
1.SPICE:自己教師学習で音の高さを推定まとめ
・メロディーを認識するためには音の高さの変化、つまりピッチの変化を追跡する能力が必要
・しかし音の高さをそのまま認識する絶対音感より相対的に認識する相対音感の方が人間の脳でも一般的
・SPICEは自己教師学習で相対的なピッチの違いを学習し、最先端の教師付き学習に迫るスコアを出した
2.SPICEとは?
以下、ai.googleblog.comより「SPICE: Self-Supervised Pitch Estimation」の意訳です。元記事は2019年11月14日、Marco Tagliasacchiさんによる投稿です。絶対音感、英語で言うperfectpitchを持つ人の割合は諸説あるようですが3%程度とされているようです。音を、他の音との比較ではなく、そのまま音として捉える事は脳にとって難しい事なのではないと言う洞察から本研究が生まれたと言う話を読んで、改めてニューラルネットワークって本当に脳の構造を真似ているのだな、と実感します。
ピッチ(pitch)とは音の高さの事であり、音を数字で表す際の尺度となり、周波数として表されます。高音は低音よりも周波数が高くなります。人間はピッチの相対的な違いを聴覚で追跡する事により、歌のメロディーなどのオーディオ特徴を認識できています。
ピッチの推定は、「音楽情報の検索」から「音声分析」に至るまで、いくつかの分野で中心的な重要性を持つため、過去数十年にわたって大きな注目を集めてきました。
従来、ピッチを推定するために、時間領域(pYIN等)または周波数領域(SWIPE等)で動作する手作りの単純な信号処理パイプラインが考案されてきました。そして、最近まで、機械学習を使った手法は、そのような手作りの信号処理パイプラインの性能を上回ることができませんでした。
これはラベル付きデータの不足によるものです。完全教師有り学習モデルをトレーニングするために必要な時間的および周波数的に分解したデータにラベルを付与するのは特に退屈で困難な作業であるからです。CREPEモデルは、これらの制限を克服して、合成的に生成されたデータセットを他の手動のラベル付きデータセットと組み合わせてトレーニングすることにより、最先端の結果を達成することができました。
私達の最近の論文、「SPICE: Self-supervised Pitch Estimation」では、ラベル付きデータがなくてもピッチを推定するモデルを学習出来る別のアプローチを紹介します。
人間の場合、プロのミュージシャンであっても、絶対的音感(音の基本周波数を認識)よりも相対的音感(2つの音の周波数の違いを認識)の方が一般的にはるかに簡単であるという観察に基づいて、SPICE(Self-supervised PItCh Evaluation)は同様なアプローチでピッチ推定を取り扱います。
このアプローチは、補助タスク(pretext taskとも呼ばれる)を定義する自己教師学習で実現できます。補助タスクは完全に教師なし学習で学習する事ができます。
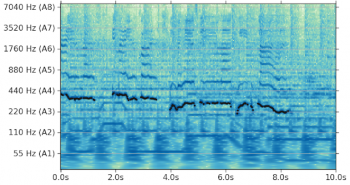
オーディオクリップの定数Q変換(Constant-Q transform)
SPICEで推定したピッチの特徴表現をまとめて表示しています
SPICEモデルは畳み込みエンコーダで構成されます。これは、ピッチを線形にマッピングする単一のスカラーなembeddingを生成します。これを達成するために、2つの信号をエンコーダーに送ります。「基準信号」と「基準からランダムにピッチをシフトした信号」です。
次に、損失関数を考案します。これには、スカラーembedding間の差がピッチの差に比例するような性質を持たせます。
便宜上、定数Q変換(CQT:Constant-Q Transform)で定義された領域でピッチシフトを実行します。これは、周波数軸をlog変換して扱いやすくするためです。
ピッチは、基礎となる信号が倍音(harmonic)の場合、つまり基本周波数の整数倍の成分を含む場合にのみ明確に定義されます。そのため、モデルが持つべき重要な機能は、どのタイミングで音声特徴を出力すれば、出力が意味のある信頼できる値になるかを判断することです。
例えば、たとえば、次の図では、1.2秒と2秒の間の間隔に倍音信号がないため、ピッチ推定の信頼度が低く、ピッチ推定は生成されません。SPICEは、手動設計した解法に頼るのではなく、自己教師の方法でピッチ推定の信頼度を学習するように設計されています。
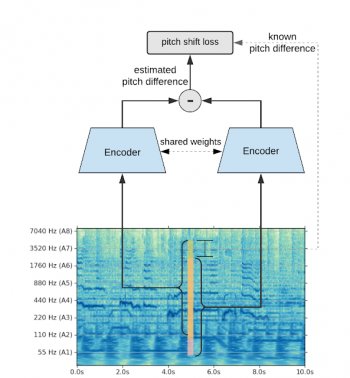
SPICEモデルのアーキテクチャ
同じCQTフレームの2つのピッチシフトバージョンが、重みを共有している2つのエンコーダーに供給されます。損失は、エンコーダの出力間の差が相対ピッチ差に比例するように設計されています。更に(図示されてません)、モデルを正則化するために再構成損失が追加されます。モデルは、ピッチ推定の信頼度を生成することも学習します。
一般公開されているデータセットを使ってSPICEモデルを評価し、ラベルなしデータにしかアクセスできないにもかかわらず、CREPEと同等精度を達成し、従来の手動設計手法を上回ることを示せました。
更に、トレーニング中にデータを適切に増強することにより、SPICEはノイズの多い音声を取り扱う事ができます。例えば、バックグラウンドミュージックが流れている状況で歌声のみのピッチを抽出する事ができます。以下のチャートは、MIR-1kデータセットでのSWIPE(手動設計の信号処理方法)、CREPE(完全教師学習モデル)、およびSPICE(自己教師モデル)の比較を示しています。
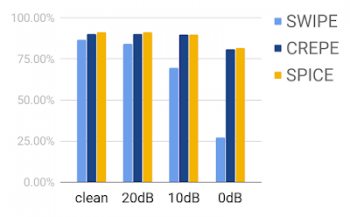
MIR-1kデータセットを使った評価、さまざまなS/N比でバックグラウンドミュージックをミックスしています。
SPICEモデルは、ユーザが歌ってフレディ・マーキュリー(訳注:映画ボヘミアン・ラプソディーでも話題になったイギリスのロックバンド、クイーンのボーカリスト。この方もラジオから流れる曲を聞いてそのままピアノで演奏する事が出来たとの逸話があるので絶対音感を持っていた方なのだと思います)とパフォーマンス競う事ができるWebアプリであるFreddieMeterに導入されています。
謝辞
本投稿で説明されている研究は、Beat Gfeller, Christian Frank, Dominik Roblek, Matt Sharifi, Marco Tagliasacchi 及び Mihajlo Velimirovićによって執筆されました。Googleの同僚から受け取ったこの研究に関する全ての議論とフィードバックに感謝します。この作品のモデルのトレーニングに使用されるSingingVoicesデータセットは、フレディメーターの一部としてAlexandra Gherghinaによって収集されました。このWebアプリは歌手がフレディマーキュリーとどれだけ似ているかをチェックするために、SPICEと音声音色類似モデルを使用しています。
3.SPICE:自己教師学習で音の高さを推定関連リンク
1)ai.googleblog.com
SPICE: Self-Supervised Pitch Estimation
2)arxiv.org
SPICE: Self-supervised Pitch Estimation
3)withyoutube.com
freddiemeter

コメント