
1.Dreamer V2:モデルベース強化学習でモデルフリー強化学習を超える(1/2)まとめ
・従来のモデルベース強化学習はモデルフリーアプローチに正確性で劣った
・Dreamer V2はAtariベンチマークで人間レベルのパフォーマンスを達成
・同じ計算機資源とサンプル資源を使う前提で、モデルフリーアルゴリズムを凌駕
2.Dreamer V2とは?
以下、ai.googleblog.comより「Mastering Atari with Discrete World Models」の意訳です。元記事の投稿は2021年2月18日、Danijar Hafnerさんによる投稿です。
2020年3月に投稿があったDreamerのVersionUpで、遂にモデルベース強化学習がモデルフリー強化学習を上回る性能を発揮始めたとのお話です。
アイキャッチ画像のクレジットはPhoto by Alvaro Reyes on Unsplash
深層強化学習(RL:deep Reinforcement learning)により、人工知能エージェントは時間の経過とともに意思決定を改善できます。従来のモデルフリーアプローチでは、大量の試行錯誤を通じて環境と対話することにより、さまざまな状況でどのアクションが成功するかを学習します。
対照的に、多層RLの最近の進歩により、モデルベースのアプローチで画像入力から正確な世界モデルを学習し、それらを計画に使用できるようになりました。世界モデルは、より少ない対話から学習し、オフラインデータからの一般化を容易にし、将来を見据えた調査を可能にし、複数のタスクにわたって知識を再利用できるようにします。
興味深い利点にもかかわらず、既存の世界モデル(SimPLeなど)は、最も競争が激しい強化学習ベンチマークで上位のモデルフリーアプローチと競合するほど正確性を持ち合わせていません。
これまで、確立されたAtariベンチマークにはモデルフリーアルゴリズムが必要です。これらはDQN、IQN、Rainbowなど、人間レベルのパフォーマンスを実現します。その結果、多くの研究者は、代わりに、VPNやMuZeroなど、予想されるタスク報酬の合計を予測することによって学習するタスク固有の計画方法の開発に焦点を合わせています。
ただし、これらの方法は個々のタスクに固有であり、新しいタスクに一般化する方法や、教師なしデータセットから学習する方法は不明です。コンピュータビジョンにおける教師なし特徴表現学習の最近の進歩と同様に、世界モデルは、特定のタスクよりも一般的な環境のパターンを学習して、後でタスクをより効率的に解決することを目的としています。
本日、DeepMindおよびトロント大学と共同で、Atariベンチマークで人間レベルのパフォーマンスを達成した世界モデルに基づく最初のRLエージェントであるDreamer V2を紹介します。
これは、画素からトレーニングしたワールドモデルの潜在空間内で純粋に動作を学習するDreamerエージェントの第2世代です。Dreamer V2は、画像からの一般的な情報のみに依存しており、その表現がそれらの報酬の影響を受けていない場合でも、将来のタスク報酬を正確に予測します。単一のGPUを使用することで、DreamerV2は、同じ計算機資源とサンプル資源を使う前提で、モデルフリーのトップアルゴリズムよりも優れています。
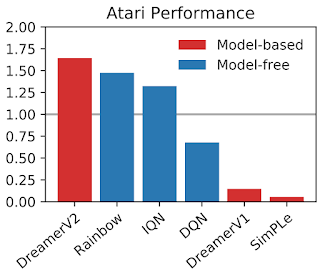
各モデルは2億ステップ回ゲームを実行後、55種類のAtariゲーム全体のゲーマー中央値で正規化しました。DreamerV2は、以前の世界モデルを大幅に上回っています。さらに、同じコンピューティング資源とサンプル数の制限下で、モデルフリーのトップエージェントを上回っています。
55のAtariゲームのいくつかについてDreamerV2によって学習された動作。これらのビデオは、環境からの画像を示しています。 ビデオの予測については本稿で後述されています。

世界の抽象的なモデル
従来のDreamerと同様に、DreamerV2は世界モデルを学習し、それを使用して、純粋に予測された軌道からactor-criticの行動を訓練します。
世界モデルは、物体の位置などの有用な概念を発見する画像のコンパクトな特徴表現を計算することを自動的に学習し、様々なアクションに応じてこれらの概念がどのように変化するかを学習します。これにより、エージェントは、無関係な詳細を無視した画像の抽象化を生成し、単一のGPUで超並列予測を可能にします。DreamerV2は、2億の環境ステップの間に、その動作を学習するために4,680億のコンパクトな状態を予測します。
