
1.Google Research:2022年以降にAIはどのように進化していくか?(5/6)まとめ
・MLが広く使われるようになるにつれ公平かつ公正に適用される事が重要になる
・推薦システムの推薦が集中したり機械翻訳が性別を決めつる事などは問題
・責任あるAIと人間中心の技術研究の主要な焦点であり様々な研究を行っている
2.MLに対する理解が深まる
以下、ai.googleblog.comより「Google Research: Themes from 2021 and Beyond」の意訳です。元記事は2022年1月11日、Jeff Deanさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Michael Held on Unsplash
MLに対する理解が広く深まるようになる
MLがテクノロジー製品や社会により広く使われるようになるにつれ、それが公平かつ公正に適用され、一部の人々だけでなくすべての人々に恩恵をもたらすことを確実にするために、新しい技術を開発し続けることが不可欠となります。
これは、私たちの責任あるAIと人間中心の技術研究グループの主要な焦点であり、責任に関連するさまざまなトピックについて研究を行っている分野でもあります。
そのひとつが、オンライン販売におけるユーザーの行動履歴に基づく推薦システムです。このような推薦システムは複数の異なる要素から構成されることが多いため、その公平性を理解するためには、個々の構成要素に関する知見だけでなく、個々の構成要素を組み合わせたときにどのような振る舞いをするのかについての知見も必要となることが多いです。
最近の研究では、これらの関係をより深く理解することで、個々の構成要素と推薦システム全体の公正さを向上させる方法が明らかにされています。また、暗黙のユーザーの行動から学習する場合、以前にユーザーに表示された項目だけを使ってら学習するという単純な方法では、よく知られたバイアスがかかってしまうため、このようなバイアスを補正しないと、例えば、より目立つ位置に表示されたアイテムは、より頻繁に未来のユーザーに推薦される傾向があります。推薦システムが偏りのない方法で学習することは重要です。
推薦システムと同様に、機械翻訳においても周囲の文脈が重要になります。多くの機械翻訳システムは、周囲の文脈を考慮せずに個々の文章を翻訳するため、性別や年齢などに関するバイアスを助長してしまうことがあります。
このような問題に対処するため、私たちは長年にわたり翻訳システムのジェンダーバイアスを低減する研究を行ってきました。また、翻訳コミュニティ全体に役立てるため、昨年、Wikipediaの経歴の翻訳を基に、翻訳におけるジェンダーバイアスを研究するデータセットを公開しました。
機械学習モデルを導入する際によくあるもう一つの問題は、分布のずれ(distributional shift)です。モデルが学習したデータの統計的分布が、モデルが入力として与えられたデータの統計的分布と同じでない場合、モデルの動作は時に予測不可能になることがあります。
最近の研究では、ディープブートストラップのフレームワークを用いて、学習データが有限である現実世界と、データが無限である「理想世界」を比較しています。この2つの領域(現実世界と理想世界)でモデルがどのように振る舞うかをより良く理解することは、新しい設定に対してより良く汎化し、固定された学習データセットへの偏りを少なくするモデルを開発するのに役立ちます。
MLアルゴリズムやモデル開発には大きな注目が集まりますが、データ収集やデータセットのまとめにはあまり注目が集まらないことが多いようです。しかし、これは重要な領域です。なぜなら、MLモデルが学習時に使ったデータは、下流アプリケーションにおいて偏りや公平性の問題の潜在的な原因となり得るからです。
