
1.XIRL:人と形状が異なるロボットは人から学ぶ事が出来るのか?(2/2)まとめ
・XIRLは実演者と学習者が異なる形状である際の模倣問題に取り組む手法
・時間的サイクル整合性を用いて実施形態に依存しない報酬関数を学習
・サンプル効率が高く教師なし学習であるため応用範囲が非常に広い
2.XIRLの性能
以下、ai.googleblog.comより「Robot See, Robot Do」の意訳です。元記事は2022年2月8日、Kevin ZakkaさんとAndy Zengさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Andre Mouton on Unsplash
X-MAGICAL ベンチマーク
XIRLと比較対象手法(TCN、LIFS、Goal Classifierなど)を一貫した環境で評価するために、私たちはX-MAGICALという異種実施形態を模倣(cross-embodiment imitation)する能力を測るシミュレーションベンチマークを作成しました。
X-MAGICALでは、形状や作業用先端部(end-effectors)が異なる多様なエージェントを用意し、異なる方法でタスクを解決するように設計されています。このため、実行速度や状態遷移の軌跡が異なり、現在の模倣学習技術(例えば、時間間隔を経験則的に用いて2つの軌跡を大まかに紐づける技術)にとって困難です。X-MAGICALが評価するのは、まさにこの「エージェントの実施形態に依存しない汎化能力」なのです。
私たちが実験用に考えたSweepToTopタスクは、一般的な家庭用ロボットの掃き掃除タスクを簡略化して2Dにしたもので、エージェントは環境内のゴールゾーンに3つの物体を押し込まなければなりません。
このタスクを特に選んだのは、その長期目線での性質が、エージェントの実施形態によってまったく異なる軌道を生成できることを強調するためです(下図参照)。
X-MAGICALは、ジムAPIを搭載し、新しいタスクや実施形態に簡単に拡張できるように設計されています。「pip install x-magical」で今すぐ試せます。
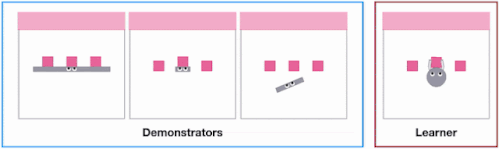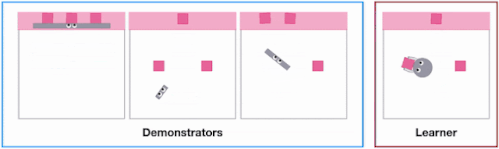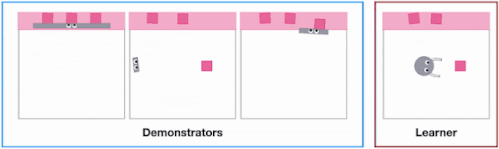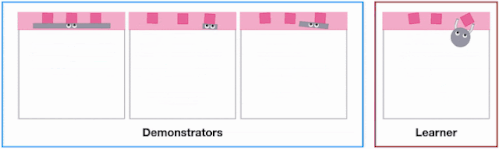
X-MAGICALベンチマークのSweepToTopタスクでは、エージェントの形状の違いにより、物体をターゲットエリア(ピンク)に再配置する、つまり「障害物を取り除く」戦略を取る必要があります。例えば、長い棒は一気にクリアできるのに対して、短い棒は何度も連続して往復する必要があります。
実験のハイライト
最初の実験では、学習した実施形態不変の報酬関数が強化学習を成功させることができるかどうかを確認しました。
この実験ではエージェントそのものを使った専門家のデモンストレーションが提供された場合に、強化学習を成功させることができるかどうかを確認しました。その結果、XIRLは、特に短い棒状物体やグリッパーなどの難易度の高いエージェントにおいて、他の手法よりも優れた性能を発揮することが分かりました。
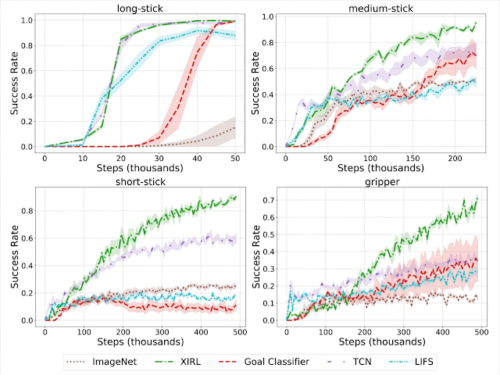
同じ実施形態をデモとして与えた場合
XIRLとRLのポリシー学習にSACを用いた場合の比較
XIRLは、より困難なエージェント(short-stickとgripper)において、比較対象手法よりもおよそ2~4倍サンプル効率が良いです。
また、本アプローチは、新しい実施形態に汎化する報酬関数の学習に大きな可能性を示すことがわかりました。
例えば、報酬の学習を、ポリシーを学習したものとは異なる実施形態で行った場合、比較対象手法より、著しくサンプル効率の高いエージェントが得られることが分かりました。
例えばグリッパーの図(右下)では、まず長い棒状物体、中程度の棒状物体、短い棒状物体を使ったデモンストレーション映像で報酬を学習し、その後、報酬関数を用いてグリッパー用エージェントを学習しています。
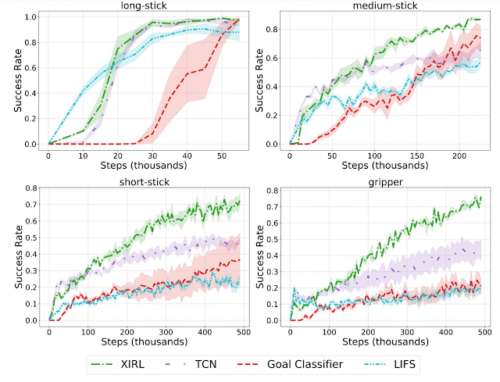
異なる実施形態をデモとして与えた場合
XIRL は、他の比較対象手法の報酬関数と比較して、異なる実施形態のデモだけで訓練した場合に、良好なパフォーマンスを示しました。各エージェント(long-stick, medium-stick, short-stick, gripper)は、他の3つの実施形態からのデモを用いて報酬を訓練しています。
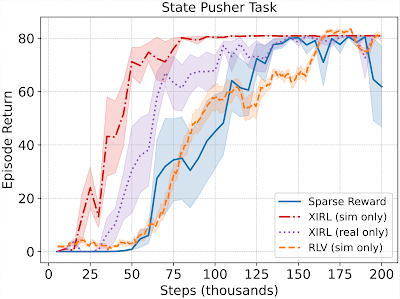
また、人間が行ったデモを用いた訓練が可能であることを確認しました。人間から学習した報酬を用いて、シミュレーションでロボットアームを訓練し、指定したターゲットゾーンに円盤を押し付けることができます。
これらの実験でも、私たちの手法はベースラインとなる代替手法よりも優れた性能を示しました。例えば、実世界のデモンストレーションのみで学習させたXIRL(下のグラフでは紫色)は、RLVのベースライン(オレンジ色)よりも約85%速く全体の80%の性能に到達しました。

