
1.Deep Bootstrap Framework:データが無限に存在する世界ではディープラーニングはどうなるか?(1/2)まとめ
・通常、モデルは有限のサンプルを使ってトレーニングをされるのでデータは再利用される
・データが無限に存在する理想的な世界では再利用が不要になるので挙動が変わるか調査
・驚いた事にモデルは再利用データか新しいデータかをある意味で気にしていなかった
2.Deep Bootstrap Frameworkとは?
以下、ai.googleblog.comより「A New Lens on Understanding Generalization in Deep Learning」の意訳です。元記事の投稿は2021年3月10日、Hanie SedghiさんとPreetum Nakkiranさんによる投稿です。
これ、非常に面白いお話なのですが、あまりにも直感に反しすぎてエポック(Epoch)やバッチサイズ(Batch Size)などの自分が理解しているつもりの単語が良くわからなくなってしまう感覚に襲われたのですが、同じような感覚を覚えた方は「EpochとBatch SizeとIterationsの違い」をどうぞ。
新しい視点をイメージしたアイキャッチ画像のクレジットはPhoto by jamie-fenn on Unsplash
一般化(generalization)を理解することは、ディープラーニングにおける根本的な未解決の問題の1つです。限られたトレーニングデータでモデルを最適化すると、トレーニング時に使われていないテストセットでも良好なパフォーマンスが得られるのはなぜでしょうか?この問題は機械学習で広く研究されており、50年以上の歴史があります。
現在、研究者が特定のモデルの一般化を理解するのに役立つ多くの数学的ツールがあります。しかし、残念ながら、これらの既存の理論のほとんどは、最新のディープネットワークに適用すると失敗します。現実世界の設定では、既存の理論は空虚で予測に役立ちません。理論と実践の間にあるこのギャップは、過剰にパラメーター化されたモデル(overparameterized models)で最大になります。モデルは、理論的にはトレーニングデータセットに過剰適合する能力がありますが、実際にはそうならない事がよくあります。
ICLR 2021で受理された論文「The Deep Bootstrap Framework:Good Online Learners are Good Offline Generalizers」では、では、一般化をオンライン最適化と結びつける事により、この問題に取り組むための新しいフレームワークを紹介します。
私達は通常、モデルを有限のサンプルセットを使ってトレーニングを行い、複数のエポックで再利用します。ただし、オンライン最適化では、モデルはサンプルが無限に提供される無限ストリームにアクセスでき、このストリームの処理中に繰り返し更新できます。本研究では、無限データで迅速にトレーニング可能なモデルは、代わりに有限データを使ってトレーニングした場合にもよく一般化できるモデルであることがわかりました。この結び付きにより、実践的なモデル設計選択に新しい視点がもたらされ、理論的な観点から一般化を理解するためのロードマップが作成されます。
The Deep Bootstrap Framework
Deep Bootstrapフレームワークの主なアイデアは、有限のトレーニングデータが存在する「現実の世界(Real World)」と、無限のデータが存在する「理想的な世界(Ideal World)」を比較することです。これらを次のように定義します。
(1)現実の世界
Real World(N, T):T回のミニバッチで確率的勾配降下法(SGD)ステップを行うために、学習したい分布からN個の学習用サンプルを取得してモデルをトレーニングします。通常の学習時と同様、複数のエポックで同じN個のサンプルを再使用します。これは、経験的損失(トレーニングデータの損失)でSGDを実行することに対応し、教師あり学習の標準的なトレーニング手順です。
