
1.BigBird:疎なAttentionでより長い連続データに対応可能なTransformer(1/2)まとめ
・Transformerは最新のNLP研究の中核技術で様々な連続する入力データに柔軟に適応できる
・しかし従来のTransformerは入力データの長さに二次関数的に比例してメモリと計算量が増加
・入力データの長さに線形に比例するスパース(疎らな)トランスフォーマーの研究を行った
2.拡張トランスフォーマー構造とは?
以下、ai.googleblog.comより「Constructing Transformers For Longer Sequences with Sparse Attention Methods」の意訳です。元記事の投稿は2021年3月25日、Avinava Dubeyさんによる投稿です。
スパース化(まばら化)はTransformaer以外でもトレンドキーワードですね。ざっと上げるだけでも最近の関連記事には以下のものがあります。
ニューラルネットワークを疎にして推論を高速化
TensorFlow 3Dによる3Dシーンの理解
Google Mapで電気自動車用に充電場所を考慮した経路案内を実現
アイキャッチ画像は京都で撮影された巨鳥でクレジットはPhoto by vaea Garrido on Unsplash
BERT、RoBERTa、T5、GPT3などのTransformerに基づく自然言語処理(NLP:Natural Language Processing)モデルは、様々なタスクで成功し、最新のNLP研究の中心となっています。Transformerの汎用性と堅牢性は、Transformerが広く採用される主要な原動力であり、さまざまな連続するデータを処理するタスクに簡単に適応できるためです。文章翻訳、文章要約、文章生成などのseq2seqモデルとして、または感情分析、POSタグ付け、機械読解などのスタンドアロンエンコーダーなど様々な分野に適用が可能です。
Transformersの主な革新は、類似性を計算する自己Attentionメカニズムの導入です。入力シーケンス内の位置の全てのペアのスコアであり、入力シーケンスのトークンごとに並行して評価できるため、リカレントニューラルネットワークが持つ順次依存性を回避可能になり、TransformerはLSTMなどの従来のシーケンスモデルを大幅に上回ることができます。
ただし、従来のTransformerモデルとその派生版の制限は、完全な自己Attentionメカニズムの計算量とメモリ量の要件が厳しい事です。入力データの長さに二次関数的に比例して必要なメモリ量と計算量が増加してしまうのです。
一般的に利用可能な現在のハードウェアとモデルのサイズでは、これは通常、入力データを約512トークンまでの長さに制限し、質問応答、ドキュメントの要約、ゲノムフラグメントの分類など、より大きな連続データを扱う事が必要になるタスクにトランスフォーマーを直接適用できないようにします。
ここで、2つの自然な疑問が生じます。
(1)入力シーケンスの長さに線形に比例して計算要件とメモリ要件が増えるスパース(疎らな)モデルを使用して、2次完全トランスフォーマーの実証されている利点を達成する事は可能でしょうか?
(2)上記の線形トランスフォーマー(linear Transformers)が2次完全トランスフォーマー(quadratic full Transformers)の表現力と柔軟性を維持していることを理論的に示すことは可能でしょうか?
