
1.Meena:どんな会話にも対応できるチャットボット(2/3)まとめ
・MeenaはOpenAI GPT-2と比較してモデル容量が1.7倍で8.5倍以上多いデータでトレーニングされている
・チャットボットの品質を評価する従来の評価基準はバラつきが出てしまうため新たな基準を開発した
・会話の分別度と具体度を測るSSAという新たしい基準で測定した所、Meenaは人間に迫るスコアを出した
2.SSAとは?
以下、ai.googleblog.comより「Towards a Conversational Agent that Can Chat About…Anything」の意訳です。元記事の投稿は2020年1月28日、Daniel AdiwardanaさんとThang Luongさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Max Hofstetter on Unsplash
トレーニングに使用される会話はツリースレッドとして編成されており、スレッド内の各返信は会話の1ターンです。
ツリースレッドから7ターン分の文章を抽出して会話トレーニング用のデータとしています。会話型モデルをトレーニングするのに十分な長さの文章である事と、メモリの制約にモデルを適合させる事のバランスを取って7を選択しています。(文章が長くなると、より多くのメモリが必要になります)。
Meenaは26億のパラメーターを持ち、パブリックドメインのソーシャルメディアの会話からフィルター処理された341GBのテキストでトレーニングされています。既存の最先端の生成モデルであるOpenAI GPT-2と比較して、Meenaのモデル容量は1.7倍であり、8.5倍以上多いデータでトレーニングされています。
人間による評価基準:分別度と具体度の平均(SSA:Sensibleness and Specificity Average)
チャットボットの品質を評価する既存の人間による評価基準は複雑になる傾向があり、評価者間で一貫した合意が得られません。これにより、自然な会話の基本的であるが重要な属性をキャプチャする、新しい人間の評価指標であるSensibleness and Specificity Average(SSA)を設計することになりました。
SSAを計算するために、テスト対象のチャットボット(Meenaおよび他の有名なオープンドメインチャットボット、特にMitsuku、Cleverbot、XiaoIce、およびDialoGPT)と自由形式で対話する事をクラウドソーシングで人間の評価者を募って実施しました。評価間の一貫性を確保するために、各会話は同じ挨拶「こんにちは!」で始まります。発言ごとに、評価者は「分別がありますか?(does it make sense?)」と「具体的ですか?(is it specific?)」という2つの質問に答えます。
評価者は、応答が文脈を意識して完全に合理的であるかどうかを判断するために常識を使用する事が求められます。混乱、非論理的、文脈から外れた、または事実上の誤りなど、何かがオカシイと思われる場合は、「分別がない」と評価する必要があります。
応答に分別がある場合、発話が評価されて、特定の文脈に固有であるかどうかが判断されます。例えば、Aが「テニスが大好き」と言い、Bが「それはいいね」と答えた場合、発話は「具体的ではない」とマークされるべきです。この応答は、様々な状況で使用可能な応答です。しかし、Bが「私もロジャー・フェデラーが好きで好きでたまらないの!」と応答した場合、「具体的」とマークされます。
訳注:ロジャー・フェデラーは史上最高のテニスプレーヤーとの評価もある、38歳の現在もなお、第一線で戦い続けるテニス界のレジェンドです。つまり、少しでもテニスに関心があったら間違いなく知っているレベルのスタープレーヤーで、且つ、欧米では日本よりテニス人気が高いとはいえ、会話の中でこの受け答えをちゃんと出来る人って、人間でもコミュニケーション能力が相当高い人ですよね。少なくとも私は英語のチャットで同じ受け答えができる自信はないです。ロジャー・フェデラーは双子のお子さんがいるとか割と詳しく知っているし、全豪の復活劇は感動的だったよね、と語れる位は好きですけれども、名前のスペルに自信がないので「oh, good!」とか適当な応答をして「具体的ではない」とマークされる可能性が高いです。GPT-2の時にも感じましたが、人工知能は英語の理解において非ネィティブを圧倒しつつありますね。
チャットボットごとに、1600 – 2400の会話が収集され、各会話では約100のヤリトリが行われます。各モデルの応答には人間の評価者がラベルを付けて、「分別度」かつ「具体度」が示されます。チャットボットのsensiblenessとは、「分別がある」とラベル付けされた回答の割合であり、specificityとは、「具体的」とマークされた回答の割合です。これら2つの平均がSSAスコアです。
以下の結果は、MeenaがSSAスコアの点で既存の最先端のチャットボットよりもはるかに優れており、人間のパフォーマンスに迫っている事を示しています。
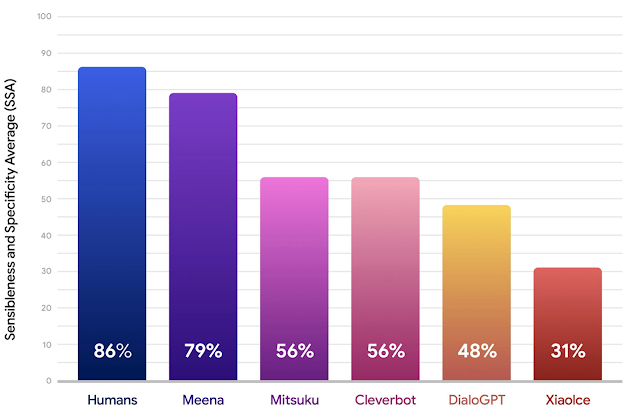
MeenaのSSAスコアを人間、Mitsuku、Cleverbot、XiaoIce、およびDialoGPTと比較した図
3.Meena:どんな会話にも対応できるチャットボット(2/3)関連リンク
1)ai.googleblog.com
Towards a Conversational Agent that Can Chat About…Anything
2)arxiv.org
Towards a Human-like Open-Domain Chatbot
