
1.Google Research:2022年以降にAIはどのように進化していくか?(2/6)まとめ
・新ハードウェアやアルゴリズムの改良、学習手法の進歩によってMLの効率性が継続的に向上
・最先端の性能を維持または改善しながら、計算量や速度、CO2換算排出量の削減が可能
・今後も大規模高品質モデルを効率よく開発する手法は進化し、利用しやすさが向上する見込み
2.機械学習モデルの効率を改善する試み
以下、ai.googleblog.comより「Google Research: Themes from 2021 and Beyond」の意訳です。元記事は2022年1月11日、Jeff Deanさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Michael Held on Unsplash
MLの継続的な効率化
新しいコンピュータハードウェアの設計やMLアルゴリズムの改良、メタ学習研究の進歩による効率性の向上は、MLモデルの能力を高める原動力となっています。
MLパイプラインの多くの側面は、全体として最先端の性能を維持または改善しながら、効率化のために最適化することが可能です。効率的化の対象には、モデルが学習・実行されるハードウェアからMLアーキテクチャの個々の部品が含まれます。
これらの異なる最適化対象はそれぞれ桁違いに効率を向上させることができ、それらを合わせるとわずか数年前と比較して、CO2換算排出量(CO2e:CO2 equivalent emissions)を含む計算コストを大幅に削減することができます。
このような効率性の向上により、今後も機械学習の効率を劇的に向上させ、より大規模で高品質なモデルをコスト効率よく開発し、利用しやすさをさらに進めるための重要な進歩がいくつも実現されています。このような研究の方向性に、私はとても期待しています
(1)ML専用ハードウェアの継続的な性能向上
MLアクセラレータは世代を重ねるごとに、チップあたりの性能を向上させ、システム全体の規模を拡大しています。
昨年、GoogleのTensor Processing Unitの第4世代であるTPUv4システムを発表しましたが、MLPerfベンチマークにおいて、同等のTPUv3の結果よりも2.7倍向上していることが実証されました。
TPUv4チップの1チップあたりのピーク性能はTPUv3チップの約2倍、TPUv4ポッドの規模は4096チップ(TPUv3ポッドの4倍)で、ポッドあたり約1.1エクサフロップス(exaは10の18乗、TPUv3ポッドは約100ペタフロップス。メガ、ギガ、テラ、ペタ、エクサの順番)の性能を実現しています。より多くのチップを搭載したポッドを高速ネットワークで接続することで、大規模なモデルの処理効率が向上します。
モバイル端末のML機能も大きく向上している。Pixel 6携帯は、強力なMLアクセラレータを統合した全く新しいGoogle Tensorプロセッサを搭載し、デバイス上の重要な機能をより良くサポートしています。

左:TPUv4の基板
中央:TPUv4ポッドの一部
右。Pixel 6スマホに搭載されたGoogle Tensorチップ
私たちがMLを利用してあらゆる種類のコンピュータチップの設計を加速していることも、特に優れたMLアクセラレータの製造に役立っています。(詳細は後述します)。
(2)MLコンパイルの継続的な改善とMLワークロードの最適化
ハードウェアを変更せずとも、機械学習用アクセラレータ用に最適化したコンパイラなどのシステムソフトウェアの最適化を改善することで、大幅な効率アップにつながります。
例えば、論文「A Flexible Approach to Autotuning Multi-pass Machine Learning Compilers」では、機械学習を利用してコンパイラの設定を自動でチューニングし、同じ基盤ハードウェア上のMLプログラム群に対して5~15%(時には2.4倍の改善)の全面的な性能改善を得る方法を示しています。
