
1.Brax:Colabで大規模分散システムを凌駕する強化学習用物理シミュレーションエンジン(1/3)まとめ
・強化学習は単純なタスクでも習熟するために数百万から数十億のデータが必要になる
・大規模分散システムを使えば迅速に強化学習をトレーニング可能だが使える人は限られている
・Braxは単一システムで大規模分散システムを凌駕する強化学習用物理シミュレーションエンジン
2.Braxとは?
以下、ai.googleblog.comより「Speeding Up Reinforcement Learning with a New Physics Simulation Engine」の意訳です。元記事は2021年7月15日、C. Daniel FreemanさんとErik Freyさんによる投稿です。
原理は理解出来ますが、現実感を感じられないレベルの劇的な性能向上に呆然として認識が追いついて来ず、故に驚きを感じる事が出来ないというわけのわからない感覚に襲われました。
アイキャッチ画像のクレジットはPhoto by Samuel-Elias Nadler on Unsplash
強化学習(RL:Reinforcement Learning)は、ロボットに物理的な世界を移動したり、操作する事を教える際に採用される人気のある手法です。これ自体を簡略化して、剛体(つまり、力が加えられても変形しない物理的な固体)間の相互作用として表現することができます。
RLは通常、実用的な時間でトレーニングデータの収集を容易にするために、シミュレーションを利用します。シミュレーションでは、多数の複雑な物体が近似的に表現され、関節部で接続されたモーター駆動される多数の剛体で構成されます。しかし、これには課題があります。RLエージェントが、歩く、ツールを使用する、おもちゃのブロックを組み立てるなどの単純なタスクでも習熟するには、数百万から数十億のシミュレーション用データが必要になることがよくあります。
シミュレーション用データをリサイクルすることでトレーニング効率を改善する進歩が見られましたが、一部のRLツールは、シミュレーションデータの生成を多くのシミュレーターに分散することで、この問題を回避しています。
これらの分散シミュレーションプラットフォームは、非常に迅速にRLをトレーニング可能で印象的な結果をもたらしますが、ほとんどの研究者がアクセスできない数千のCPUまたはGPUを備えた大規模なコンピューティングクラスターで実行する必要があります。
論文「Brax – A Differentiable Physics Engine for Large Scale Rigid Body Simulation」では、単一のTPUまたはGPUだけを使用して大規模なコンピューティングクラスターのパフォーマンスに匹敵する新しい物理シミュレーションエンジンを紹介します。
このエンジンは、単一のアクセラレータで機械学習(ML:Machine Learning)アルゴリズを使って数千の並列物理シミュレーションを効率的に実行できるように設計されています。更に、相互接続されたアクセラレータのポッドを使用して、数百万規模のシミュレーションにスムーズに規模を拡大できるように設計されています。
Colabを使って実行可能な形式で、シミュレーションエンジン、リファレンスとなるRLアルゴリズム、シミュレーション環境をオープンソースとして公開しました。この新しいプラットフォームを使用すると、従来のワークステーションを使用したセットアップと比較して100~1000倍高速なトレーニングが出来る事を以下に示します。
