
1.Google Research:2019年の振り返りと2020年以降に向けて(6/8)まとめ
・従来は分割して段階的に行った作業を大規模ニューラルネットワークで一気にやる事が主流になりつつある
・これらの研究結果はBERTの検索エンジンへの投入を初め実世界で使われるようになってきている
・機械による知覚は静止画像から動画やライブ性、意味や複雑な状況の把握などに対象が移ってきている
2.自然言語の理解と機械による知覚
以下、ai.googleblog.comより「Google Research: Looking Back at 2019, and Forward to 2020 and Beyond」の意訳です。元記事の投稿は2020年1月9日、Google Research部門トップのJeff Deanさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Benjamin Davies on Unsplash
(11)自然言語の理解
過去数年間、AIは自然言語の理解、翻訳、自然な対話、音声認識、および関連タスクで著しく進歩しました。去年、私たちの仕事のテーマの1つは、様式またはタスクを組み合わせて、より強力で有能なモデルを訓練し、最先端の領域を押し上げる事でした。
いくつかの例:
・「Exploring Massively Multilingual, Massive Neural Machine Translation」では、100のモデルを個別に用意するのではなく、100の言語間の翻訳を可能にする単一のモデルをトレーニングすることで、翻訳品質の大幅な向上を示しました。
![]()

左:利用可能な学習用データの量が多い言語同士での翻訳は、一般に翻訳品質が高くなります。
右:言語ペア毎に個別のモデルを学習させるのではなく、全ての言語ペアに対して単一のモデルをトレーニングする多言語トレーニングアプローチにより、利用可能な学習データが少ない言語ペアでもBLEUスコア(翻訳品質の尺度)を大幅に向上しました。
・「Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model」では、音声認識と言語モデルを組み合わせて、多くの言語でシステムをトレーニングする事により、音声認識の精度が大幅に向上することを示しました。
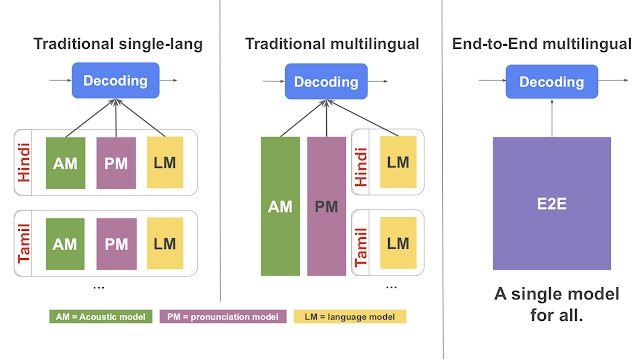
左:各言語を、音響モデル、発音モデル、言語モデルの3つに分割するアプローチで構成した従来の単一言語用音声認識装置
中:音響および発音モデルを多言語化し、言語モデルは言語固有とした従来の多言語音声認識装置
右:E2E多言語音声認識プログラム。音響、発音、言語モデルを単一の多言語モデルに統合しています。
・「Translatotron: An End-to-End Speech-to-Speech Translation Model」では、音声認識タスクと翻訳タスクと合成音声タスクを同時に行う合成モデルをトレーニングできることを示しました。これらのタスクは通常は別々のモデルとしてトレーニングされます。しかし、合成モデルで実現する事により、合成音声に元の話者の声色を保持可能になるだけでなく、よりシンプルな学習システムを実現できます。
・「Multilingual Universal Sentence Encoder for Semantic Retrieval」では、多くの異なる目的に流用可能な非常に優れたモデルを生成する方法を示しました。文章や単語の類似性を捕捉しているため、単純な単語照合手法に比べて、文章の意味を考慮するセマンティック検索で特に力を発揮します。例えば、Google Talks to Booksで「どんな香り(fragrance)が思い出を呼び戻しますか?」という検索を行うと「私にとっては、ジャスミンとパンの袋の匂い(smell)は、気楽な子供時代全体を呼び起こします」という結果になります。
(訳注:つまり、従来の単語照合手法だと「香り(fragrance)」と「匂い(smell)」は完全別物として扱われますが、文章の意味を考慮出来ているのでこういった回答が可能になったと言う事です。
・「Robust Neural Machine Translation」では、敵対的なトレーニング手法を使用して、言語翻訳の品質と堅牢性を大幅に向上させる方法を示しました。