GSPMDは、XLAコンパイラーに基づく自動並列化システムです。ほとんどの深層学習ネットワークアーキテクチャをアクセラレーターに搭載されたメモリ容量を超えて拡張することが可能で、GShard-M4、LaMDA、BigSSL、ViT、MetNet-2、GLaMなどの多くの大規模モデルに適用されて、いくつかの領域で最先端の結果を導いています。
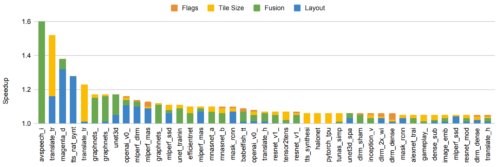
150のMLモデルで、MLベースのコンパイラ自動チューニングを使用した場合の速度向上の図。5%以上の高速化を達成したモデルを含みます。棒グラフは、モデルのさまざまなコンポーネントを最適化することによる相対的な改善度を示しています。
(3)人間の創造性に基づき、より効率的なモデルアーキテクチャを発見
モデルアーキテクチャの継続的な改善により、多くの問題で一定レベルの精度を達成するために必要な計算量が大幅に削減されました。例えば、2017年に開発したTransformerアーキテクチャは、いくつかのNLPおよび翻訳ベンチマークにおいて技術水準を向上させると同時に、LSTMや他のリカレントアーキテクチャなど、他の様々な普及手法に比べて10倍から100倍少ない計算量でこれらの結果を達成することが出来ました。
同様に、Vision Transformerは、畳み込みニューラルネットワークよりも4倍から10倍少ない計算量にもかかわらず、多くの異なる画像分類タスクで最先端の改善結果を示すことができました。
(4)より効率的なモデルアーキテクチャを機械主導で探索
ニューラル・アーキテクチャ・サーチ(NAS:Neural architecture Search)は、与えられた特定のタスクに対して、より効率的な新しいMLアーキテクチャを自動的に発見することができます。
NASの最大の利点は、探索空間と問題領域の組み合わせ毎に1回の作業で済むため、アルゴリズム開発に必要な労力を大幅に削減できることです。
さらに、NASを実行する際には計算コストがかかりますが、結果として得られるモデルは、下流の研究および生産環境における計算を大幅に削減し、全体として必要なリソースを大幅に削減することが可能です。
例えば、Evolved Transformerを発見するための1回の検索で発生したCO2eはわずか3.2トン(他の研究で報告されている284トンよりはるかに少ないです。GoogleとUC Berkeley共同論文の付録CとD参照)ですが、NLPコミュニティの誰もが使えるモデルを生み出し、素のTransformerモデルより15-20%効率が良くなっています。
さらに最近のNASの利用では、Primer(オープンソース化されています)と呼ばれるさらに効率的なアーキテクチャが発見され、単純なTransformerモデルと比較して学習コストを4倍削減することに成功しました。このように、NASの探索コストは、発見されたより効率的なモデルアーキテクチャの使用によって、たとえそれがほんの一握りの下流タスク用途にしか適用されないとしても、しばしば回収されます。(多くのNASの結果は数千回も再利用されています)
NASが発見したPrimerアーキテクチャは、単純なTransformerモデルと比較して4倍の効率性を持ちます。この画像は、Primerに大きな効果をもたらした2つの主な改良点を示しています(赤色部分。青はオリジナルのTransformer)
・深さ方向の畳み込みを attention multi-head projectionsに追加
・2乗ReLU活性化(squared ReLU activations)
また、NASは視覚領域において、より効率的なモデルを発見するために使用されています。EfficientNetV2モデルアーキテクチャは、モデルの精度、モデルサイズ、学習速度を共同で最適化するニューラルアーキテクチャ探索の結果、誕生したものです。EfficientNetV2は、ImageNetベンチマークにおいて、従来の最先端モデルよりもモデルサイズを大幅に削減しつつ、学習速度を5~11倍向上させることに成功しています。
CoAtNetのモデルアーキテクチャは、Vision Transformerと畳み込みネットワークのアイデアを用いたアーキテクチャ探索により、Vision Transformerの4倍の学習速度を実現しました。そして、CoAtNetはImageNetの最先端のスコアを達成するハイブリッドモデルアーキテクチャとなりました。
