パノプティックセグメンテーション(Panoptic segmentation、総括的なセグメンテーション)とは、これら2つのアプローチの統合を試みます。すなわち、セマンティックラベルとインスタンスIDの両方をエンコードし、画像内のすべてのピクセルに一意の値を割り当てることを目的とします。
既存のパノプティックセグメンテーションアルゴリズムのほとんどは、セマンティックセグメンテーションとインスタンスセグメンテーションを別々に処理するMask R-CNNを使っています。
インスタンスセグメンテーションは、画像内の物体を識別しますが、多くの場合、個々の実体(インスタンスマスク)が互いに重なりあった状態でインスタンスマスクを識別してしまいます。
重複するインスタンスマスクの競合状態を解決するために、一般的には経験則的なルールが使われます。例えば、信頼性スコアが高い方のマスクを採用する、もしくはカテゴリ間で事前定義されたペア毎の関係性(例:「ネクタイ」は「人の体」より手前に位置する等)を使用する等です。
更に、セマンティックとインスタンスのセグメンテーション結果の不一致は、インスタンスの予測を優先することで整理されます。これらの手法は一般に良い結果をもたらしますが、応答時間が長くなるため、リアルタイムアプリケーションに適用する事は困難になります。
リアルタイムに実行できるパノプティックセグメンテーションモデルの必要性に基づいて、CVPR 2020で承認された論文「Panoptic-DeepLab: a simple, fast and strong system for panoptic segmentation」を提案します。
本研究では、一般的に良く使われている最新のセマンティックセグメンテーションモデルであるDeepLabを拡張し、わずかな追加のパラメーターのみを使用し、わずかな計算コストを追加して、パノプティックセグメンテーションを実現します。
結果のモデルであるPanoptic-DeepLabは、セマンティックセグメンテーションとインスタンスセグメンテーションを並行して実行可能で領域も重複しません。これにより、他の手法で採用されている手動設計された経験則的なルールの必要性を回避します。
更に、セマンティックとインスタンスのセグメンテーション結果を併合する計算効率の高い操作を開発し、ほぼリアルタイムのエンドツーエンドのパノプティックセグメンテーション予測を可能にします。
マスクR-CNNに基づく方法とは異なり、Panoptic-DeepLabは境界ボックス(bounding box)を使った予測を生成せず、トレーニング中に3つの損失関数のみを必要とします。これは、UPSNetなどの最新モデルの手法よりも大幅に少なく、最大8つまで使用可能です。
最後に、Panoptic-DeepLabはいくつかの学術データセットで最先端のパフォーマンスを実証しました。

Panoptic-DeepLabによって出力されたパノプティックセグメンテーション
左:パノプティックセグメンテーションモデルへの入力として使用されたビデオフレーム。
右:ビデオフレームに重ね合わせた出力結果。各オブジェクトの実態には、car_1、car_2などの一意のラベルがつけられています。
概要
Panoptic-DeepLabは、概念的にもアーキテクチャ的にもシンプルです。
高レベルでは、3つの出力を予測します。
1つ目はセマンティックセグメンテーションです。セマンティックセグメンテーションでは、各画素にセマンティッククラス(車や芝生など)を割り当てます。ただし、同じクラス(種別)であっても実体の区別はしません。
従って、例えば、1台の車の一部が別の車の後ろに位置している場合、両車に関連付けられている画素は同じクラス(車)であり、区別はできなくなります。
これは、2番目にモデルから出力される2つの出力を使った、「各実体の重心の予測(center-of-mass prediction for each instance)」と「実体の中心への回帰(instance center regression)」によって対処できます。
これは、モデルに各実体の画素をその重心に回帰させる事を学習させ、後者の処理で、モデルが特定のクラスの画素を適切な実体に関連付けることを保証します。
クラスに依存しない実体のセグメンテーションは、前面ピクセルを最も近いと予測された実体の中心にグループ化することによって取得されます。
次に、多数決投票ルールによるセマンティックセグメンテーションと融合して、最終的なパノプティックセグメンテーションが生成されます。
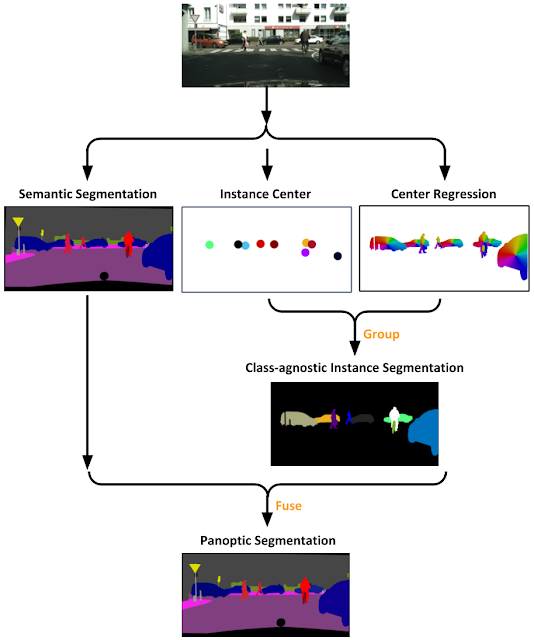
Panoptic-DeepLabの概要
セマンティックセグメンテーションは画像内の画素を一般的なクラスに関連付けます。クラスにとらわれないインスタンスセグメンテーションステップは、クラスに関係なく、個々の物体に関連付けられた画素を識別します。まとめると、最終的なパノプティックセグメンテーションが得られます。
3.Panoptic-DeepLab:総括的に風景を理解する新手法(1/2)関連リンク
1)ai.googleblog.com
Improving Holistic Scene Understanding with Panoptic-DeepLab
2)arxiv.org
Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation

