
1.自動進化する強化学習でDDQNを凌駕する(1/2)まとめ
・強化学習の長期的で包括的な目標は様々な問題を解決できる単一の汎用学習アルゴリズムの設計
・強化学習は多岐にわたるため、学習方法を学習して新しいRLを設計するメタ学習手法が有望
・グラフ表現とAutoMLコミュニティの最適化手法を適用する事で進化的強化学習を実現した
2.メタ学習で強化学習アルゴリズムを探索
以下、ai.googleblog.comより「Evolving Reinforcement Learning Algorithms」の意訳です。元記事の投稿は2021年4月22日、John D. Co-ReyesさんとYingjie Miaoさんによる投稿です。
次世代で更に一歩進化していきそうな感じがするアイキャッチ画像のクレジットはPhoto by Varshesh Joshi on Unsplash
強化学習(RL:Reinforcement Learning)研究の長期的で包括的な目標は、さまざまな問題を解決できる単一の汎用学習アルゴリズムを設計することです。
ただし、RLアルゴリズムの分類は非常に多岐にわたるため、新しいRLアルゴリズムを設計する際には広範な調整と検証が必要になり、この目標は困難なものです。考えられる解決策は、さまざまなタスクに自動的に一般化する新しいRLアルゴリズムを設計できるメタ学習手法を考案することです。
近年、AutoMLは、ニューラルネットワークアーキテクチャやモデル更新ルールなどの機械学習コンポーネントの設計を自動化することに大きな成功を収めています。
一例として、ニューラルアーキテクチャ探索(NAS:Neural Architecture Search)があります。これは、画像分類のためのより優れたニューラルネットワークアーキテクチャと、スマートフォンやハードウェアアクセラレータ上で実行するための効率的なアーキテクチャを開発するために使用されています。
NASに加えて、AutoML-Zeroは、基本的な数学演算を使用して、アルゴリズム全体を最初から学習することさえ可能であることを示しています。これらのアプローチの共通のテーマの1つは、ニューラルネットワークアーキテクチャまたはアルゴリズム全体がグラフで表され、特定の目的のためにグラフを最適化するために別のアルゴリズムが使用されることです。
これらのアプローチの初期段階は、全体的なアルゴリズムがより単純な教師あり学習用に設計されました。
しかし、RLには、設計自動化のターゲットとなる可能性のあるコンポーネント(アルゴリズム)が更に存在します。(例:エージェントネットワーク用のニューラルネットワークアーキテクチャ、再生バッファからのサンプリング戦略、損失関数の全体的な定式化)
また、これらのコンポーネントを統合するための最適なモデル更新ルールが常に明確であるとは限りません。
自動化RLアルゴリズムを発見するためのこれまでの取り組みは、主にモデル更新ルールに焦点を合わせていました。これらのアプローチは、オプティマイザーまたはRL更新手順自体を学習し、通常、勾配ベースの方法で効率的に最適化できるRNNやCNNなどのニューラルネットワークで更新ルールを表現します。ただし、学習された重みは不透明で特定領域に固有であるため、これらの学習されたルールは解釈可能ではないか、一般化できません。
ICLR2021で承認された論文「Evolveing Reinforcement Learning Algorithms」では、分析的に解釈可能で一般化可能な新しいRLアルゴリズムを学習できることを示します。グラフ表現を使用し、AutoMLコミュニティの最適化手法を適用する事でこれを実現しました。
特に、エージェントの経験に基づいてパラメータを最適化するために使用される損失関数を計算グラフとして表現し、Regularized Evolutionを使用して、一連の単純なトレーニング環境で計算グラフの母集団を進化させます。
これにより、RLアルゴリズムがますます優れたものになり、発見されたアルゴリズムは、Atariゲームのような視覚的な観察が必要な環境など、より複雑な環境にも一般化できます。
計算グラフとしてのRLアルゴリズム
ニューラルネットワークアーキテクチャを表すグラフの空間を検索するNASのアイデアに触発され、RLアルゴリズムの損失関数を計算グラフとして表すことでRLアルゴリズムをメタ学習します。この場合、損失関数に有向非巡回グラフを使用し、ノードは入力、演算子、パラメーター、および出力を表します。