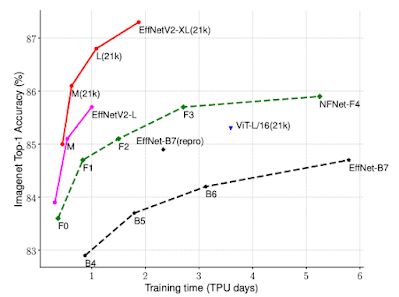
EfficientNetV2は、ImageNetの分類において、従来のモデルよりもはるかに優れた学習効率を達成しています。
MLモデルのアーキテクチャやアルゴリズムの改良にモデル探索が広く利用されていることから、強化学習や進化的手法など、他の領域の研究者もこの手法を異なる研究に適用することに意欲を燃やしています。
モデル検索を作成できるようにするために、私たちはModel Searchをオープンソース化しました。これは、他の研究者が自分の興味ある領域のためのモデル探索を探求することを可能にするプラットフォームです。
モデルアーキテクチャの探索に加えて、より効率的な強化学習アルゴリズムを見つけるために使用することもできます。これは、教師あり学習アルゴリズムを自動で発見してこのアプローチを実証した以前のAutoML-Zeroの研究に基づいています。
(5)スパース性の利用
スパース性(Sparsity)は、効率を大幅に改善できるもう一つの重要なアルゴリズム的進歩です。
スパース(疎)なモデルとは、与えられたタスク、データ、トークンに対してモデルの一部のみが活性化されるモデルであり、非常に大きな容量を持つ事ができます。
2017年、私たちはsparsely-gated構造とmixture-of-experts層を導入し、これまでの最新鋭の高密度LSTMモデルよりも10倍少ない計算量で、さまざまな翻訳ベンチマークでより良い結果を実証しました。
さらに最近、Mixed-of-ExpertsスタイルのアーキテクチャとTransformerモデルアーキテクチャを組み合わせたSwitch Transformerが、dence(密)なT5-Base Transformerモデルに比べて学習時間と効率が7倍高速化されることを実証しました。
GLaMモデルでは、Transformerとexperts混合型レイヤーを組み合わせることで、29のベンチマークにおいて、学習に3倍少ないエネルギー、推論に2倍少ない計算量で、GPT-3モデルの精度を上回るモデルを生成できることが示されました。また、スパース性という概念は、Transformerのコアとなるattentionメカニズムのコストを削減するために適用することができます。
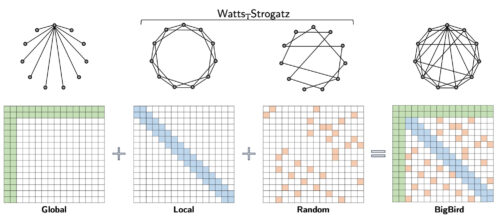
BigBirdの疎なattentionモデルは、入力シーケンス全体に注意を払うグローバルトークンと、ローカルトークン、およびランダムトークンのセットで構成されています。理論的には、Watts-Strogatzグラフ上に少数のグローバル・トークンを追加していると解釈できます。
モデルにスパース性を持たせることは、計算効率の面で非常に高い効果が期待できるアプローチであることは明らかで、この方向で試される研究のアイデアについては、まだ表面的な部分しか見えていません。
これらの効率化のためのアプローチを組み合わせることで、「現在の効率的なデータセンターでトレーニングされた同等の精度の言語モデル」は、「平均的な米国のデータセンターでP100 GPUを使ってトレーニングしたベースラインのTransformerモデル」と比較して、エネルギー効率が~100倍、CO2e排出量が~650倍少なくなります。
この数値は、Googleが使用している100%再生可能エネルギーの補正を考慮に入れていません。Googleは二酸化炭素排出量を相対的に0にするカーボンニュートラルを目指すために100%再生可能エネルギーを使用する取り組みをしています。
NLPモデルの炭素排出の傾向を分析した、より詳細なブログ記事を近日中に掲載する予定です。
3.Google Research:2022年以降にAIはどのように進化していくか?(2/6)関連リンク
1)ai.googleblog.com
Google Research: Themes from 2021 and Beyond
