
1.エンドツーエンドモデルによる多言語リアルタイム音声認識(1/2)まとめ
・音声データからニューラルネットワークが学習した「知識」の多くは他の言語に流用できる
・この洞察を元に利用可能な音声データが多い言語で学習した結果をマイナーな言語に転用する研究が発表
・RNN-Tモデルを使用してストリーミングE2E ASRを多言語化対応する事でリアルタイム処理も実現
2.多言語リアルタイム音声認識とは?
以下、ai.googleblog.comより「Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model」の意訳です。元記事の投稿は2019年9月30日、Arindrima DattaさんとAnjuli Kannanさんによる投稿です。
Googleの使命は、世界中の情報を整理するだけでなく、世界中の情報にアクセスできるようにすることです。これはつまり、Google製品ができるだけ多くの言語で動作するようにすることです。
人間の音声を理解する事、これはGoogle Assistantの中心機能ですが、これをより多くの言語に拡張する事は挑戦的な課題となります。
高品質の自動音声認識(ASR:automatic speech recognition)システムを開発するためには、大量の音声およびテキストデータが必要です。学習にデータを大量に必要とするニューラルモデルが様々な分野に革命を起こし続けていますが、多くのマイナーな言語では利用可能なデータはほとんどありません。
データが不足している言語でも、音声認識の品質を高く保つ事をどうすれば実現できるかを疑問に思いました。
研究コミュニティが見出した重要な洞察は、「利用可能なデータが豊富な言語」の音声データからニューラルネットワークが学習した「知識」の多くは、「利用可能なデータが少ない言語」で再利用できるということでした。
全てをゼロから学ぶ必要はありません。これは、単一のモデルで複数の言語の転記を学習する多言語音声認識を研究する動機となりました。
Interspeech 2019で公開された論文「Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model」では、単一モデルとしてトレーニングされたエンドツーエンド(E2E)システムでありながらリアルタイムで多言語音声認識を可能にするシステムを紹介します。9つのインド国内で使われている言語を使用して、データが豊富な言語でパフォーマンスを改善しながら、いくつかのデータの少ない言語のASRの品質を劇的に改善できる事を実証しました。
インド:多言語の国
この研究では、少なくとも100万人のネイティブスピーカーがいる30以上の言語が存在する、本質的に多言語社会であるインドに焦点を当てました。これらの言語の多くは、ネイティブスピーカー間で地理的近接性と文化史を共有しているため、音響的にも語彙的にも重複しています。更に、多くのインド人はバイリンガルまたはトライリンガルであり、会話内で複数の言語を使用することは一般的な現象であり、単一の多言語モデルをトレーニングする自然なケースです。
この作業では、ヒンディー語、マラーティー語、ウルドゥー語、ベンガル語、タミル語、テルグ語、カンナダ語、マラヤーラム語、グジャラート語の9つの主要なインド言語を組み合わせました。
ストリーミングにも対応可能な全ニューラルマルチリンガルモデル
従来のASRシステムは、音響モデル、発音モデル、言語モデル用と3つの個別のコンポーネントで構成されています。
従来のASRコンポーネントの一部または全てを多言語化しようとする試みは過去にありましたが、このアプローチは複雑で規模を大きくして実行する事が難しい場合があります。E2E ASRモデルは、3つのコンポーネント全てを単一のニューラルネットワークに結合し、規模の拡大とパラメーターの共有を容易にします。
最近の研究では、E2Eモデルを多言語に拡張する試みがされましたが、リアルタイム音声認識のニーズを満たしていません。リアルタイム音声認識はパーソナルアシスタント、音声検索、GBoardディクテーション(書き取り)などのアプリケーションをストレスなく実行するための要件となります。
このために、リカレントニューラルネットワークトランスデューサー(RNN-T)モデルを使用してストリーミングE2E ASRを実現するGoogleの最近の研究に注目しました。RNN-Tシステムは、まるで誰かがリアルタイムでキー入力しているかのように、一度に1文字ずつ単語を出力しますが、これは多言語化対応していませんでした。そのため、このアーキテクチャに基づいて、多言語音声認識用の低遅延モデルを開発しました。
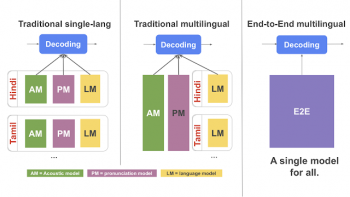
左図:各言語の音響、発音、言語モデルで構成される従来の単一言語音声認識装置。
中図:音響および発音モデルが多言語で、言語モデルが言語固有である従来の多言語音声認識装置。
右図:E2E多言語音声認識プログラム。音響、発音、言語モデルが単一の多言語モデルに結合されています。
3.エンドツーエンドモデルによる多言語リアルタイム音声認識(1/2)関連リンク
1)ai.googleblog.com
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
2)arxiv.org
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
