
1.TracIn:トレーニング事例の影響を推定する簡単な方法(1/2)まとめ
・トレーニングデータの品質はモデルのパフォーマンスに大きな影響を与える可能性がある
・様々な手法が提案されているが追加リソースやトレーニングが必要であり採用が困難
・TracInはこの課題に取り組むためのシンプルで規模拡大可能なアプローチ
2.TracInとは?
以下、ai.googleblog.comより「TracIn — A Simple Method to Estimate Training Data Influence」の意訳です。元記事の投稿は2021年2月5日、Frederick LiuさんとGarima Pruthiさんによる投稿です。
影響(influence)に関連する過去記事には以下のものがあります。
・DVRL:強化学習を使って学習用データの影響を推定
・MentorMix:現実世界の誤ラベルがディープラーニングに及ぼす影響を調査
醜いアヒルの子をイメージしたアイキャッチ画像のクレジットはPhoto by Michal Matlon on Unsplash
機械学習(ML:Machine Learning)モデルのトレーニングデータの品質は、そのパフォーマンスに大きな影響を与える可能性があります。データ品質の尺度の1つは、「影響(influence)」の概念です。つまり、特定のトレーニング事例がモデルとその予測パフォーマンスに影響を与える程度です。影響はMLの研究者にはよく知られている概念ですが、深層学習モデルの背後にある複雑さは、サイズ、特徴表現、データセットの増大と相まって、影響の定量化を困難にしています。
最近、影響を定量化するためにいくつかの手法が提案されています。1つまたは複数のデータポイントを削除して再トレーニングする際の精度の変化に依存するものもあれば、確立された統計手法を使用するものもあります。例えば、入力ポイントのわずかな変化の影響を推定する影響関数や、予測をトレーニング事例と重要度の加重組み合わせに分解する手法などです。
更に他のアプローチでは、強化学習を使用したデータ評価など、追加の推定量を使用する必要があります。これらのアプローチは理論的には健全ですが、製品に採用する事は、それらを大規模に実行するために必要なリソースまたはトレーニングにかかる追加の負担があるため制限されています。
NeurIPS 2020でスポットライトペーパーとして公開された「Estimating Training Data Influence by Tracing Gradient Descent」では、この課題に取り組むためのシンプルで規模拡大可能なアプローチであるTracInを提案しました。
TracInの背後にある考え方は単純です。トレーニングプロセスを追跡して、個々のトレーニング事例にアクセスしたときの予測の変化を捕捉します。TracInは、様々なデータセットから誤ってラベル付けされた例や外れ値を見つける際に効果的であり、各トレーニング事例に影響スコアを割り当てることで、(特徴表現ではなく)トレーニング事例の観点から予測を説明するのに役立ちます。
TracInの根底にあるアイデア
深層学習アルゴリズムは通常、確率的勾配降下法(SGD:Stochastic Gradient Descent)と呼ばれるアルゴリズム、またはその亜種を使用してトレーニングされます。
SGDは、データに対して複数回の試行を行い、モデルパラメータを変更して、試行毎に損失(つまり、モデルの目的)を局所的に削減することで動作します。
具体例を以下の画像分類タスクで示します。モデルのタスクは、左側の与えられたテスト事例の被写体(ズッキーニ)を予測することです。