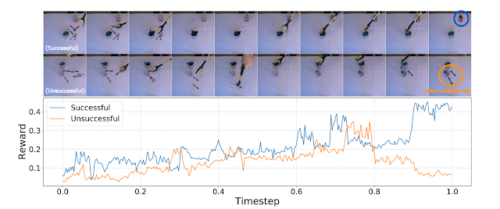
学習された報酬関数はどのようなものなのでしょうか?
学習した報酬の質的特性をより困難な実世界のシナリオでさらに探索するために、私たちは様々な家庭用具を用いたペン回しタスクのデータセットを収集しました。

以下に、成功したデモ(上図)と失敗したデモ(下図)から抽出された報酬を示します。どちらのデモも、タスク開始時は同じような軌跡を描いています。成功したデモでは、ペンをマグカップからガラスコップへ連続して入れたため高い報酬が得られ、失敗したデモでは、終盤にペンをガラスコップの外に落としてしまったため低い報酬しか得られませんでした。(オレンジ色の丸)。この結果は、学習したエンコーダーがタスクに関連する細かな視覚的差異を表現できることを示すものであり、期待ができます。
まとめ
XIRLは、異種実施形態間の模倣問題( cross-embodiment imitation problem)に取り組むための私たちのアプローチです。XIRLは、時間的サイクル整合性目標を用いて、タスクの進み具合を符号化し、実施形態に依存しない報酬関数を学習します。
XIRLの報酬関数を用いて学習したポリシーは、代替手法と比較してサンプル効率が大幅に向上します。さらに、報酬関数は、実演者と学習者の間で手動でビデオフレームを整列させる必要がないため、任意の数の実演者や様々なスキルレベルの専門家に対応することが可能です。
このベンチマークがこの分野のさらなる研究を促進することを期待しています。詳細については、私たちの論文をチェックし、GitHubからコードをダウンロードしてください。
謝辞
Kevin と Andy が、Pete Florence、Jonathan Tompson、Jeannette Bohg(スタンフォード大学教員)、Debidatta Dwibedi と共同で行った研究をまとめたものです。
また、Alex Nichol, Nick Hynes, Sean Kirmani, Brent Yi, Jimmy Wu, Karl Schmeckpeper そして Minttu Alakuijalaには有益な技術的議論を、Sam Toyer にはベンチマークシミュレーションのセットアップで貴重な助言をいただきました。
3.XIRL:人と形状が異なるロボットは人から学ぶ事が出来るのか?(2/2)関連リンク
1)ai.googleblog.com
Robot See, Robot Do
2)arxiv.org
XIRL: Cross-embodiment Inverse Reinforcement Learning
3)github.com
google-research / xirl/
kevinzakka / x-magical

左:専門家が行ったデモ時の各実施形態の状態来歴ヒートマップ
右:それぞれの実施形態における専門家の軌跡の例