(2)理想的な世界
Ideal World (T):T回のステップに対して同じモデルをトレーニングしますが、各SGDステップは分布から新鮮なサンプルを使用します。つまり、まったく同じトレーニングコード(同じオプティマイザー、学習率、バッチサイズなど)を使って実行しますが、サンプルを再利用するのではなく、各エポックでは新しい学習用データを取得します。この理想的な世界の設定では、事実上無限の「学習用データセット」があり、学習時エラーとテスト時エラーの間に違いはありません。
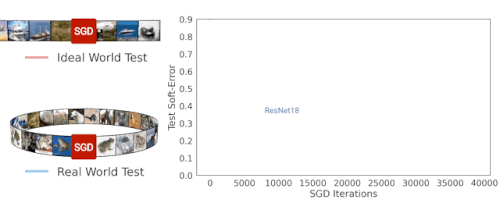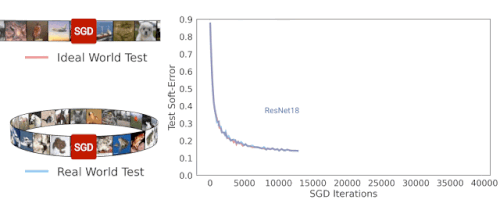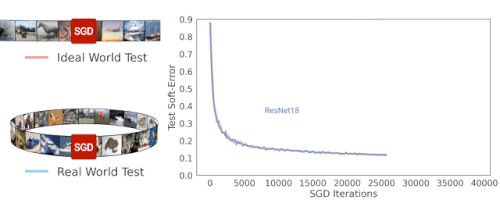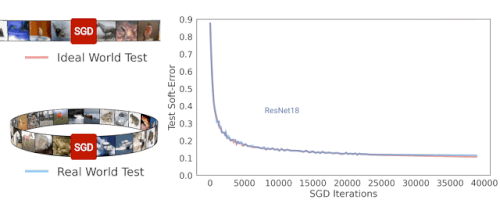
ResNet-18アーキテクチャのSGD反復トレーニング中に、理想的な世界と現実の世界のソフトエラーをテストしています。両者のエラーが類似していることがわかります。
演繹的に考えると、現実の世界ではモデルが分布から有限数のサンプルを取得するのに対し、理想の世界ではモデルは分布全体を取得するので、現実の世界と理想の世界は互いに関係がないと予想するかもしれません。しかし実際には、実際のモデルと理想的なモデルには実際に同様のテストエラーがあることがわかりました。
この観測を定量化するために、CIFAR-5mと呼ばれる新しいデータセットを作成して理想的な世界の設定をシミュレートしました。CIFAR-10で生成モデルをトレーニングし、それを使用して約600万枚の画像を生成しました。データセットの規模は、モデル規模の観点から「実質的に無限」になるように選択されているため、モデルが同じデータをリサンプリングすることはありません。つまり、理想的な世界として、モデルはまったく新しいサンプルのセットを確認します。

CIFAR-5mのサンプル
以下の図は、いくつかのモデルのテストエラーを示しており、現実の世界の設定(つまり、データを再利用する)と、理想的な世界(常に新しいデータを利用する)でCIFAR-5mデータをトレーニングしたときのパフォーマンスを比較しています。青い実線は、標準のCIFAR-10ハイパーパラメータを使用して100エポックの50,000サンプルでトレーニングされた実世界のResNetモデルを示しています。青い破線は、一度に500万サンプルを与えてトレーニングした、理想的な世界での対応モデルを示しています。驚いた事に、これらの世界には非常によく似たテストエラーが存在します。モデルは、再利用されたサンプルなのか、新しいサンプルなのかを、ある意味で「気にしていません」。
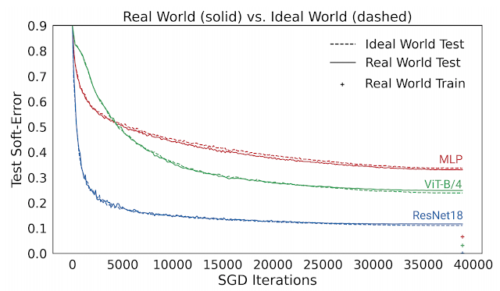
現実世界のモデルは100エポックの50Kサンプルでトレーニングされ、理想世界のモデルは単一エポックで500万サンプルでトレーニングされました。線は、テストエラーとSGDステップ数の関係を示しています。
これは、多層パーセプトロン(赤)、ビジョントランスフォーマー(緑)などの他のアーキテクチャー、およびアーキテクチャー、オプティマイザー、データ分散、サンプルサイズを変更した他の多くの設定にも当てはまります。
3.Deep Bootstrap Framework:データが無限に存在する世界ではディープラーニングはどうなるか?(1/2)関連リンク
1)ai.googleblog.com
A New Lens on Understanding Generalization in Deep Learning
2)arxiv.org
The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers
3)github.com
preetum / cifar5m