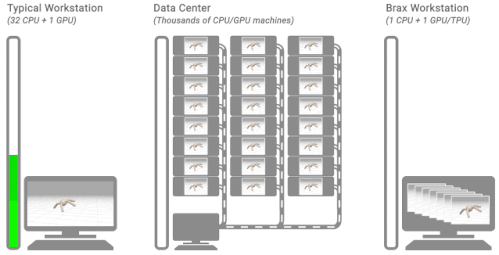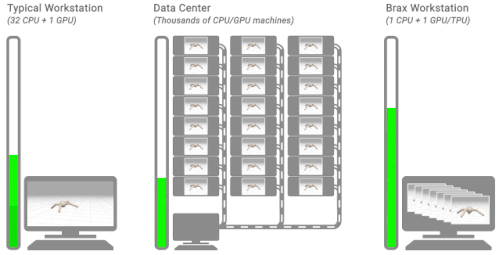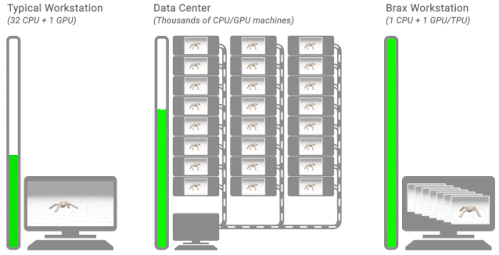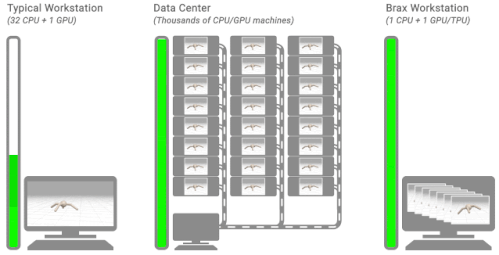
3種の典型的な強化学習のワークフロー
左図:典型的なワークステーションを使ったフローを示しています。単一のマシンで、CPU上の環境で、トレーニングには数時間または数日かかります。
中央図:典型的な分散シミュレーションフローを示しています。トレーニングは、シミュレーションを数千台のマシンに別けて実行し、数分かかります。
右図:Braxのワークフローを示しています。学習と大規模なバッチシミュレーションは、単一のCPU/GPUチップ上で並行して行われます。
物理シミュレーションエンジンの設計を改善する機会
剛体物理学(Rigid body physics)は、ビデオゲーム、ロボット工学、分子動力学、生体力学、グラフィックスとアニメーション、およびその他の分野で使用されています。このようなシステムを正確にモデル化するために、シミュレーターは重力、モーター作動、関節可動域、物体の衝突などからの力を統合して、時間の経過に伴う物理システムの動きをシミュレートします。
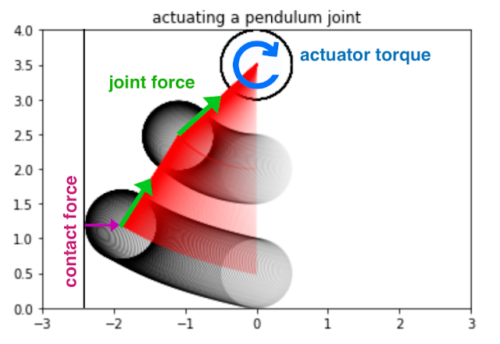
3つの球体、壁、2つの関節、および1つのモーター動力のシミュレーション
シミュレーションが進むにつれて、力とトルクが統合されて、各物理ボディの位置、回転、および速度が更新されます。
現在のほとんどの物理シミュレーションエンジンがどのように設計されているかを詳しく見てみると、効率を改善する大きな好機がいくつかあります。上で述べたように、典型的なロボット学習パイプラインは、1人の学習者が絶え間なくフィードバックを受けるように配置し、多くのシミュレーションを並行して実行しますが、この設計を分析すると、次のことがわかります。
(1)この配置は、非常に大きな遅延のボトルネックを課します。データはデータセンター内のネットワーク上を移動する必要があるため、学習者はシミュレータから経験を取得するために10,000ナノ秒以上待つ必要があります。もし、代わりに、この経験が学習者のニューラルネットワークと同じデバイス上にある場合、遅延は1ナノ秒未満に低下します。
(2)エージェントのトレーニングに必要な計算(シミュレーションステップ一回とそれに続くエージェントのニューラルネットワークの更新を一回行う)は、データのパッケージ化に費やされる計算に比べるとわずかなものです。データのパッケージ化とは、シミュレーションエンジン内でデータを送信に適した形式に変換し、次に送信用のProtocol Buffersなどに変換し、更にTCP用バッファーに変換する事です。その後、学習者側で受信した後にこれらすべての手順を逆に適用して元に戻す必要もあります。
(3)各シミュレーター内で行われる計算は非常に似ていますが、完全に同じではありません。
3.Brax:Colabで大規模分散システムを凌駕する強化学習用物理シミュレーションエンジン(1/3)まとめ
1)ai.googleblog.com
Speeding Up Reinforcement Learning with a New Physics Simulation Engine
2)arxiv.org
Brax — A Differentiable Physics Engine for Large Scale Rigid Body Simulation
3)github.com
google / brax
4)colab.research.google.com
Brax Training.ipynb