このようなMLにおけるデータカスケードを分析することで、MLプロジェクトのライフサイクルの中で、結果に大きな影響を与える可能性がある多くの場所を特定することができます。このデータカスケードに関する研究は、ML開発者や設計者を対象とした改訂版PAIRガイドブックにおいて、データ収集と評価に関するエビデンスに裏付けられたガイドラインを作成することにつながりました。
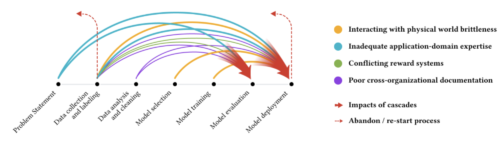
色の異なる矢印は、様々なタイプのデータカスケードを示し、それぞれが上流で発生し、ML開発プロセスで複合化し、下流で顕在化するのが一般的です。
データをよりよく理解するという一般的な目標は、ML研究の重要な部分です。その一助となるのが、異常なデータを発見し調査することです。
私たちは、特定の学習サンプルがMLモデルに与える影響をよりよく理解するための方法を開発しました。なぜなら、誤ったラベル付けをされたデータや他の同様の問題は、モデル全体の動作に大きな影響を与える可能性があるからです。また、ML研究者や実務家がデータセットの特性をよりよく理解できるようにKnow Your Dataツールを構築しました。昨年は、データセットにおけるジェンダーバイアスや年齢バイアスなどの問題を調査するためにKnow Your Dataツールを使用する方法についてケーススタディを作成しました。
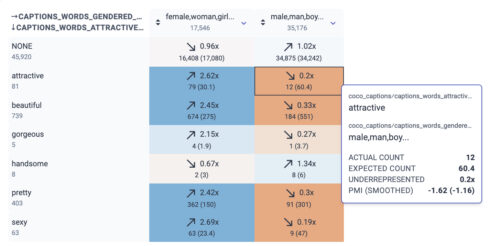
Know Your Dataのスクリーンショットで、魅力を表現する言葉と性別の関係を示したもの。例えば、「魅力的(attractive)」の単語は「male/man/boy」に12回使われていますが偏りがなければ60回程度使われる事が普通と予想されます。(実際に出現したのは0.2倍の頻度)。一方、「魅力的(attractive)」と「female/woman/girl」は2.62倍の頻度で使われています。
また、ベンチマークデータの使われ方を把握することは、MLという分野の組織化において中心的な役割を果たすことから、重要です。個々のデータセットに関する研究はますます一般的になってきていますが、分野全体のデータセット利用については、まだ十分に調査されていないのが現状です。
最近、私たちは、データセットの作成、採用、再利用の変遷に関する初の大規模な実証的分析を発表しました。この研究は、より厳密な評価や、より公平で社会的な情報に基づいた研究を可能にするための道筋についての洞察を提供するものです。
より包括的で偏りのない公共データセットを作成することは、すべての人のためにMLの分野を改善するのに役立つ重要な方法です。
2016年、私たちは数千のカテゴリにまたがる画像ラベルと600クラスの境界ボックス型の注釈を持つ約900万枚の画像のコレクションであるOpen Imagesデータセットをリリースしました。
昨年、私たちはOpen Images ExtendedコレクションにMore Inclusive Annotations for People(MIAP)データセットを追加しました。このデータセットには、人物クラス階層のより完全な境界ボックス注釈が含まれており、各注釈には、知覚された性別の表示や知覚された年齢の範囲など、公平性に関連する属性が付与されています。
責任あるAI研究の一環として、不公平なバイアスを減らすことにますます注目が集まる中、これらの注釈が、すでにOpen Imagesデータセットを活用している研究者が、研究に公平性分析を取り入れるきっかけになることを期待しています。
機械学習の能力を向上させるデータセットを作成しているのは、私たちのチームだけではないことも理解しています。そのため、Dataset Searchを構築し、ウェブ上のどこに保存されていても、新しく有用なデータセットをユーザーが発見できるようにしました。