上図:Transformerモデルが入力文に適用されます(左下)。ターゲット出力文(右上段)とターゲット入力文(右下段、「<sos>」で始まっている文章)と組み合わされ翻訳損失が計算されます。AdvGen関数は、入力文、単語選択分布、単語候補、および翻訳損失を入力として受け取り、敵対的な入力文を構築します。
下図:防御ステージでは、敵対的な入力文がTransformerモデルへの入力として機能し、変換損失が計算されます。次に、AdvGenは上記と同じ方法を使用して、ターゲット入力から敵対的な文章例を生成します。
・seq2seq、Transformer、BERT、Transformer-XL、ALBERTモデルなどの基本的な研究の進歩に基づいて、言語理解能力が向上しました。Google翻訳、GmailのSmart Compose、Google検索などの主要な製品や機能の多くで、この種のモデルの使用が増えています。今年、コア検索アルゴリズム及びランキングアルゴリズムでBERTを採用した事により、検索時に入力される文章や単語、フレーズの微妙な違いをよりよく理解する事が出来るようになり、検索品質が過去5年間で最大の(過去最大級の)向上を見せました。
(12)機械による知覚
静止画像をよりよく理解するモデルは、過去10年間で著しい進歩を遂げました。次の主要なフロンティアには、動的な世界をきめ細かく理解するためのモデルとアプローチがあります。このためには、画像やビデオをより深く、より微妙なニュアンスを理解だけでなく、録画データではないライブデータを扱う事や状況を認識する事などが必要になってきます。対話的に行動する事が十分可能な早い反応速度で視覚と聴覚が関わる世界を理解し、ユーザーと空間的基盤を共有する事が必要になるのです。今年、私たちはこの分野の進歩の多くの側面を調査しました。
・Google Lensを使ったきめ細かい視覚理解。更に強力な視覚を使った検索を可能にします。
(訳注:カメラに写した物体をよりきめ細かく画像検索できるだけでなく、それを3Dモデルとして撮影風景内で動かしたりする事なども出来るようになりました)
・Nest Hub Maxのクイックジェスチャ、フェイスマッチ、スマートビデオコールフレーミングなどの便利なスマートカメラ機能
(訳注:Nest Hubはスマートディスプレイと言われる製品群で、フェイスマッチは顔を認識してその人用のカレンダーを自動で表示したりする機能です)
・Google Lensを介してライブデータを認識して私たちの周りの世界を有益に補強するテクノロジー
(訳注:Google Lensで新幹線のチケットを映すと日本語による説明書きが英語に翻訳されたARチケットがカメラ内に表示されたりします)
・ビデオデータから奥行情報を予測するためのより良いモデル
(訳注:従来は大変困難であったカメラと被写体が同時に動くような状況でも奥行情報を推測できるようになりました)
・時間的サイクルの一貫性を利用した、動画をきめ細かく時間的に理解するためのより良い特徴表現
(訳注:動画に写っている繰り返し動作の類似性を認識するような事も出来るようになりました、詳細は下図)

右図:スクワットを行う人々のビデオを入力としています。
左上のビデオが元となる参照用動画です。それ以外のビデオは、スクワットをしている人々を撮影した他のビデオからフレームを抜き出して表示させた動画です。参照用動画に(TCC embedding空間内で)最も似ていると判断されたフレームを表示させています。
左図:スクワットが実行されるにつれと、右側の各動画に対応するembeddingの二次元表示がほぼ同じタイミングで移動していきます。
・「時間的に一貫性を持つが内容を説明するラベルが付与されていない動画」から、テキスト、音声、動画に関する特徴表現を学習
訳注:Wikipedea等の文章の一部を削除して穴埋め問題を作り、穴埋め問題を大量に学習させた結果、BERTは文脈を理解する事が出来るようになり脚光を浴びました。大量のレシピ動画を使って同様の事を行ったのがVideo BERTです。下ごしらえ時点の画像を見て次に必要になる料理工程を予測したり、料理工程を撮影した画像に対して説明文を付与する事が出来るようになりました。

クッキングビデオを使った事前トレーニングを受けたVideoBERTを定性的に評価した結果
上:いくつかのレシピに関する文章を指定すると、VideoBERTはそのテキストに関連する一連のビジュアルトークンを生成できます。
下:ビジュアルトークンを与えた際に、VideoBERTが予測した(異なる経過時間の)上位3つのビジュアルトークン。この場合、モデルは、小麦粉とココアパウダーのボウルがオーブンで焼かれ、ブラウニーまたはカップケーキになる可能性があると予測しています。ビジュアルトークンは厳密には画像ではありませんが、特徴空間上で指定されたビジュアルトークンに最も近いトレーニングセットの画像を使用して人間が画像として確認できるようにしています。
・過去の観測値から将来の視覚入力を予測する強化学習
(訳注:強化学習でゲームをプレイさせると最終的に人間より上手にプレイするようになりますが上達までに非常に時間がかかる事の解決にチャレンジした研究でした)
・ビデオに映った行動をよりよく理解できるモデル。Googleフォトで「ろうそくを吹き飛ばす」、「滑り台を滑り落ちる」などのビデオの特別な瞬間をよりよく思い出すことができます。
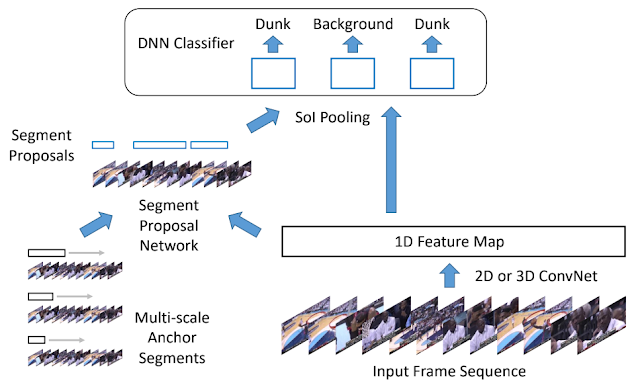
時間と共に変遷する行動を局所化するアーキテクチャ
私達は、AIが私たちの身の周りの感覚や現実世界を理解する能力を継続的に改善していく見通しに非常に興奮しています。
3.Google Research:2019年の振り返りと2020年以降に向けて(6/8)関連リンク
1)ai.googleblog.com
Google Research: Looking Back at 2019, and Forward to 2020 and Beyond
2)research.google
Publication database(2019)
Optimization of Molecules via Deep Reinforcement Learning
AVA
3)modelcards.withgoogle.com
Object Detection Model Card v0 Cloud Vision API
4)ai.google
Working together to apply AI for social good
5)blog.google
Using AI to give people who are blind the “full picture”
What our quantum computing milestone means
Teachable Machine 2.0 makes AI easier for everyone
Google for Startups Accelerator empowers AI startups in Europe
6)support.google.com
Get image descriptions on Chrome
7)federated.withgoogle.com
Federated Learning An online comic with google AI
8)arxiv.org
The Evolved Transformer
9)www.isca-speech.org
Improving Keyword Spotting and Language Identification via Neural Architecture Search at Scale
10)github.com
google / jax
11)leogao.dev
The Decade of Deep Learning
