
1.実用的な差分プライベートクラスタリング(1/2)まとめ
・k-meansクラスタリングは機密性の高いデータセットを処理する際は問題がある
・データポイントが他と大幅に離れていると単一のクラスタを構成してしまうため
・差分プライバシー方式でk-meansクラスタリング可能な新しいアルゴリズムを設計
2.差分プライベートクラスタリングとは?
以下、ai.googleblog.comより「Practical Differentially Private Clustering」の意訳です。元記事の投稿は2021年10月21日、Alisa ChangさんとPritish Kamathさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Annie Spratt on Unsplash
過去数年にわたって、機密データを処理するためのプライバシーセーフな手法が進歩しました。たとえば、通勤や通学など人の流れに関する洞察を発見したり、RAPPORなどの連合分析(federated analytics)のために使用されています。2019年に、開発者や団体が差分プライバシーを提供できるようにするオープンソースライブラリをリリースしました。これは、強力で広く受け入れられているプライバシーの数学的概念です。差分プライバシーデータ分析は、組織がデータの塊から洞察を学習してリリースできるようにすると同時に、それらの結果によって個々のユーザーのデータを区別または再識別できないことを数学的に保証する原理的なアプローチです。
本投稿では、以下の基本的な問題について検討します。
ユーザーに関するいくつかの属性を含むデータベースがある場合、意味のあるユーザーグループを作成し、その特性を理解するにはどうすればよいでしょうか?
重要なのは、手元のデータベースに機密性の高いユーザー属性が含まれている場合、個々のユーザーのプライバシーを損なうことなく、これらのグループの特性をどのようにして明らかにできるかです。
このようなタスクは、幅広いでは、教師なし機械学習の基本的な構成要素であるクラスタリングの一種です。クラスタリング手法は、各データポイントをグループに分割し、それぞれのデータポイントを最も類似しているグループに割り当てる方法を提供します。
k-meansクラスタリングアルゴリズムは、そのような影響力のあるクラスタリング手法の1つです。ただし、機密性の高いデータセットを操作する場合、個々のデータポイントに関する(個人の特定につながる情報など)重要な情報が明らかになる可能性があり、対応するユーザーのプライバシーが危険にさらされる可能性があります。
本日、新しい代表的なデータポイントをプライベートに生成することに基づいた、差分プライバシーライブラリに新しい差分プライベートクラスタリングアルゴリズムを追加する事を発表します。複数のデータセットでそのパフォーマンスを評価し、既存手法と比較して、競争力のある、またはより優れたパフォーマンスがある事を示します。
K-meansクラスタリング
k-meansクラスタリングの目標は、クラスターセンター(cluster center)と呼ばれる(最大で)k個のポイントを識別する事です。
データポイントの集合が与えられると、「各データポイントと最も近い位置にあるクラスタセンターまでの距離」の二乗の合計が最小となるようなクラスターセンターを求めようとします。これにより、データポイントの集合がk個のグループに分割されます。さらに、新しいデータポイントを追加した際も、最も近いクラスターセンターが何処か調べる事によりグループを割り当てることができます。
ただし、クラスターセンターの集合を公開すると、特定のユーザーに関する情報が漏洩する可能性があります。たとえば、特定のデータポイントが他のポイントから大幅に離れているとしましょう。標準のk-meansクラスタリングアルゴリズムはこのデータポイントのためだけに特定のクラスタセンターを割り当てしまうため、この単一のデータポイントに関する関する機密情報を明らかにしてしまいます。これに対処するために、差分プライバシーのフレームワーク内でk-meansアルゴリズムを使用してクラスタリングするための新しいアルゴリズムを設計します。