有害表現、ヘイトスピーチ、誤報など、ネット上のさまざまな形態の悪意に対処することは、Google の中核的な優先事項です。
このような悪用行為を確実かつ効率的に、そして大規模に検知することは、Google のプラットフォームの安全性を確保するためにも、またオンライン上の文章から教師なしで学習する言語技術によってこのような負の特徴が再現されるリスクを回避するためにも、非常に重要なことなのです。
Googleは、Perspective APIツールを通じて、この分野における先駆的な取り組みを行ってきましたが、毒性(toxicity)に関わるニュアンスを巨大データから検知する事は、依然として複雑な問題であることに変わりありません。
最近の研究では、様々な学術的パートナーと協力して、オンライン上の憎悪や嫌がらせの変化について推論するための包括的な分類法を導入しました。
また、密かな毒性を検出する方法についても調査しました。例えばマイクロアグレッション(Microaggression、無自覚な偏見に基づく発言や行動で相手を傷つけること)は、オンライン上の悪用に介入する際に無視されがちです。データ注釈内の主観的な概念の不一致に注目する従来のアプローチが、いかに少数派の視点を疎外する可能性があるかを研究しました。
そして、この問題に取り組むために、マルチタスクフレームワークを用いた新しい細分化されたモデリングアプローチを提案しました。さらに、GoogleのJigsawチームは、定性的調査とネットワークレベルのコンテンツ分析を通じて、ジョージ・ワシントン大学の研究者と共同で、ヘイトクラスターがソーシャルメディアプラットフォームで偽情報を拡散する仕組みを研究しました。
また、MLの言語理解・生成モデルは、時として、適切な根拠に基づかない結果を出力する事も潜在的な懸念事項です。質問回答、要約、対話におけるこの問題に対処するため、私たちは結果が特定の情報源に帰着できるかどうかを測定する新しいフレームワークを開発しました。注釈ガイドラインを公開し、これがモデル候補の評価に確実に利用できることを実証しました。
対話的にモデルを解析し、デバッグすることは、MLを責任を持って利用する上で重要なことです。今回、言語解釈ツールに新たな機能と技術を追加し、この分野を発展させるべくリニューアルしました。画像や表形式のデータのサポート、What-Ifツールから引き継がれた様々な機能などです。
また、概念活性化ベクトルを用いたテスト手法による公正性分析のサポートも組み込まれています。また、より一般的なMLシステムの解釈可能性と説明可能性は、私たちのResponsible AIビジョンの重要な部分でもあります。
DeepMindとの協力により、私たちは自己教師学習したAlphaZeroチェスシステムにおける人間のチェス概念の獲得を理解することに前進しました。
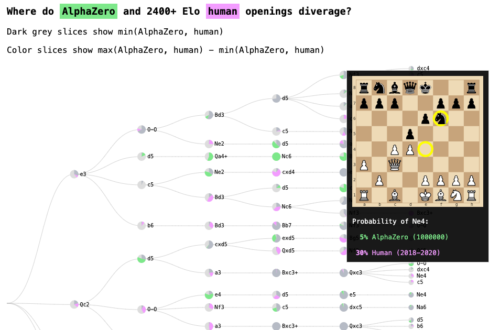
「Acquisition of Chess Knowledge in AlphaZero, Online Supplement」で公開されているオンラインツールを使って、AlphaZeroがチェスについて学んだかもしれないことを探ってみてください。
また、Responsible AIを欧米の文脈にとらわれず、視野を広げることにも力を入れています。
私たちの最近の研究では、西洋の制度やインフラに基づいた従来のアルゴリズムによる公平性の枠組みの様々な前提が、非西洋的な文脈でどのように破綻する可能性があるかを検証しています。
そして、インドにおける公正性研究をいくつかの方向から再文脈化するための道筋を提供しています。私たちは、AIに関する認識や嗜好をよりよく理解するために、いくつかの大陸で積極的に調査研究を行っています。
欧米のアルゴリズム公正研究の枠組みは、ほんの一握りの属性に焦点を当てる傾向があるため、非欧米の文脈に関するバイアスはほとんど無視され、経験的にも十分に研究されていません。
