
1.強化学習における好奇心報酬とぐずぐず先延ばしの罠(1/2)まとめ
・強化学習は飴と鞭で人工知能を学習させるが飴も鞭もほとんど発生しない世界では学習できない
・好奇心を満たす事を報酬として組み込む手法が以前より研究されている
・今回発表された新しい手法では従来手法が陥るわなを回避する事ができる
2.強化学習に好奇心を報酬として持ち込む
以下、ai.googleblog.comより「Curiosity and Procrastination in Reinforcement Learning」の意訳です。Google BrainのNikolay SavinovさんとDeepMindのTimothy Lillicrapさんの共著です。後半はこちら
強化学習(RL)は、人工知能が何か正しいことをすると肯定的な報酬を与え、そうでなければ否定的な報酬を与え、この手順を繰り返して人工知能を学習させます。この飴と鞭アプローチは近年、最も関心を集めている研究の1つで、シンプルですが様々な事に応用可能です。DeepMindは強化学習の一種であるDQNアルゴリズムを使って古いAtari社のビデオゲームをプレイさせたり、AlphaGoZeroでは碁をプレイさせる事に成功しました。強化学習は、OpenAIがOpenAI-Fiveアルゴリズムで最新のビデオゲームであるDotaで人間に勝利する事にも貢献し、また、Googleがロボットに今まで見た事のない物体を掴む事ができるように学習させた際にも使われました。
しかし、これらの強化学習の成功にもかかわらず、これをもっと効果的なテクニックにするには多くの課題があります。標準的な強化学習アルゴリズムは、エージェントへのフィードバックがまばらな環境では苦労します。しかし、そのような環境は現実世界では一般的です。
一例として、大きな迷路のようなスーパーマーケットであなたの好きなチーズを見つける方法を学ぶことを想像してみてください。あなたは探し続けますが、チーズの棚はどこにも見つかりません。どちらの方向に向かっても飴も鞭もない場合、正しい方向に向かっているのかどうかを判断する方法がありません。
報酬がないのに、あなたが辺りを歩きまわるのは何故でしょうか?あなたが、探しているチーズと関係ない商品の棚を見てまわるのは、あなたに好奇心があるからです。
Google BrainチームとDeepMind、ETHZürichのコラボの成果である論文、「Episodic Curiosity through Reachability」では、私たちは、好奇心に似た報酬を強化学習エージェントに与えて周辺を探索させる、新しいエピソード型記憶モデルを提案します。私達は、エージェントに探索するだけでなく、元のタスク(チーズを見つける事)もして欲しいので、我々のモデルによって提供される報酬ボーナスをオリジナルのスパースタスク(疎なタスク:つまり飴も鞭もないタスク)に報酬として追加します。組み合わされた報酬はもはやスパースではなく、標準的な強化学習アルゴリズムがそこから学ぶことを可能にします。したがって、我々の好奇心を使った手法は、強化学習で解決可能なタスクの領域を拡張します。
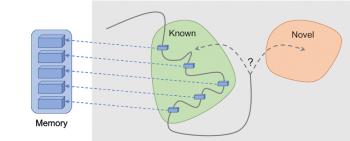
Episodic Curiosity through Reachability:エージェントが観測した結果はメモリに追加され、報酬は現在の観測がメモリ内の最も類似した過去の観測とどのくらい異なるかに基づいて計算されます。エージェントは、今までに観測した事のない結果を観測するとより多くの報酬を受け取る事ができます。
私たちの手法の重要なアイデアは、エージェントの観測結果をエピソード記憶に保存すると同時に、エージェントがメモリにまだない(つまりまだ訪れていない)場所に到達して観測することに報酬を与えることです。「記憶にない」ということは、私たちの手法における新規性の定義です。そのような観測を求めることは、未知のものを求めることを意味します。
見た事のない場所を求めてさまよう事は、人工知能エージェントを新しい場所に導きます。つまり、同じ場所を円を描いて彷徨う事を防ぎ、最終的に人工知能エージェントが目標に到達するのを助けます。
後に説明するように、私たちの今回の手法は、他の手法がしばしば陥る望ましくない挙動に人工知能エージェントが陥る事を防ぎます。驚いたことに、その望ましくない挙動とは、一般的に「procrastination(ぐずぐずと先延ばする)」と呼ぶれる行動にいくらか類似しています。
以前に提唱されたの好奇心を強化学習に導入する手法
過去にも強化学習に、好奇心を導入する試みはありました。本投稿では、自然で人気のある最近の論文「Curiosity-driven Exploration by Self-supervised Prediction」で提唱された予測ベースの驚きによる好奇心(一般的にICM法と呼ばれています)について注目してみます。驚きがどのように好奇心につながるかを説明するために、再びスーパーマーケットでチーズを探すという事例を考えてみましょう。
Indira Paskoによるイラスト
私達はお店の中を探索しているとき、無意識に未来を予測しています。「私はお肉の棚にいるので、次の棚は魚を扱った棚と思います。お肉と魚は通常、このスーパーマーケットでは隣接して配置されていますから」あなたの予測が間違っていると、あなたは驚きます。「おや?それは実際に野菜の棚でした。私はそれを予測していませんでした!」、そしてこの驚きが報酬となります。
これは、あなたの予測が現実と合っているかどうかを見てみるために、新しい場所を見て回るモチベーションを高めます。(そしてうまくいけば、チーズに出会う事ができます)
同様に、ICM方法では、世界を予測するモデルを構築し、モデルの予測が裏切られた場合にエージェントに報酬を与えます。これは驚きまたは新規性に対する報酬と見なす事ができます。ICMの好奇心の定義は、「未訪問の場所を探索する事」ではないことに着目してください。ICMでは、未訪問の場所を訪問する事はより多くの “驚き”を得る方法であり、そうすれば全体的な報酬は最大になります。しかし、いくつかの環境では、人工知能エージェントに驚きを与える他の方法があるのです。

迷路内でテレビに出会ったとき、驚きベースの好奇心で動作する人工知能エージェントはテレビに見入って立ち往生してしまいます。このGIF動画は、Deepak Pathakのビデオから引用しています。
(後半「強化学習における好奇心報酬とぐずぐず先延ばしの罠(2/2)」に続きます)
3.強化学習における好奇心報酬とぐずぐず先延ばしの罠(1/2)関連リンク
1)ai.googleblog.com
Curiosity and Procrastination in Reinforcement Learning