差分プライベートアルゴリズム
ICML2021で公開された「Locally Private k-Means in One Round」では、データポイントをクラスタリングするための差分プライベートアルゴリズムを紹介しました。
このアルゴリズムには、クラスタリングを行う中央サーバからもユーザのプライバシーが守られるという、ローカルモデルでのプライベート性という利点があります。しかし、このようなアプローチは、中央のサーバーを信頼する必要があるプライバシーのモデルを用いたアプローチに比べて、必然的に大きな損失をもたらします。
以下では、同様に、中央サーバーモデルの差分プライバシーで動作するクラスタリングアルゴリズムを紹介します。
中央サーバは生データへの完全なアクセス権を持つほど信頼でき、個々のデータポイントに関する情報を漏らさない差分プライバシークラスタセンターを計算することが目的です。この中央モデルは、差分プライバシーの標準的なモデルと同じであり、データ収集プロセスの変更を必要としないため、非プライベートな手法との置き換えが容易です。
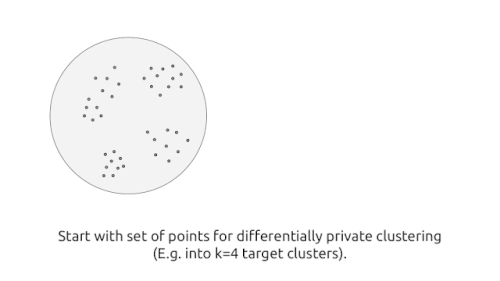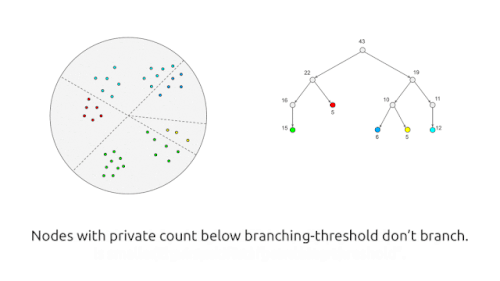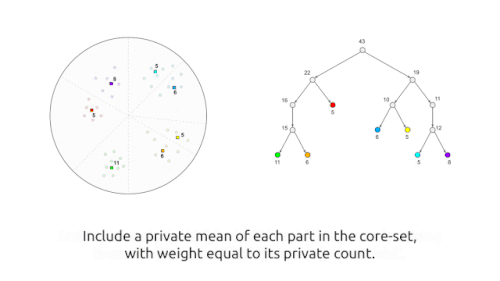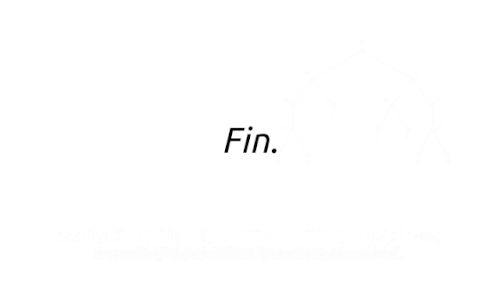
このアルゴリズムでは、まず、データポイントを「よく表現する」重み付けされたポイントで構成されるコアセットを、差分プライバシー方式で生成します。続いて、このプライベートに生成されたコアセットに対して、任意の(プライベートではない)クラスタリング・アルゴリズム(例えば、k-means++)を実行します。
簡単に説明すると、このアルゴリズムでは、まず、ランダム・プロジェクションに基づくLocality-Sensitive Hashing(LSH)を再帰的に使用して、点を類似した点同士の「バケット(buckets)」に分割します。次に、各バケットを、「バケット内の点の平均値」と「バケット内の点の数に等しい重み」を持つ単一の点で置き換えることで、プライベートコアセットを生成します。しかし、これまで説明してきたように、このアルゴリズムはプライベートなものではありません。私たちは、バケット内の点の数と平均の両方にノイズを加えることで、各演算をプライベートな方法で実行することで、プライベートなものにしています。
このアルゴリズムは、バケットの数とバケットの平均に対する各点の寄与が、追加されたノイズによって隠されれ、アルゴリズムの動作が個々のポイントに関する情報を明らかにしないため、差分プライバシーを満たします。一方、バケット内の点の数が少なすぎると、(バケット内の点の数や平均値に)付加されたノイズが実際の値に比べて大きくなり、コアセットの品質が低下してしまうことになります。このトレードオフを実現するために、ユーザーが設定可能なアルゴリズムのパラメータで、バケットに入れることのできるポイントの数を制御できるようにしています。
アルゴリズムのイメージ図
3.実用的な差分プライベートクラスタリング(1/2)関連リンク
1)ai.googleblog.com
Practical Differentially Private Clustering
2)proceedings.mlr.press
Locally Private k-Means in One Round
3)github.com
differential-privacy/learning/clustering/