例えば、DQNの計算グラフでは、入力ノードには再生バッファーからのデータが含まれ、演算子ノードにはニューラルネットワーク演算子と基本的な数学演算子が含まれ、出力ノードは損失を表します。これは最急降下法で最小化されます。
このような表現にはいくつかの利点があります。
この表現は、既存のアルゴリズムだけでなく、新しい未発見のアルゴリズムを定義するのにも十分な表現力を備えており、解釈可能です。
このグラフ表現は、人間が設計したRLアルゴリズムと同じ方法で分析できるため、RL更新手順全体でブラックボックス関数近似を使用するアプローチよりも解釈しやすくなります。研究者が学習したアルゴリズムが優れている理由を理解できれば、アルゴリズムの内部コンポーネントを変更してアルゴリズムを改善し、有益なコンポーネントを他の問題に転移する事ができます。 最後に、この表現は、さまざまな問題を解決できる一般的なアルゴリズムをサポートしています。
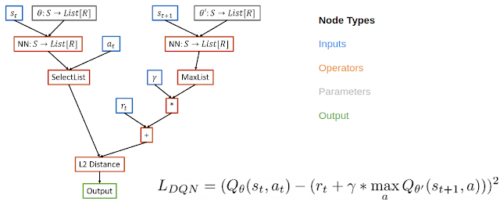
ベルマン誤差の2乗を計算するDQNの計算グラフの例
PyGloveライブラリを使用してこの表現を実装しました。これにより、グラフが正規化された進化で最適化できる検索空間に便利に変換されます。
進化するRLアルゴリズム
進化ベースのアプローチを使用して、対象のRLアルゴリズムを最適化します。まず、ランダム化されたグラフを使用してトレーニングエージェントの母集団を初期化します。このエージェントの母集団は、一連のトレーニング環境で並行してトレーニングされます。エージェントは最初にハードル環境でトレーニングを行います。これは、CartPoleなどの簡単な環境で、パフォーマンスの低いプログラムをすばやく取り除くことを目的としています。
エージェントがハードル環境を解決できない場合、トレーニングはスコア0で早期に停止されます。それ以外の場合、トレーニングはより困難な環境(Lunar Lander、単純なMiniGrid環境など)に進みます。
アルゴリズムのパフォーマンスが評価され、母集団を更新するために使用されます。ここで、より有望なアルゴリズムがさらに変更されます。
探索スペースを削減するために、機能的等価チェッカーを使用します。これは、新しく提案されたアルゴリズムが以前に調べたアルゴリズムと機能的に同じである場合、それらをスキップします。このループは、新しい変異候補アルゴリズムがトレーニングおよび評価されるまで続きます。トレーニングの最後に、最適なアルゴリズムを選択し、一連の初見のテスト環境でのパフォーマンスを評価します。
実験の母集団のサイズを約300のエージェントにし、約3日間のトレーニングを必要とする2万から5万の突然変異を行うと、良好な損失関数候補の進化を観察しました。
トレーニング環境がシンプルで、トレーニングの計算コストとエネルギーコストを制御できるため、CPUでトレーニングすることができました。
トレーニングのコストをさらに制御するために、DQNなどの人間が設計したRLアルゴリズムを初期母集団に含めました。
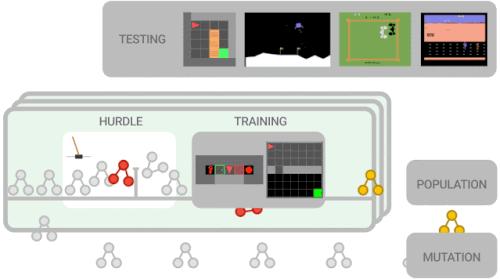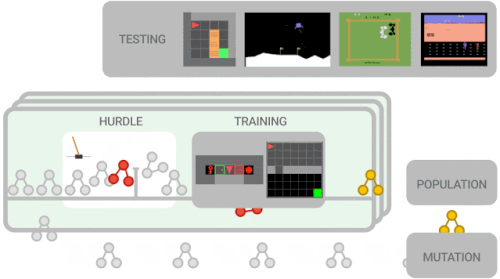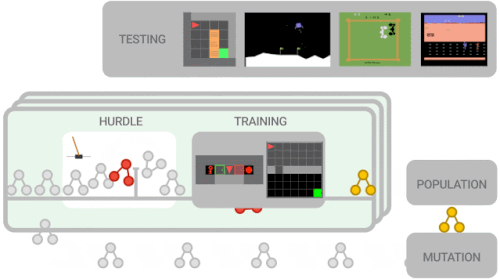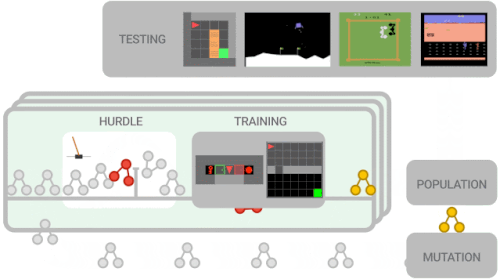
メタ学習の概要
新しく提案されたアルゴリズムは、一連のより困難な環境でトレーニングされる前に、まずハードル環境で適切に機能する必要があります。アルゴリズムのパフォーマンスは、パフォーマンスの高いアルゴリズムがさらに新しいアルゴリズムに変更される母集団を更新するために使用されます。トレーニングの最後に、最高のパフォーマンスを発揮するアルゴリズムがテスト環境で評価されます。
3.自動進化する強化学習でDDQNを凌駕する(1/2)関連リンク
1)ai.googleblog.com
Evolving Reinforcement Learning Algorithms
2)arxiv.org
Evolving Reinforcement Learning Algorithms
3)github.com
jcoreyes / evolvingrl