DreamerV2は、PlaNet用に導入したRecurrent State-Space Model(RSSM)に基づいて構築されており、これはDreamerV1にも使用されています。トレーニング中、エンコーダーは各画像を確率的特徴表現に変換し、それが世界モデルの反復状態に組み込まれます。特徴表現は確率的であるため、画像に関する完全な情報にアクセスできず、代わりに予測を行うために必要なものだけを抽出し、エージェントを見た事のない画像に対して堅牢にします。各状態から、デコーダーは対応する画像を再構築して一般的な特徴表現を学習します。更に、小さな報酬ネットワークは、計画中に結果をランク付けするようにトレーニングされています。画像を生成せずに計画を可能にするために、予測子は計算元画像にアクセスせずに確率的特徴表現を推測する事を学習します。
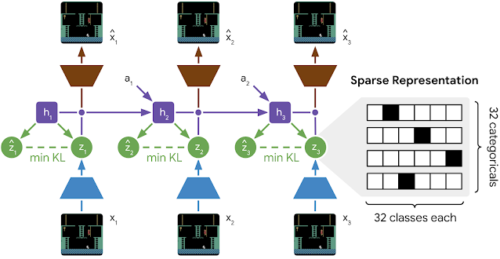
DreamerV2で使用される世界モデルの学習プロセス
世界モデルは、アクション(a1–a2)を受け取り、確率的特徴表現(z1–z3)を介して画像(x1–x3)に関する情報を組み込む反復状態(h1–h3)を維持します。予測子は、特徴表現の生成元の画像にアクセスせずに、表現を(z^1–z^3)として推測します。
重要なことは、DreamerV2はRSSMに2つの新しい手法を導入している事です。これは実質的により正確な世界モデルと成功するポリシーを学習する事に繋がります。
最初の手法は、PlaNet、DreamerV1、および他の複数の文献で使用されているガウス変数ではなく、複数のカテゴリ変数を使用して各画像を表現する事です。これにより、世界モデルは離散概念(discrete concepts)の観点から世界について推論し、将来の特徴表現のより正確な予測を可能にします。
エンコーダーは、各画像をそれぞれ32クラスにわたる32の分布に変換します。それぞれの意味は、世界モデルが学習するときに自動的に決定されます。
これらの分布からサンプリングされたワンホットベクトル(one-hot vectors)は、スパース特徴表現に連結され、再帰状態に渡されます。サンプルを逆伝播するために、自動微分を実装しやすいストレート スルー グラディエント(straight-through gradients)を使用します。
カテゴリ変数を使用して画像を表すことにより、予測子は、次に可能な画像のワンホットベクトル上の分布を正確に学習できます。対照的に、ガウス予測子を使用する以前の世界モデルでは、次に可能な画像について、複数のガウス表現の分布を正確に一致させることはできません。
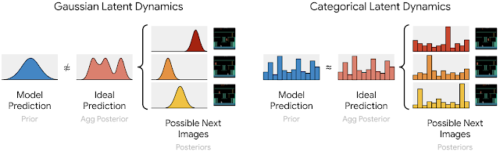
次に可能な画像を表す複数のカテゴリは、カテゴリ予測子によって正確に予測できますが、ガウス予測子は、複数の可能なガウス表現を正確に予測するのに十分な柔軟性がありません。
DreamerV2の2番目の新しい手法は、KLバランシング(KL balancing)です。
従来の世界モデルの多くは、正確な再構築を促進するELBO目標(ELBO objective)を使用しています。これは、各画像から抽出される情報の量を正則化し、一般化を容易にするために、確率的特徴表現(事後)を予測(事前)に近づけます。目標はエンドツーエンドで最適化されているため、確率的特徴表現とその予測は、2つのいずれかをもう一方に近づけることでより類似させることができます。
ただし、予測子がまだ正確でない場合、特徴表現を予測に近づけることは問題になる可能性があります。KLバランシングにより、予測は特徴表現に向かってより速く移動できます。これにより、より正確な予測が可能になり、計画を成功させるための鍵となります。

ホールドアウトシーケンスの世界モデルの長期ビデオ予測
各モデルは入力として5フレームを受け取り(図には示されていません)、アクションのみを与えられて45ステップ先を予測します。ビデオ予測は、世界モデルの品質に関する洞察を得るためにのみ使用されます。計画時には、画像ではなく、コンパクトな特徴表現のみが予測されます。
3.Dreamer V2:モデルベース強化学習でモデルフリー強化学習を超える(1/2)関連リンク
1)ai.googleblog.com
Mastering Atari with Discrete World Models
2)arxiv.org
Mastering Atari with Discrete World Models
3)github.com
danijar / dreamerv2

