
1.データセンター内のBERTに匹敵する性能を持つPixel 6搭載の言語モデル(1/3)まとめ
・Google TensorはGoogleのAI原則に沿ってMLモデルを実行するために最適化されている
・ニューラルアーキテクチャ探索を使用してMLモデルの設計プロセスを自動化した
・候補となるネットワークを抽出するための探索空間の設計を工夫してGC-IBNを用いた
2.Pixel 6搭載のGoogle Tensor
以下、ai.googleblog.comより「Improved On-Device ML on Pixel 6, with Neural Architecture Search」の意訳です。元記事は2021年11月8日、Suyog GuptaさんとMarie Whiteさんによる投稿です。
機械学習モデルをハードウェアに最適化する事はPixel 2の頃からやってましたが、Pixel 6はモデルが最適化してくる事を見越してハードウェア設計もやっているんですね。
アイキャッチ画像のクレジットはPhoto by Shardar Tarikul Islam on Unsplash
今年の秋に発売されたPixel 6スマートフォンには、Google初のモバイル用システムオンチップ(SoC:system-on-chip)であるGoogle Tensorが搭載されました。Google Tensorは、様々な処理コンポーネント(セントラル/グラフィック/センサーなどの演算処理装置ユニット、イメージプロセッサなど)を1つのチップにまとめ、Pixelユーザーに機械学習(ML:Machine Learning)の最先端のイノベーションを提供するためにカスタムメイドされたものです。
実際、Google Tensorのあらゆる側面は、GoogleのAI原則に沿って、GoogleのMLモデルを実行するために設計・最適化されています。それは、Google Tensorに統合されたカスタムメイドのTPUから始まり、Pixel スマートフォンで何が可能であるべきかという私たちのビジョンを実現することができます。
本日は、Google TensorのTPU向けにMLモデルを設計することで実現した、オンデバイス機械学習の改善についてご紹介します。
私たちは、ニューラルアーキテクチャ探索(NAS:Neural Architecture Search)を使用してMLモデルの設計プロセスを自動化しています。NAS実行時には、応答時間と電力の要件を満たしつつ、より高い品質を実現するモデルを発見するよう、検索アルゴリズムにインセンティブを与えています。
また、この自動化により、デバイス上のさまざまなタスクに対するモデルの開発を拡張することができます。研究者や開発者がPixel 6での様々な使い方を実現する開発を行えるように、TensorFlowモデルガーデンとTensorFlow Hubを通じてこれらのモデルを公開しています。さらに、同じ技術を適用して、多くのPixel 6カメラ機能の基礎となる、エネルギー効率の高い顔検出モデルを構築しました。

TPUに最適化されたモデルを見つけるためのNASの図解
各列はニューラルネットワークの段階を表し、ドットは異なるオプションを、各色は異なるタイプの土台を表しています。
入力(例えば画像)から出力(例えば画素毎のラベル予測)までの行列の道筋が、ニューラルネットワークの候補を表しています。探索の各反復において、各段階で選択された土台を用いてニューラルネットワークが形成され、探索アルゴリズムは、TPUの応答時間および/または使用電力を最小化し、かつ精度を最大化するニューラルネットワークを共同で見つけることを目的としています。
視覚モデルの探索空間の設計
NASの重要な要素は、候補となるネットワークを抽出するための探索空間の設計です。私達はNASをGoogle Tensor TPU上で効率的に動作するニューラルネットワークの土台を含むようなネットワークを見つけるように探索空間をカスタマイズしています。
スマートフォンなどのデバイス上のさまざまな視覚タスクのために使われるニューラルネットワークで広く使用されている土台の1つに、Inverted Bottleneck(IBN)があります。
IBNブロックには、それぞれトレードオフが異なるいくつかのバリエーションがあり、通常の畳み込み層と深さ方向の畳み込み層を用いて構築されています。深度方向の畳み込みを行うIBNは、計算量が少ないため、従来、モバイルビジョンモデルに使用されてきました。しかし、深度方向の畳み込みを通常の畳み込みに置き換えたFused-IBNは、TPU上の画像分類モデルや物体検出モデルの精度と応答時間を向上させることが示されています。
しかし、Fused-IBNは視覚モデルの典型的なニューラルネットワーク層の形状では後半レイヤーで法外に高い計算量とメモリを必要とする場合があり、モデル全体を使用する事は制限され、唯一の代替手段としては深度方向のIBN(depthwise-IBN)が残されています。
この限界を克服するために、私達はモデル設計の柔軟性を高めるためにグループ畳み込み(group convolutions)を使用するIBNを導入します。通常の畳み込みは、入力のすべての特徴表現に情報を混ぜ合わせますが、グループ畳み込みは、特徴をより小さなグループに切り分け、そのグループ内の特徴表現に対して通常の畳み込みを行うことで、全体の計算コストを削減します。
グループ畳み込みベースのIBN(GC-IBN:group convolution–based IBNs)と呼ばれるこの手法は、モデルの品質に悪影響を及ぼす可能性があるトレードオフを持ちます。
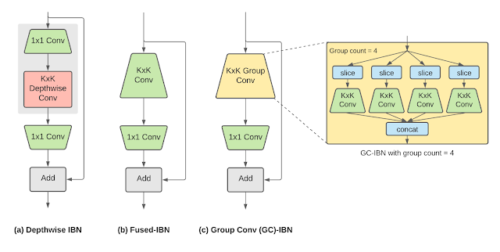
Inverted bottleneck(IBN)の変種
(a)depthwise-IBN(フィルタサイズKxKの深さ方向の畳み込み層を、フィルタサイズ1×1の2つの畳み込み層で挟む)
(b)fused-IBN(畳み込みと深さ方向の畳み込みを、フィルタサイズKxKの畳み込み層に融合する)
(c)fused-IBNのKxKの通常の畳み込みをグループ畳み込みに置き換える、グループ畳み込みベースのGC-IBN。グループの数(group count)は、NASの中で調整可能なパラメータです。
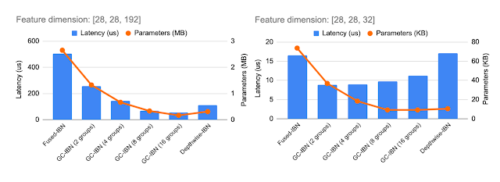
GC-IBNをオプションとして組み込むことで、他のIBNよりも柔軟性が増します。異なるIBNバリエーションの計算コストと応答時間は、処理される特徴量の次元に依存します(特徴次元例を2つ上に示します)。私たちは、NASを用いてIBNの最適な選択を行っています。
3.データセンター内のBERTに匹敵する性能を持つPixel 6搭載の言語モデル(1/3)関連リンク
1)ai.googleblog.com
Improved On-Device ML on Pixel 6, with Neural Architecture Search

