
1.オフライン強化学習に関する楽観的な見解(2/2)まとめ
・教師あり学習のアンサンブル手法を応用してREMと言う新しい強化学習アルゴリズムを開発
・REMはオフライン設定とオンライン設定で比較するとオフライン設定の方が高い性能を出せていた
・オフライン強化学習の性能にはデータセットのサイズ、構成、及びアルゴリズムが関係する可能性がある
2.オフライン強化学習にとって重要な要素
以下、ai.googleblog.comより「An Optimistic Perspective on Offline Reinforcement Learning」の意訳です。元記事は2020年4月14日、Rishabh AgarwalさんとMohammad Norouziさんによる投稿です。
オフラインで学習を強化しているようにみえるアイキャッチ画像のクレジットはPhoto by Trent Szmolnik on Unsplash
オフライン強化学習のためのDQN Replay Dataset
以下では、最初にDQN Replay Datasetについて説明して、オフラインRLに戻ります。
このデータセットは、60のAtari 2600ゲームで、それぞれ2億フレーム分トレーニングしたDQNエージェントを使用して生成されています。
この際、スティッキーアクション(sticky actions:本件では25%の確率で、エージェントが選択したアクションではなく、エージェントが以前実行したアクションを実行するようにしています。何故、こんな事をするかというと、エージェントには「現在の状態に基いて最適な行動が何かを判断」して欲しいわけですが、ランダム性を取り入れないと詰将棋のように「特定の状態に強く依存した判断」を行ってしまう事があるためです)を使用して、問題をより困難にしています。
60ゲームのそれぞれについて、ランダムな初期化をした5つのDQNエージェントをトレーニングし、トレーニング中に発生した(状態、アクション、報酬、次の状態)の組をゲームごとに5つのリプレイデータセットに格納します。
この結果、合計300のデータセットができます。

DQN Replay Datasetを使用したAtariゲームでのオフラインRL
その後、DQN Replay Datasetを使用して、トレーニング中に環境とやり取りせずに、オフラインRLエージェントをトレーニングできます。各ゲームリプレイデータセットはImageNetの約3.5倍の大きさで、オンラインDQNの最適化が完了する前の学習中ポリシーからのサンプルも全て含まれています。
DQN Replay Datasetを使ったオフラインエージェントのトレーニング
DQN Replay Datasetを使って、DQNのオフライン版と分布型RLであるQR-DQNをトレーニングしました。
このオフラインのデータセットには、オンラインのDQNエージェントが体験したデータが全て含まれており、エージェントの性能はトレーニングが進むにつれて改善されていきます。そのため、オフラインエージェントのパフォーマンスは、トレーニングが完全に終了した後の最高のパフォーマンスのオンラインDQN(fully-trained DQN)エージェントと比較しています。
各ゲームについて、トレーニングされた5つのオフラインエージェント(データセットごとに1つ)をオンラインリターンを使用して評価し、最高の平均パフォーマンスをレポートしました。
オフラインDQNは、いくつかのゲームを除いて、「完全にトレーニングされたオンラインDQN」のパフォーマンスに及びません。ただし、同じ量のデータではより高いスコアを達成します。
一方、オフラインQR-DQNは、ほとんどのゲームでオフラインDQNおよび完全にトレーニングされたDQNよりも優れています。これらの結果は、標準のディープRLアルゴリズムを使用して、強力なエージェントをオフラインで最適化できることを示しています。更に、オフラインQR-DQNとDQNのパフォーマンスの違いは、オフラインデータを利用する能力の違いである事を示しています。
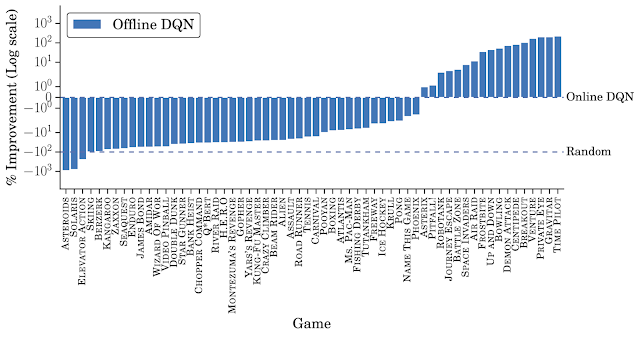
オフラインDQNの性能
「DQN Replay Datasetを使用してトレーニングされたオフラインDQN」と「完全にトレーニングされたDQN」のゲーム毎の比較図
