
1.MobileNetV3:次世代のオンデバイス視覚モデル(3/3)まとめ
・精度とEdge TPU上で実行された際の速度を両立させるAutoMLをした結果MobileNetEdgeTPUモデル誕生
・既存のモバイルモデルよりも同一精度でより早い応答速度もしくは同一応答速度でより高い精度を実現
・しかしMobileNetEdgeTPUをモバイルCPUで実行するとMobileNetV3と比較してパフォーマンスが低下
2.MobileNetEdgeTPU
以下、ai.googleblog.comより「Introducing the Next Generation of On-Device Vision Models: MobileNetV3 and MobileNetEdgeTPU」の意訳です。元記事は2019年11月13日、Andrew HowardさんとSuyog Guptaさんによる投稿です。
エッジTPU向けのMobileNet
Pixel 4のEdge TPUは、Coralの製品ラインナップ(訳注:CoralとはGoogleが提供しているエッジでの実行に最適化された製品群です)のEdge TPUとアーキテクチャが似ていますが、Pixel 4搭載カメラの主要機能を実現するために必要となる条件を満たすようにカスタマイズされています。
アクセラレータ対応のAutoML(accelerator-aware AutoML)は、ニューラルネットワークをハードウェアアクセラレータ上の実行に最適化する際に必要となる手作業を大幅に削減します
ニューラルアーキテクチャの探索スペースを作成することは、このAutoMLアプローチの重要な部分です。アクセラレータの使用率を向上させることが知られているニューラルネットワーク操作を多く含めることに重点を置いて探索スペースを構築します。
squeeze-and-exciteやswishなどの非線形な演算操作は、コンパクトで高速なCPUモデルの構築に不可欠であることが示されていますが、これらの操作はEdge TPU上で実行する際には最適化ができないため、探索スペースから除外されます。
MobileNetV3の最小限構成では、これらの操作(つまり、squeeze-and-excite、swish、および5×5の畳み込み)の使用を控えて、DSPやGPUなどの他のさまざまなハードウェアアクセラレーターへの移植性を高めています。
モデルの精度とEdge TPU上で実行された際の応答速度を両立するようにインセンティブを与えてニューラルネットワークアーキテクチャ探索をした結果、MobileNetEdgeTPUモデルが生成されました。MobileNetEdgeTPUモデルは、MobileNetV2やミニマルなMobileNetV3などの既存のモバイルモデルよりも同一精度でより早い応答速度、もしくは同一応答速度でより高い精度を実現します。
CoralのEdge TPU用に最適化したEfficientNet-EdgeTPUモデルと比較すると、これらのモデルは、精度が多少低下しますが、Pixel 4で非常に速い応答速度で実行されるように設計されています。
モデルの消費電力を削減する事はニューラルネットワークアーキテクチャ探索の目的にはありませんでしたが、MobileNetEdgeTPUモデルの速い応答速度は、Edge TPUの平均的消費電力の削減にも役立ちます。MobileNetEdgeTPUモデルの消費電力は、最小構成のMobileNetV3モデルと同等の精度で比較して50%未満です。
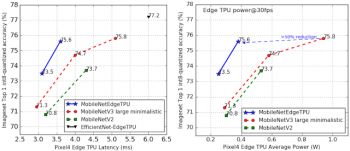
左:MobileNetEdgeTPUと他のモバイル向けに設計された画像分類ネットワークの比較。Pixel4 Edge TPUで実行したImageNet分類タスクでは、MobileNetEdgeTPUは、他のモデルと比較して、より高い精度と速い応答速度を実現しています。右:毎秒30フレーム(fps)で実行した際の様々な分類モデルの平均エッジTPU電力(単位ワット)。
MobileNetEdgeTPUを使用した物体検出
MobileNetEdgeTPUの分類モデルは、物体検出タスクで効果的に特徴を抽出する機能としても使う事ができます。MobileNetV2ベースの検出モデルと比較して、MobileNetEdgeTPUモデルは、Edge TPU上で実行すると、MobileNetV2と同等の実行時間でCOCO14 minival datasetのモデル品質を大幅に改善します。(mAP:mean average precisionとして測定)
MobileNetEdgeTPU検出モデルは、応答速度は6.6ミリ秒でmAPスコアは24.3を達成しましたが、MobileNetV2ベースの検出モデルは推論ごとに6.8ミリ秒かかり、mAPは22です。
ハードウェア対応モデルの必要性
前述の結果は、MobileNetEdgeTPUモデルのパワー、パフォーマンス、および品質の利点を強調していますが、これらのモデルはEdge TPUアクセラレーターで実行するようにカスタマイズされているために性能が向上していると言う事実には注意が必要です。MobileNetEdgeTPUをモバイルCPUで実行すると、モバイルCPU用に特別に調整されたモデル(MobileNetV3)と比較してパフォーマンスが低下します。
MobileNetEdgeTPUモデルは非常に多くの演算操作を実行するため、モデルが必要とする計算量が増えればその分直線的に実行時間が増えるモバイルCPU上で実行すると速度が遅くなることは驚くことではありません。
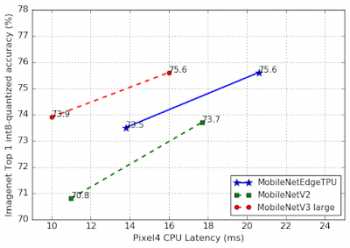
モバイルCPU上の実行を比較するとMobileNetV3は依然として最高のパフォーマンスを発揮するネットワークです。
研究者および開発者向け
MobileNetV3およびMobileNetEdgeTPUコード、およびImageNet分類用の浮動小数点と量子化チェックポイントの両方は、MobileNet githubページで入手できます。MobileNetV3およびMobileNetEdgeTPUオブジェクト検出のオープンソース実装は、Tensorflow Object Detection APIで利用できます。 MobileNetV3セマンティックセグメンテーションのオープンソース実装は、DeepLabを介してTensorFlowで利用できます。
謝辞
この作業は、Googleの複数のチームにまたがるコラボレーションを通じて可能になりました。
Berkin Akin, Okan Arikan, Gabriel Bender, Bo Chen, Liang-Chieh Chen, Grace Chu, Eddy Hsu, John Joseph, Pieter-jan Kindermans, Quoc Le, Owen Lin, Hanxiao Liu, Yun Long, Ravi Narayanaswami, Ruoming Pang, Mark Sandler, Mingxing Tan, Vijay Vasudevan, Weijun Wang, Dong Hyuk Woo, Dmitry Kalenichenko, Yunyang Xiong, Yukun Zhu and support from Hartwig Adam, Blaise Agüera y Arcas, Chidu Krishnan そして Steve Molloyの貢献に感謝します。
3.MobileNetV3:次世代のオンデバイス視覚モデル(3/3)まとめ
1)ai.googleblog.com
Introducing the Next Generation of On-Device Vision Models: MobileNetV3 and MobileNetEdgeTPU
2)arxiv.org
NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications

コメント