
1.SimPLe:ビデオモデルを用いてポリシー学習をシミュレート(1/2)まとめ
・現在の強化学習の問題点の1つは人間に比べて学習に非常に時間がかかる事である
・人間が効率的に学習できる理由は世界モデルを持っているからと推測されている
・モデルベース強化学習のフレームワークであるSimPLeを使う事で学習時間の短縮が可能
2.SimPLeとは?
以下、ai.googleblog.comより「Simulated Policy Learning in Video Models」の意訳です。元記事は2019年3月25日、Łukasz KaiserさんとDumitru Erhanさんによる投稿です。
深層強化学習(RL)技術は、視覚入力を元に複雑なタスクの作業方針(ポリシー)を学ぶ事ができ、これを応用して昔のAtari社のビデオゲームを大変上手にプレイさせる事に成功しています。
この分野における最近の研究は、Montezuma’s Revenge(訳注:日本で言えばスぺランカー的な主人公がすぐ死ぬ難度の高いゲームで人間にも突破不可能と言われた面を2018年に人工知能が突破した事で話題になった)によって示されたように挑戦的な領域においてさえも、それらの多くにおいて超人的な性能を発揮できることを示しました。
しかしながら、多くの最先端のアプローチの限界の1つはそれらがゲーム環境との非常に多数のやりとりを必要(訳注:つまり長時間プレイする必要がある)とすることです、そして、それはしばしば人間がゲームを上手にプレー出来るようになるために必要な時間よりずっと長いです。
なぜ人間がこれらのタスクをはるかに効率的に学習できるのかを説明するもっともらしい仮説は、人間は自分自身の行動の効果を予測することができるので、どのような順番で行動する事が望ましい結果に繋がるか暗黙的に学習していると言う説です。
この一般的なアイデア(いわゆるゲームのモデルを構築し、それを使用してアクションを選択するための適切なポリシーを習得すること)は、モデルベースの強化学習(MBRL:Model-Based Reinforcement Learning)の主な前提です。
論文、「Model-Based Reinforcement Learning for Atari」では、Atariのゲームをプレイする人工知能を訓練するMBRLフレームワークであるSimulated Policy Learning(SimPLe)アルゴリズムを紹介しています。ゲーム環境とのやり取りは、たった約10万回です(人間のプレーヤーによる約2時間のプレイに相当)。
また、tensor2tensorオープンソースライブラリの一部として、コードをオープンソース化しました。 このリリースには、単純なコマンドラインで実行でき、Atari風のインターフェースを使用して実行できる、事前学習済みのワールドモデルが含まれています。
SimPLeで世界モデルを学ぶ
大ざっぱに言うと、SimPLeの背後にある考え方は、「ゲームのルールを世界モデルとして学ぶ事」と、「シミュレートされたゲーム環境内でそのモデルとMBRLを用いてポリシーを最適化する事」を交互に行うことです。このアルゴリズムの背後にある基本原理は十分に確立されており、最近の多数のモデルベースの強化学習法で採用されています。
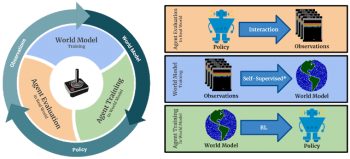
SimPLeのメインループ。 1)エージェントは現実世界の実際の環境と対話します。 2)収集された観測値を現在の世界モデルを更新するために使用します。 3)エージェントは、世界モデル内で学習することによってポリシーを更新します。
Atariのゲームのプレイモデルを訓練するには、まず最初に将来のもっとも確からしいバージョンをピクセル空間(pixel space)で生成する必要があります。言い換えれば、私達は、入力として、既に観察された一連のフレームと「左」、「右」などのゲームに与えられたコマンドを選択することによって、次のフレームがどのようになるかを予測しようとします。観測空間で世界モデルを訓練する事が重要である理由の1つは、それが自己教師の形式であり、観測(ここではピクセル)が密で豊かな教師信号を形成することです。
そのようなモデル(例えば、ビデオ予測)を用いてトレーニングに成功した場合、このモデルは本質的に、エージェントが優れたポリシーを作成し続けるために使用することができるゲーム環境のシミュレータと言えます。例えば、エージェントは長期的な報酬が最大になるように一連の行動を選択する事ができます。
言い換えれば、時間と計算機パワーの双方が必要な実際のゲームでポリシーをトレーニングさせる代わりに、ワールドモデル/学習シミュレータでポリシーをトレーニングできるのです。
3.SimPLe:ビデオモデルを用いてポリシー学習をシミュレート(2/2)関連リンク
1)ai.googleblog.com
Simulated Policy Learning in Video Models
2)arxiv.org
Model-Based Reinforcement Learning for Atari
3)github.com
tensorflow/tensor2tensor