「完全に訓練されたDQN」が0%、「ランダムな動きをするエージェント」が-100%になるように縦軸を正規化しています。
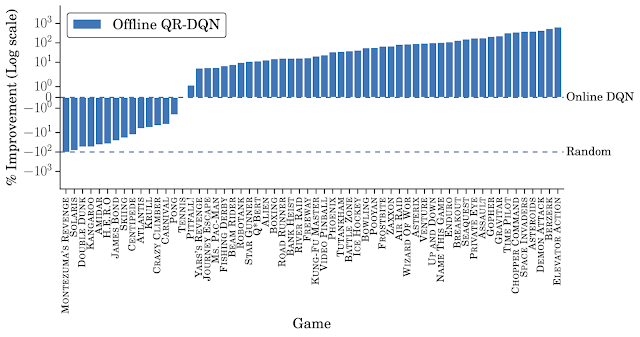
オフラインQR-DQNの性能
「DQN Replay Datasetを使用してトレーニングされたオフラインQR-DQN」と「完全にトレーニングされたDQN」のゲーム毎の比較図
2つの堅牢なオフラインRLエージェントの紹介
オンラインRLでは、エージェントは高い報酬につながると思われるアクションを選択し、修正フィードバックを受け取ります。
オフラインRLではデータが固定されているため、追加データをフィードバックとして受け取る事はできません。そのため、固定データセットを使用して一般化する方法について考える事が不可欠です。
以下に、「一般化を改善するためにモデルのアンサンブルを使用する教師あり学習の手法」を活用して、2つの新しいオフラインRLエージェントを提示します。
(1)Ensemble-DQN
DQNの単純な拡張であり、複数のQ値を推定してトレーニングを行い、それらをアンサンブルして評価します。
(2)REM(Random Ensemble Mixture)
ドロップアウトに着想を得た、実装が簡単なDQNの拡張です。
REMの主な直観は、もし複数のQ値が推定できるのであれば、それらを加重した組み合わせもQ値の推定値であると言う事です。
訳注
Q値1(達成可能な将来の最大の報酬1) x その重み1
Q値2(達成可能な将来の最大の報酬2) x その重み2
・・・
Q値N(達成可能な将来の最大の報酬N) x その重みN
で、1~Nの中からランダムにドロップアウトしながら学習していくイメージです。頭イイですね。
従って、各トレーニングステップで、REMは複数のQ値の推定をランダムに組み合わせ、このランダムな組み合わせを使用して堅牢なトレーニングを行います。
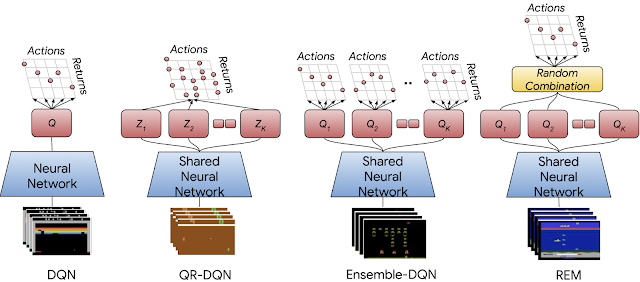
DQN、分布型QR-DQN、およびQR-DQNと同等なマルチヘッドアーキテクチャを持つニューラルネットワークアーキテクチャ(Ensemble-DQNおよびREM)の概要
QR-DQNでは、各ヘッド(赤い四角形)は特定の分布のリターンに対応しますが、Ensemble-DQNおよびREMでは、各ヘッドはQ関数を近似しています。
DQN Replay Datasetをより効率的に利用するために、オンラインDQNの5倍トレーニングを反復してオフラインエージェントをトレーニングし、そのパフォーマンスを以下で比較しました。
オフラインREMは、オフラインDQNおよびオフラインQR-DQNより優れています。強力な分布型エージェントであるC51をオンラインで完全に訓練した結果と比較しても、オフラインREMのパフォーマンス上昇はC51のパフォーマンス上昇よりも大きい事が示されています。
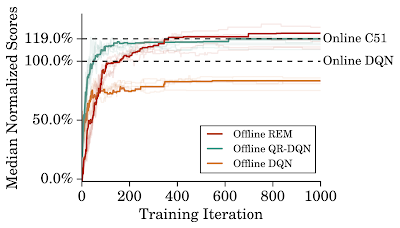
オフラインREMと他の基準モデルの比較
オフラインエージェントは60のAtariゲームのDQN Replay DatasetでオンラインDQNよりトレーニングを5倍反復しています。
Atariの標準トレーニングを使ってトレーニングすると、オンラインREMは標準のオンラインRL設定でQR-DQNと同等に機能します。これは、DQN Replay DatasetとオフラインRL設定から得られた洞察を使用して、効果的なオンラインRLメソッドを構築できることを示唆しています。
訳注:オフライン設定同士でREMとQR-DQNを比較するとREMの方が優れているけれども、オンフライン設定同士でREMとQR-DQNと比較するとほぼ同等のパフォーマンスになってしまうと言う事は、REMの性能を引き上げる何かの要因が「DQN Replay Dataset」もしくは「オフラインRL設定」に存在する可能性があると言う事ですね。
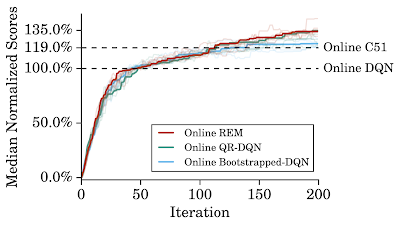
オンラインREMと他の基準モデルの比較
2億フレームでトレーニングしたオンラインエージェントで60のAtari 2600ゲームを5回実行し、平均スコアを正規化して中央値をグラフ化
4つのQネットワークを持つオンラインREMは、オンラインQR-DQNに匹敵します。
