
1.TALNet:Google Photosで動画から特別な瞬間を切り出す(1/2)
・Google Photosでアップされた動画から自動で印象的なシーンを切り出す事が可能になった
・これを実現しているTALNetは画像から物体を効率的に検出するFaster R-CNNからヒントを得ている
・最初に印象的なシーンが含まれる動画の範囲を特定し、次にその範囲が印象的か否かを特定する
2.TALNetとは?
以下、ai.googleblog.comより「Capturing Special Video Moments with Google Photos」の意訳です。元記事は2019年4月3日、Sudheendra VijayanarasimhanさんとDavid Rossさんによる投稿です。
思い出に残る瞬間をスマホでビデオとして撮影し、友人や愛する人と共有することは珍しい事ではなくなりました。しかし、撮影したビデオを沢山持っている人なら誰でも同意しますが、家族や友人と追体験したり共有したりするために、印象的なシーンを動画から探して切出すのは時間のかかる作業です。
Google Photosでは、お子様がろうそくの火を吹き消した瞬間や友人がプールに飛び込んだ瞬間など、動画から印象的なシーンを自動的に見つけ出し、短い動画として切り出してアニメーション画像を作成し、友人や家族と簡単に共有する事ができます。
論文「Rethinking the Faster R-CNN Architecture for Temporal Action Localization」では、このタスクを自動化する際に解決が必要な課題を論じています。この課題には、入力データ(つまり動画の撮影内容や長さ)が大きく変動する状況で、印象的なアクションを識別し、分類し、そこからアクションが発生したビデオ内の正確な位置を特定する事の困難さが含まれます。
訳注:注目に値する特定のアクションが発生したか否かの判定は、既にGoogle ClipsやPixel3のTop Shotで磨かれてきた技術ですが、今回の研究では、長さが定まっていない動画に対して、特別な行動であるか否かの判定と同時に「その行動は元動画のどこからどこまでの範囲に写っているのか?」を特定しなければならず、これを効率的に行った事が主題です。
私達のTALNet(Temporal Action Localization Network)は、Faster R-CNNネットワークのような、画像から物体を検出する物体検出手法の進歩からインスピレーションを得ています。TALNetを使用すると、時間の経過よるばらつきが大きい動画データから特別な瞬間を従来手法比で最高効率で識別し、Google Photosでビデオからビデオの最適な部分を切り抜いて、友人や家族と共有できます。

検出されたアクションの例「ろうそくの火を吹き消す」
特別な瞬間を識別するためにモデルを訓練する
ビデオで特別な瞬間を識別する最初のステップは、人々が強調したいと思うかもしれない行動のリストを集めることです。 行動のいくつかの例は、「誕生日の蝋燭の火を吹き消す」、「ボウリングでストライクを取る」、「揺れ動く猫のしっぽ」などが含まれます。
次に、大規模なトレーニングデータセットを作成するために、これらの特定のアクションが発生した共有動画コレクションを短い動画に分割し、クラウドソーシングを利用してラベルを付けました。私たちは評価者に、特定の瞬間を見つけてラベルを付ける事と、特定の瞬間が含まれている可能性がある動画を選別して注釈を付ける事を依頼しました。この後者の注釈付きデータセットは、新しい未知のビデオで目的のアクションが識別できるように、モデルをトレーニングするために使用されました。
物体検出との比較
これらの特定の行動を認識する事は、時間的行動の局所化(temporal action localization)として知られるコンピュータビジョンの研究分野に属し、それは、より身近な物体検出と同様の視覚的検出問題の範疇です。
入力として長いトリミングされていないビデオが与えられたとしましょう。時間的行動の局所化とは、元ビデオの中に各アクション(ろうそくの火を吹き消す)が存在するかラベル付けし、及びそのアクションの開始時間と終了時間を特定する事が目的となります。
物体検出は、画像内(二次元データ)のオブジェクトの周囲に境界ボックスを生成することを目的としていますが、時間的行動の局所化は、連続するビデオフレーム(一次元データ)から特定動作が含まれた断片を生成することを目的とします。
TALNetでの私達のアプローチは、二次元画像でより速い物体検出が可能なFaster R-CNNオブジェクト検出フレームワークに触発されています。そのため、TALNetを理解するためには、Faster R-CNNを最初に理解する事が有用です。
以下の図は、Faster R-CNNアーキテクチャが物体検出にどのように使用されているかを示しています。 最初のステップは、分類に使用できる一連のオブジェクトを提案、つまり画像のなかから識別対象となる領域を抽出することです。これを行うために、入力画像は、まず畳み込みニューラルネットワーク(CNN)によって二次元の特徴量マップに変換されます。次に、領域提案ネットワーク(Region Proposal Networks)は候補オブジェクトの周囲に境界ボックスを生成します。これらのボックスは、自然画像ではオブジェクトのサイズが大きく変動する事を考慮して複数の縮尺で生成されます。
識別すべき領域が定義されたので、境界ボックス内の物体は、ディープニューラルネットワーク(DNN)によって、「人」、「自転車」などの特定のオブジェクトに分類されます。
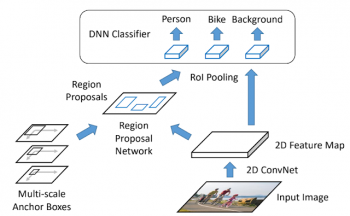
物体検出のためのFaster R-CNNアーキテクチャ
時間的行動の局所化(Temporal Action Localization)
時間的行動の局所化は、R-CNNと同様な手法で達成されます。ビデオの一連の入力フレームは、最初に場面を符号化した一連の1D特徴マップに変換されます。このマップは、開始時間と終了時間を見つけて特定の行動を写った動画の一部を切り出すセグメント提案ネットワーク(segment proposal network)に渡されます。
次に、セグメント提案ネットワークは、トレーニングデータセットから学習した特徴表現を使って、切り出された動画内のアクションを分類します。(たとえば、「スラムダンク」、「パス」など)。各動画内で識別された行動は、学習済み特長表現を用いてスコア付けされ、最高得点を得た瞬間がユーザと共有するように選択されます。
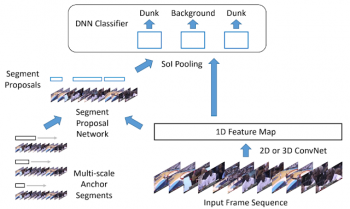
時間的行動の局所化のためのアーキテクチャ
3.TALNet:Google Photosで動画から特別な瞬間を切り出す(1/2)
1)ai.googleblog.com
Capturing Special Video Moments with Google Photos
2)arxiv.org
Rethinking the Faster R-CNN Architecture for Temporal Action Localization

コメント