最近発表した2つの論文で、これらの質問の両方に取り組んでいます。EMNLP 2020で発表された「ETC: Encoding Long and Structured Inputs in Transformers」では、拡張トランスフォーマー構造(ETC:Extended Transformer Construction)を紹介しています。
ETCはまばらなAttentionを使用する新しい手法です。構造情報(structural information)を使用して、類似性スコアを計算するペアの数を制限します。これにより、入力長への2次依存性が線形に減少し、NLPドメインで強力な実証的結果が得られます。
次に、NeurIPS 2020で発表された「BigBird:Transformers for Longer Sequences」で、もう一つのスパースAttention手法を紹介します。
BigBirdと呼ばれるこの手法は、より一般的なシナリオにETCを拡張します。すなわち、ETCの前提条件であった元データ内に存在する構造に関する専門知識が利用できない際も対応できるようにします。
更に、理論的には、提案されたスパースAttentionメカニズムが2次フルトランスフォーマーの表現力と柔軟性を維持することも示しています。私たちが提案する方法は、質問応答、ドキュメントの要約、ゲノムフラグメントの分類など、挑戦的なロングシーケンスタスクで新しい最先端技術を実現します。
グラフとしてのAttention
Transformerモデルで使用されるAttentionモジュールは、入力シーケンス内の位置のすべてのペアの類似度スコアを計算します。Attentionメカニズムを有向グラフと考えると便利です。トークンはノードで表され、類似度スコアはエッジで表されるトークンのペア間で計算されます。この視点では、完全Attention モデルは完全グラフです。
私達のアプローチの背後にある中心的なアイデアは、類似性スコアの計算が線形で表現される数に留まるように、まばらなグラフを注意深く設計することです。
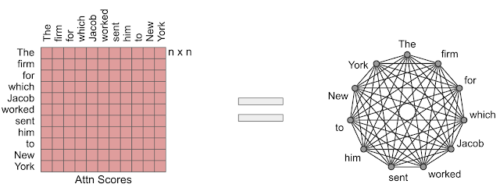
完全なAttentionは完全なグラフと見なす事ができます。
Extended Transformer Construction(ETC)
構造化された長文入力を必要とするNLPタスクでは、構造化されたスパースAttentionメカニズムを提案します。これをExtended Transformer Construction(ETC)と呼びます。
自己Attentionの構造化されたスパース化を達成するために、私たちはグローバル-ローカルAttentionメカニズムを開発しました。ここで、Transformerへの入力は、トークンが無制限に注目されるグローバル入力と、トークンがグローバル入力またはローカル近隣のいずれかにのみ参加できる長い入力の2つの部分に分割されます。これにより、Attentionの線形スケーリングが実現し、ETCが入力長を大幅に規模拡大できるようになります。
長いドキュメントの構造をさらに活用するために、ETCは追加のアイデアを組み合わせています。
シーケンス内の絶対位置を使用するのではなく、相対的な方法でトークンの位置情報を表します。BERTなどのモデルで使用される通常のマスク言語モデル(MLM:Masked Language Model)を超える追加のトレーニング目標を使用し、トークンに柔軟なマスキングを使用して、どのトークンが他のどのトークンに参加できるかを制御します。
例えば、テキストの選択部分が長い場合、グローバルトークンが各文に適用され、文内のすべてのトークンに接続されます。また、グローバルトークンが各段落に適用され、同じ段落内のすべてのトークンに接続されます。

ETCモデルのスパースアテンションに基づくドキュメント構造の例。 グローバル変数は段落の場合はC(青)、文の場合はS(黄色)で示されます。その一方、ローカル変数は長い入力に対応するトークンの場合はX(灰色)で示されます。
このアプローチでは、TriviaQA、Natural Questions(NQ)、HotpotQA、WikiHop、OpenKPの5つの挑戦的なNLPデータセットで最新の結果を報告します。
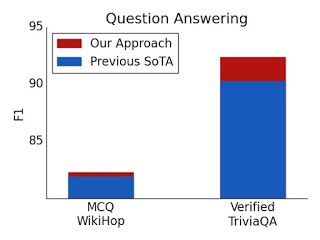
質問回答のテストの結果
検証済みのTriviaQAとWikiHopの両方で、ETCを使用することで新しい最先端の技術が実現しました。
3.Big Bird:疎なAttentionでより長い連続データに対応可能なTransformer(1/2)関連リンク
1)ai.googleblog.com
Constructing Transformers For Longer Sequences with Sparse Attention Methods
2)arxiv.org
ETC: Encoding Long and Structured Inputs in Transformers
Big Bird: Transformers for Longer Sequences
Long Range Arena: A Benchmark for Efficient Transformers
3)github.com
google-research/etcmodel/
google-research/bigbird