結果の比較:オフラインRLにとって重要な要素
これらの実験結果と、オフライン設定での標準的なRLエージェントの失敗を報告する過去の研究結果との不一致は、以下の要因が原因である可能性があります。
・オフラインデータセットのサイズ
DQN Replay Dataset全体をランダムに削減したデータを使ってオフラインQR-DQNとREMをトレーニングしてみました。データ削減時にデータ分布が変わらないようにしています。
教師あり学習と同様に、モデルのパフォーマンスはデータのサイズが大きくなるにつれて向上する傾向があります。
データセット全体のわずか10%で、REMとQR-DQNは「完全にトレーニングされたDQN」のパフォーマンスにほぼ一致します。
・オフラインデータセットの構成
DQNリプレイデータセットのゲーム毎に最初の2000万フレームでオフラインRLエージェントをトレーニングしました。オフラインREMとQR-DQNは、この低品質のデータセット内の最高のポリシー(訳注:つまりオンラインで2000万フレームを学習した後のポリシー)よりも優れています。これは、標準のRLエージェントが十分に多様なデータセットならばオフライン設定で適切に機能することを示しています。
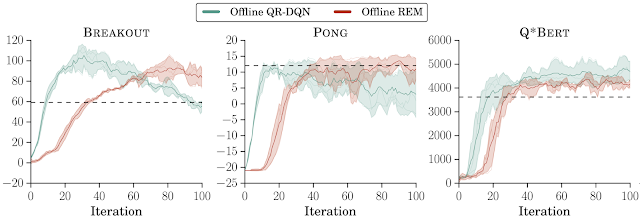
低品質なデータセットを使用したオフラインRL
DQNから収集した低品質なオフラインデータでトレーニングされたREMおよびQR-DQN
(DQNは各ゲームリプレイデータセットの最初の2000万フレームを使用し、20回の反復でトレーニング)横線は、このデータセット内の最高のポリシーのパフォーマンスを示していますが、これは「完全にトレーニングされたDQN」(訳注:つまり2億フレーム学習したポリシー)よりも大幅に性能が低いです。
・オフラインアルゴリズムの選択
標準のオフポリシーエージェントは、オフラインでトレーニングされている場合、継続的な制御タスク(continuous control tasks)には効果的でないという主張があります。ただし、TD3などの最近の継続的制御エージェントは、大規模で多様なオフラインデータセットでトレーニングすると、洗練されたオフラインエージェントと同等に機能することがわかりました。
将来の研究
今回の研究結果は、多様なポリシーで大規模に混合したオフラインデータから学習する時に、ニューラルネットワークによる一般化の役割を厳密に特性評価する必要を強調しています。
DQN Replayのサブサンプリング(例:最初または最後のk百万フレームのみを取り出す)など、様々なデータ収集戦略を使ってオフラインRLのベンチマークを行うことも、もう1つの重要な方向性です。
現在はオンラインポリシー評価を採用していますが、「真の」オフラインRLでは、ハイパーパラメーターの調整と早期停止(early stopping)のためにオフラインポリシー評価が必要です。
最後に、モデルベースのRLと自己教師学習アプローチは、オフラインRLにも有望です。
謝辞
この研究は、Dale Schuurmansと共同で実施されました。
貴重な議論をしてくださったGoogle Research、Brainチームのメンバーに感謝いたします。この研究の以前のバージョンは、NeurIPS 2019 DRL Workshopで一般発表されました。
3.オフライン強化学習に関する楽観的な見解(2/2)関連リンク
1)ai.googleblog.com
An Optimistic Perspective on Offline Reinforcement Learning
2)arxiv.org
An Optimistic Perspective on Offline Reinforcement Learning
3)offline-rl.github.io
An Optimistic Perspective on Offline Reinforcement Learning
4)console.cloud.google.com
atari-replay-datasets
5)incompleteideas.net
Reinforcement Learning: An Introduction second edition(PDF)


コメント