このギャップに対処するため、私たちはミシガン大学と共同で、NLPモデルにおいてより広い地域文化的文脈における語彙の偏りを強固に検出する弱い教師あり学習を使った手法を開発しました。この方法は、地理的文脈における攻撃的な言語と無害な言語に対する人間の判断を反映するものです。
さらに、農家を中心に考えるML研究の提案など、南半球で評価される文脈へのMLの応用を模索しています。
このような取り組みを通じて、MLを活用したソリューションを零細農家の生活や地域社会を改善するためにどうすればよいかを考えるよう、この分野に働きかけていきたいと考えています。
MLのパイプラインのすべての段階でコミュニティのステークホルダーを巻き込むことは、MLを責任を持って開発・展開し、最も重要な問題への取り組みに集中するための鍵になります。
このような観点から、私たちは外部の教員、NPOのリーダー、政府およびNGOの代表者による「健康公平性研究サミット(Health Equity Research Summit)」を開催しました。
このサミットでは、問題解決へのアプローチの仕方から努力の成果を評価する方法まで、MLエコシステム全体に公平性をもたらす方法について議論されました。
コミュニティベースの研究手法は、デジタル・ウェルビーイングの設計や、ASRシステムを使用する黒人アメリカ人の経験に対する理解を深めるなど、MLシステムにおける人種的平等の問題への取り組みにも活かされています。
また、家族の介護をサポートするなど、人生の大きなイベント時に社会技術的なMLシステムがどのように役立つかを知るために、より広く一般の人々の意見を聞いています。
MLモデルがより高性能になり、多くの領域に影響を与えるようになった現在、MLで用いられる個人情報の保護は、引き続き重要な研究課題となっています。
この線に沿って、私たちの最近の研究のいくつかは、大規模モデルにおけるプライバシーを扱っており、大規模モデルから学習データを抽出できる場合があることを強調するとともに、大規模モデルにおいてプライバシー保護をどのように実現できるかを指摘しています。この例には例えば差分プライベートBERTがあります。
前述の連合学習と連合分析に関する研究に加え、私たちは差分プライバシーを確保するための他の原理的かつ実用的なML技術でツールボックスを強化してきました。
例えば、プライベートクラスタリング、プライベートパーソナライゼーション、プライベート行列補完、プライベート重み付きサンプリング、プライベート分位点、半空間のプライベートロバスト学習などです。
また、一般には、サンプル効率の良いプライベートPAC学習が挙げられます。さらに、ラベルプライバシーやユーザー対アイテムレベルプライバシーなど、異なるアプリケーションや脅威モデルに適応できるプライバシー概念のセットを拡張しています。
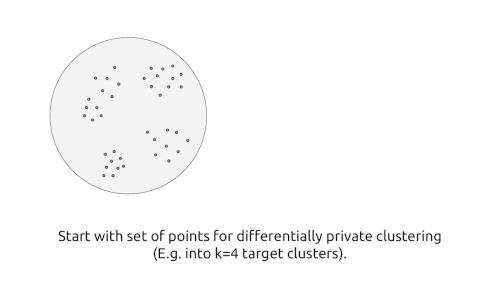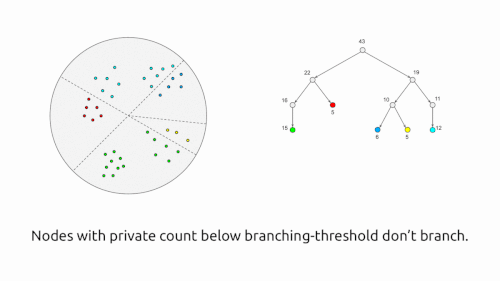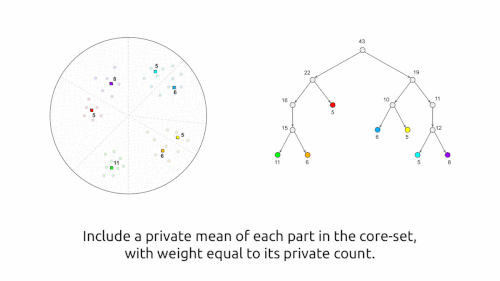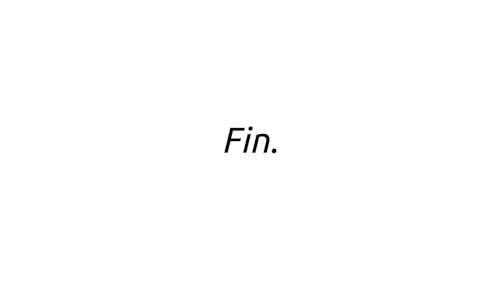
差分プライべートクラスタリングアルゴリズムの視覚的説明
3.Google Research:2022年以降にAIはどのように進化していくか?(5/6)関連リンク
1)ai.googleblog.com
Google Research: Themes from 2021 and Beyond
2)h01-release.storage.googleapis.com
Gallery | H01 Release
3)storage.googleapis.com
Acquisition of Chess Knowledge in AlphaZero, Online Supplement
