
1.SoundStream:ビットレート可変なニューラルオーディオコーデック(1/2)まとめ
・SoundStreamはスマートフォンのCPUでリアルタイムに実行可能で音声と音楽を処理できる
・単一モデルで可変ビットレートで高品質を実現する初のニューラルネットワークコーデック
・SoundStreamは新しい残余ベクトル量子化器という新しい手法でこれを実現している
2.SoundStreamとは?
以下、ai.googleblog.comより「SoundStream: An End-to-End Neural Audio Codec」の意訳です。元記事の投稿は2021年8月12日、Neil ZeghidourさんとMarco Tagliasacchiさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Kelly Sikkema on Unsplash
オーディオコーデックは、オーディオを効率的に圧縮して、ストレージ要件またはネットワーク帯域幅を削減するために使用されます。
理想的には、オーディオコーデックはエンドユーザーに対して透過的である必要があります。つまり、デコードされたオーディオは元のオーディオと知覚的に区別できず、エンコード/デコード処理による遅延も感じない事が理想的な要件です。
過去数年にわたって、OpusやEnhanced Voice Services(EVS)など、さまざまなオーディオコーデックがこれらの要件を満たすために開発されてきました。
Opusは、6kbps(キロビット/秒)から510kbpsまでのビットレートをサポートする多用途の音声およびオーディオコーデックであり、Google Meetなどのビデオ会議プラットフォームからYouTubeなどのストリーミングサービスに至るまで、さまざまなアプリケーションで広く使われています。
EVSは、携帯電話を対象とした3GPP標準化団体によって開発された最新のコーデックです。Opusと同様に、5.9 kbps~128kbpsの複数のビットレートで動作する多用途のコーデックです。
これらのコーデックのいずれかを使用して再構築されたオーディオの品質は、中程度から低いビットレート(12~20 kbps)で優れていますが、非常に低いビットレート(3kbpsより小さい)では急激に品質が低下します。
これらのコーデックは、人間の知覚に関する専門知識と慎重に設計された信号処理パイプラインを活用して、圧縮アルゴリズムの効率を最大化します。最近、これらの手作りのパイプラインを、データ駆動型の方法でオーディオをエンコードすることを学習する機械学習アプローチに置き換えることに関心が集まっています。
今年の初めに、低ビットレート音声用のニューラルオーディオコーデックであるLyraをリリースしました。
論文「SoundStream: an End-to-End Neural Audio Codec」では、高品質のオーディオを提供し、クリーンなスピーチ、ノイズの多い残響のあるスピーチ、音楽、環境音など、さまざまなサウンドタイプをエンコードするように拡張することで、これらの取り組みを拡張する新しいニューラルオーディオコーデックを紹介します。
SoundStreamは、スマートフォンのCPUでリアルタイムに実行できる一方で、音声と音楽を処理できる最初のニューラルネットワークコーデックです。単一のトレーニング済みモデルを使用して、幅広いビットレートで最先端の品質を提供できます。これは、学習可能なコーデックの大幅な進歩を表しています。
データからオーディオコーデックを学習
SoundStreamの主な技術的要素は、エンコーダー、デコーダー、量子化器で構成されるニューラルネットワークです。これらは個別にトレーニングされるのではなく、エンドツーエンドで直接トレーニングされています。
エンコーダーは、入力オーディオストリームをコード化された信号に変換します。コード化された信号は、量子化器を使用して圧縮され、デコーダーを使用してオーディオに変換されます。
SoundStreamは、ニューラルオーディオ合成(neural audio synthesis)の分野における最先端のソリューションを活用して、高い知覚品質でオーディオを配信できます。
再構築されたオーディオを非圧縮のオリジナルのように聞こえるように誘導する敵対的損失関数と再構築損失関数の組み合わせを計算するディスクリミネーターをトレーニングすることにより、これを実現しています。
トレーニングが完了すると、エンコーダーとデコーダーを別々のクライアントで実行して、ネットワークを介して高品質のオーディオを効率的に送信できます。
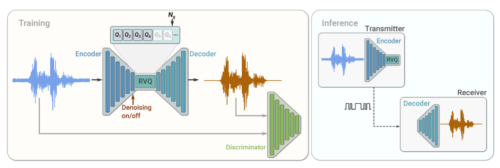
SoundStreamのトレーニングと推論
トレーニング中、エンコーダー、量子化器、デコーダーのパラメーターは、ディスクリミネーターによって計算された再構成と敵対的損失の組み合わせを使用して最適化されます。ディスクリミネーターは「オリジナルの入力オーディオ」と「再構成されたオーディオ」を区別するようにトレーニングされています。推論実行中、送信機のエンコーダーと量子化器は圧縮されたビットストリームを受信機に送信し、受信機はオーディオ信号をデコードできます。
残余ベクトル量子化を使い規模拡大可能なコーデックを学習
SoundStreamのエンコーダーは、不特定多数のベクトルを生成します。限られたビット数を使用してそれらを受信機に送信するには、ベクトル量子化と呼ばれるプロセスである有限集合(コードブックと呼ばれます)からの近接ベクトルに置き換える必要があります。
このアプローチは、約1kbps以下のビットレートでうまく機能しますが、それより高いビットレートを使用するとすぐに限界に達します。たとえば、ビットレートが3 kbpsと低く、エンコーダが1秒あたり100個のベクトルを生成すると仮定すると、10億個を超えるベクトルを含むコードブックを保存する必要がありますが、これは実際には実行不可能です。
SoundStreamでは、いくつかのレイヤー(実験では最大80)で構成される新しい残余ベクトル量子化器(RVQ:Residual Vector Quantizer)を提案することで、この問題に対処します。最初のレイヤーは中程度の解像度でコードベクトルを量子化し、次の各レイヤーは前のレイヤーからの残余エラーを処理します。 量子化プロセスをいくつかのレイヤーに分割することにより、コードブックのサイズを大幅に削減できます。例として、3 kbpsで毎秒100ベクトル、5つの量子化層を使用すると、コードブックのサイズは10億から320になります。さらに、量子化層をそれぞれ追加または削除することで、ビットレートを簡単に増減できます。
3.SoundStream:ビットレート可変なニューラルオーディオコーデック(1/2)関連リンク
1)ai.googleblog.com
SoundStream: An End-to-End Neural Audio Codec
2)arxiv.org
SoundStream: An End-to-End Neural Audio Codec
3)google-research.github.io
Audio samples for “SoundStream: An End-to-End Neural Audio Codec”

