
1.T5:Text-To-Text Transfer Transformerと転移学習の探索(2/3)まとめ
・NLP用の転移学習に導入されたアイデアと手法を広範囲にわたって調査して有用な知見を多く得た
・体系的な研究から得た最良の方法を組み合わせてGoogle Cloud TPUアクセラレータで規模を拡大
・最大のモデルはGLUE、SuperGLUE、SQuAD、及びCNN/Daily Mailベンチマークで最先端のスコアを達成
2.NLPにおける転移学習の体系的研究
以下、ai.googleblog.comより「Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer」の意訳です。元記事の投稿は2020年2月24日、Adam RobertsさんとColin Raffelさんによる投稿です。T5そのものも注目を集めている凄いモデルと思いますが、医療用画像における転移学習の話と同様に、「何が最も転移学習を有効にしているのか?」が主題でT5はその研究の成果なんですね。アイキャッチ画像のクレジットはPhoto by Aleksey Boev on Unsplash
転移学習方法論の体系的研究
T5のtext-to-textフレームワークと新しい事前トレーニングデータセット(C4)を使用して、過去数年間にNLP用の転移学習に導入されたアイデアと手法を広範囲にわたって調査しました。調査の詳細は、以下の実験結果を含む私達の論文に記載されています。
・モデルアーキテクチャ
「エンコーダーデコーダーモデル」は一般に「デコーダーのみ」の言語モデルよりも優れていることがわかりました。
・事前学習の目標
空白入力スタイルのノイズ除去目標(fill-in-the-blank-style denoising objectives:一部の単語を空白に置き換えた入力文を与えて、その空白に入る単語を推測するようにモデルを訓練する事)が最も効果的であり、最も重要な要因は計算コストである事を確認しました。
・ラベルなしデータセット
分野を限定したデータ(ドメイン内データ)使った事前トレーニングは有益ですが、小さなデータセットで事前トレーニングする事は有害な過学習に繋がる可能性がある事を示しました。
・トレーニング戦略
マルチタスク学習は、トレーニング前に微調整を行うアプローチに匹敵しますが、各タスクでモデルをトレーニングする頻度を慎重に選択する必要があります。
・規模
モデルサイズ、トレーニング時間、およびアンサンブルモデルの数の規模を拡大して比較を行い、計算能力を固定した上で最大限に活用する方法を決定しました。
洞察 + 規模 = 最先端のスコア
NLPの転移学習の現在の限界を調査するため、私達は最終的な一連の実験を実行し、体系的な研究から得たすべての最良の方法を組み合わせて、Google Cloud TPUアクセラレータでこのアプローチを規模を拡大して実行しました。
私達の最大のモデルには110億のパラメーターがあり、GLUE、SuperGLUE、SQuAD、およびCNN/Daily Mailベンチマークで最先端のスコアを達成しました。特に刺激的な結果は、SuperGLUE自然言語理解ベンチマークで人間に近いスコアを達成したことです。このベンチマークは、機械学習モデルにとっては難しく、人間にとっては簡単な試験として設計されています。
訳注:ALBERTやReformerの例でもわかるようにパラメータの数が性能に直結するわけではなくパラメータが効率的に利用できているか否かが大切である事は大前提なのですが、Fakeニュースが作り放題になるかもと危惧された2019年2月のGPT-2が15億、2019年8月に世界最大のTransformerベースのAIモデルと発表されたNvidiaのMegatronが80億のパラメータ、2020年2月発表のどんな会話にも対応可能とされる驚異のチャットボットMeenaが26億のパラメータ、と考えるとT5の110億パラメータはMeenaの5倍弱、たぶん、T5は解説されてる以上の事が出来てしまうのだろうな、と思います。
拡張機能
T5は十分な柔軟性を備えているため、本論文で検討したタスク以外の多くのタスクに簡単に変更でき、多くの場合非常な成功を収めています。以下では、T5を2つの新しいタスクに適用しています。
「回答時に外部の知識を参照できない質問回答問題(closed-book question answering:クローズドブック質問回答)」と、「空白が一つとは限らない穴埋め問題(fill-in-the-blank text generation with variable-sized blanks)」です。
訳注:オープンブック試験とは本などの持ち込みが可能な試験の事です。それに対してクローズドブック試験は持ち込み不可な試験で自分の記憶のみを頼りに答える試験です。従来、人工知能は人間に比べて読解力が弱いと言う側面を指摘される事がありましたが、クローズドブック試験に対応可能と言う事は、読解した内容を「知識」として蓄えて「知識」を使って答える段階に達っしたと言う事です。
クローズドブック質問回答
text-to-textフレームワークが役に立つ用途の1つは、質問回答です。モデルは質問とともに文章を与えられ、文章内から質問の答えを見つけるように訓練されます。例えば「ハリケーンのコニーは何日に発生しましたか?」という質問とともに、ハリケーンのコニーに関するウィキペディアの記事のテキストをモデルに入力文として与える事ができます。このモデルは、日付「1955年8月3日」を記事から見つけるようにトレーニングされます。実際、このアプローチにより、スタンフォード質問回答データセット(SQuAD)で最新の結果を達成しました。
公開しているColab(t5-trivia)のデモおよびフォローアップの論文では、より難しい「クローズドブック」設定、つまり回答時に外部の知識を参照する事が出来ない状態でトリビア(豆知識)な質問に答えるようにT5をトレーニングしました。
言い換えれば、質問に答えるために、T5は、教師なしの事前トレーニング中に取得したパラメータに格納された知識のみを使用できます。これは、制約されたオープンドメインの質問回答の形式と考えることができます。
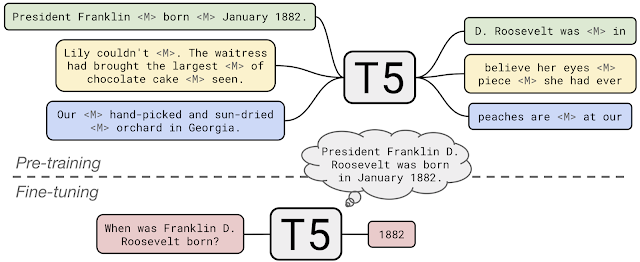
事前トレーニング中に、T5はC4のドキュメントから文章内の穴あき部分を(<M>で示されています)を埋めることを学習します。T5をクローズドブック質問回答に適用するために、追加の情報やコンテキストを入力せずとも質問に回答できるように微調整しました。これにより、T5は事前トレーニング中に内部化された「知識」に基づいて質問に回答しています。
3.T5:Text-To-Text Transfer Transformerと転移学習の探索(2/3)関連リンク
1)ai.googleblog.com
Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer
2)arxiv.org
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
3)github.com
google-research/text-to-text-transfer-transformer
4)www.tensorflow.org
TensorFlow リソース Datasets Catalog c4
5)colab.research.google.com
t5-trivia
6)t5-trivia.glitch.me
What does T5 know?

コメント