モデルはトレーニングを進めるにつれて、様々なトレーニング事例に出会います。各トレーニング事例は、テスト事例の損失に影響を与えます。ここで、損失とは「予測スコア」と「実際のラベル」に関する関数です。ズッキーニ(zucchini)の予測スコアが高いと損失は低くなります。
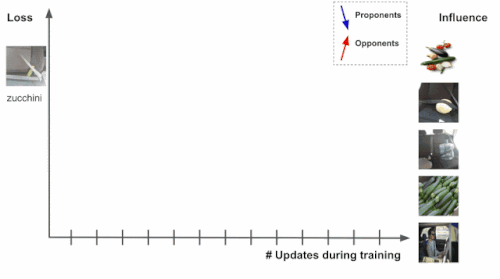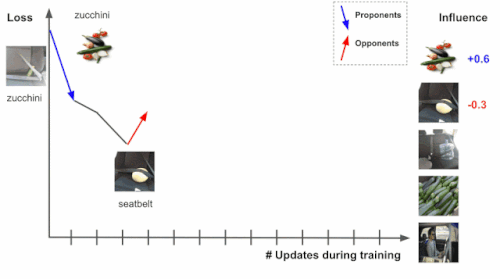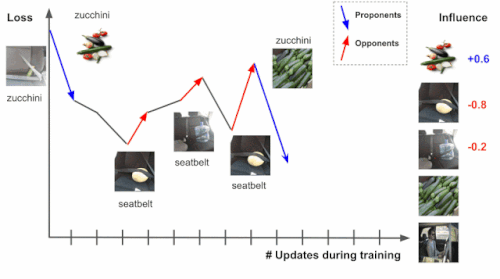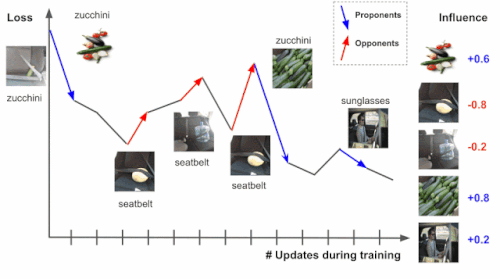
右端の画像がトレーニング中にズッキーニの損失に与える変化を追跡することによって、トレーニング事例の影響を推定します。
テスト事例がトレーニング時にわかっていて、トレーニングプロセスが各トレーニング事例を一度に1つずつ処理したとします。トレーニング中に、特定のトレーニング事例を処理すると、モデルのパラメータが変更され、その変更により、テスト事例の予測/損失が変更されます。
トレーニングプロセスを通じてトレーニング事例(シートベルト)を追跡できれば、テスト事例(ズッキーニ)の損失または予測の変化は、問題のトレーニング事例(シートベルト)に起因する可能性があります。ここで、トレーニング事例の影響は、トレーニング事例の処理階数全体の累積属性になります。
トレーニング事例には2つのタイプがあります。
上記のズッキーニの画像のように損失を減らすものは「支持者(proponents)」と呼ばれ、シートベルトの画像のように損失を増やすものは「反対者(opponents)」と呼ばれます。
前述の例では、「サングラス」というラベルの付いた画像も支持者です。画像にはシートベルトが写っており、「サングラス」という誤ったラベルが付いていますが、モデルがズッキーニとシートベルトをよりよく区別出来るように駆り立てているためです。
実際には、テスト事例はトレーニング時に不明です。これは、学習アルゴリズムによって出力されたチェックポイントをトレーニングプロセスの見取り図として使用することで克服できる制限です。
もう1つの課題は、学習アルゴリズムが通常、個別ではなく一度に複数の事例を処理する事です。これに対処するためには、各トレーニング事例の相対的な寄与の内訳を解きほぐす方法が必要です。これは、事例毎の損失勾配を適用することで実現できます。
これらの2つの戦略を共に行う事でTracInメソッドを捕捉できます。これは、テスト事例とトレーニング事例の損失勾配の内積の単純な形式に還元でき、学習率で重み付けされ、チェックポイント全体で合計されます。
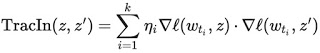
TracInの簡単な数式表現
トレーニング事例(z)とテスト事例(z’)の損失勾配の内積は、さまざまなチェックポイントでの学習率(ηi)によって重み付けされ、合計されます。
あるいは、代わりに予測スコアへの影響を調べることもできます。これは、テスト事例にラベルがない場合に役立ちます。この形式では、テスト事例の損失勾配を予測勾配に置き換えるだけで済みます。
3.TracIn:トレーニング事例の影響を推定する簡単な方法(1/2)関連リンク
1)ai.googleblog.com
TracIn — A Simple Method to Estimate Training Data Influence
2)arxiv.org
Estimating Training Data Influence by Tracing Gradient Descent
3)github.com
frederick0329 / TracIn

