
1.AutoRL:自動強化学習による長距離ロボットナビゲーションの実現(1/3)まとめ
・AutoMLの強化学習版であるAutoRLを使ってロボットを遠く離れた場所までお使いに行かせる研究
・現在のロボットは近距離を安全に移動するためのローカルプランナーの性能は向上している
・ローカルプランナーで扱える近距離を超えるためにAutoRLで既存の強化学習の課題解決に挑戦
2.AutoRLとは?
以下、ai.googleblog.comより「Long-Range Robotic Navigation via Automated Reinforcement Learning」の意訳です。元記事は2019年2月28日、Aleksandra FaustさんとAnthony Francisさんによる投稿です。強化学習を使ってロボットを学習させる研究は様々なものが発表されていますが、ニューラルネットワークを自動で作り上げるAutoMLの強化学習版であるAutoRLを使って、街にお使いに行かせる事が出来るレベルのロボットを開発しようと言うお話です。
米国だけでも、300万人もの人々が、自分の家から外出する事が困難な運動障害を持っています。自律的に長距離を移動できるサービスロボットは、例えば、食料品、薬品、および荷物を持ってくることによって、移動に困難がある人々の自立性を高めることができます。
深層強化学習(RL)は生のセンサー入力を望ましい行動にマッピングする能力に優れている事が研究によって実証されています。例えば 視覚センサーからの情報を元に物をつかむことや四足ロボットの移動などを学習する事です。
しかし、強化学習エージェントは通常、広大な物理空間についての理解を欠いています。物理空間についての理解は、人の手を借りずに長距離を安全に移動したり、新たな空間に容易に適応するために必要です。
直近の3つの論文「Learning Navigation Behaviors End-to-End with AutoRL」、「PRM-RL: Long-Range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning」「Long-Range Indoor Navigation with PRM-RL」では、私達は深層強化学習と長期計画(long-range planning)を組み合わせることによって、初めて経験する環境にも適応可能な自律型ロボットを研究しています。
障害物との衝突を避けながら近距離を安全に移動する基本的なナビゲーション動作を司る機能を「ローカルプランナー」と言います。ローカルプランナーは、障害物までの距離を測定する1D lidar(Laser Imaging Detection and Ranging:光検出と測距)などのノイズの多いセンサーで観測を行い、ロボットを制御するための線速度と角速度を出力します。
私達は、ローカルプランナーを、AutoRLを用いてシミュレーションで訓練しています。AutoRLは、強化学習の報酬関数およびニューラルネットワークアーキテクチャの探索を自動化してくれます。
ローカルプランナーの対応可能な範囲は10~15メートルという制限があるにも関わらず、AutoRLでシミュレーションしたローカルプランナーは現実世界のロボット操作にも、これまでに見たことのない新しい環境にも上手に学習結果を流用できます。
そのため、私達はこれをより広い空間でナビゲーションさせるための土台として使用する事にしました。私達は、ロードマップ、つまりノード(節)が拠点を意味し、各ノードは、ロボットがノイズの多いセンサーを使って実際の拠点間を移動可能な場合のみ線で接続されるようなグラフを作成しました。
Automating Reinforcement Learning (AutoRL)
最初の論文では、私達は小さな、静的な環境でローカルプランナーを訓練しました。ただし、DDPG(Deep Deterministic Policy Gradient)などの標準的な深層強化学習アルゴリズムを使用したトレーニングには、いくつかの課題があります。たとえば、ローカルプランナーの真の目的は目標を達成することであり、これは疎な報酬です。実際の学習時には、研究者が報酬を手動で反復し微調整する事が必要になりかなりの時間を費やす事になります。研究者はまた、明確に認められたベストプラクティスなしに(つまり試行錯誤しながら)、ニューラルネットワークの構造をどのようにするか決定を下さなければなりません。そして最後に、DDPGのようなアルゴリズムは安定的でなく、しばしば学習結果を壊滅的なレベルで忘れてしまう事があります。
これらの課題を克服するために、私たちは深層強化学習のトレーニングを自動化します。AutoRLは、大規模なハイパーパラメーター最適化を使用して最適な報酬関数およびニューラルネットワーク構造を探索する、深層強化学習を中心とした進化的自動化レイヤーです。これは、報酬関数探索とニューラルネット構造検索の2段階で機能します。
報酬関数検索の間、AutoRLはDDPGエージェントの集団を数世代にわたって同時に訓練します。各世代はローカルプランナーーの真の目的に最適化したわずかに異なる報酬関数を持ちます。報酬関数検索フェーズの最後に、エージェントを最も頻繁に目的地に導く報酬関数を選択します。ニューラルネットワークアーキテクチャー探索の段階では、選択した報酬を使用してネットワーク層を調整し、プロセスを繰り返します。
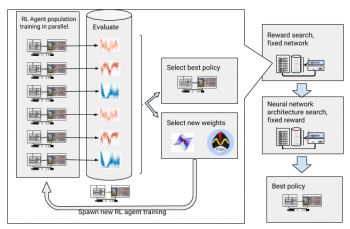
報酬関数とニューラルネットワークアーキテクチャの探索による強化学習の自動化
しかしながら、この反復プロセスは、AutoRLがサンプル効率的ではないことを意味します。1つのエージェントを訓練するためには500万サンプルが必要になります。100エージェントを10世代にわたってAutoRLでトレーニングするためには50億サンプルが必要です。これは32年間のトレーニングに相当します!
利点は、AutoRLによる手動トレーニングプロセスの自動化後では、DDPGの壊滅的な物忘れが出現していないことです。更に最も重要なのは、結果として得られるポリシーが高品質な事です。
AutoRLが作成するポリシーは、センサー、アクチュエーター、およびローカライゼーションノイズに対して堅牢であり、トレーニング時に見た事がないような新しい環境にも対応可能なレベルに一般化されています。
私達の最善のポリシーは、私たちのテスト環境内で他のナビゲーション方法よりも26%の成功率向上を達成しました。

見た事のない建物内での行動(10メートル以内)の比較。AutoRL(赤色)、手動調整のDDPG(濃い赤)、Artificial Potential Fields(ライトブルー)、Dynamic Window Approach(青)、Behavior Cloning(緑色)
現実世界の非構造化環境におけるロボットにAutoRLローカルプランナーをポリシー転送したデモ
これらのポリシーはローカルナビゲーションのみを実行しますが、障害物が存在する経路を移動する際も堅牢であり、非構造化環境(犬や人が突然経路を遮るような環境)でも実際のロボットを適切に制御します。
これは静的な障害物のみを用いてシミュレーションで訓練されましたが、動いている障害物に対しても効果的に対処する事ができます。
3.AutoRL:自動強化学習による長距離ロボットナビゲーションの実現(1/3)関連リンク
1)ai.googleblog.com
Long-Range Robotic Navigation via Automated Reinforcement Learning
2)ieeexplore.ieee.org
Learning Navigation Behaviors End-to-End With AutoRL
3)ai.google
PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
4)arxiv.org
Long-Range Indoor Navigation with PRM-RL
