1.人工知能は画像の何処に注目して画像認識をしているのか?まとめ
・Googleが人工知能が画像認識する際の学習過程可視化ツールlucidを公開
・画像の何処で何を検出し、どのような判断に影響したのかが明確になる
・人工知能のMRIとも言える非常に使い勝手が良いツールだが新たな問題も出てくるかも
2.人工知能の画像認識の過程
「人工知能は結論は教えてくれるが、どうしてその結論になるのか理由は教えてくれない」と言うのは長い間の定説であった。しかし、少なくとも画像認識においては過去の話になりつつある。
人工知能の学習過程の可視化の必要性は随分前から認識されていた。医療分野などでは人工知能の出した診断に説明力が求められる。「理由は良くわからないのですが、人工知能が貴方を糖尿病と言ってます」
と言われて納得する患者さんは少ないからだ。
去年、Googleは学習過程において個々のニューロンがどのように学習を洗練させていくかわかるデモを作った。人工知能は、最初は境界を認識し、次は質感、そして出現パターン、個々のパーツ、最終的に物体を認識する。

これは面白い実験ではあったが、個々のニューロンの学習が最終的に何に影響を及ぼしたのかは不明瞭であった。例えば、あるニューロンが犬画像から「たれ耳」を検出したとする。「たれ耳」はその画像が「ビーグル犬」なのか「ラブラドールレトリバー」なのか最終判断にどの程度の影響を及ぼすのだろうか?
今回のツールで
・画像のどこでたれ耳を検出したのか?
・たれ耳は最終的にどんな判断に結びついたのか?
がわかるようになった。いわば、人工知能のMRIを作り出したのだ。
このツールはlucid、及びもっと簡単に使えるようにしたcolab notebooksとして公開された。
3.lucidのデモ
犬の耳部分にカーソルを持っていくと「たれ耳(floppy ears)」が検出される。

猫の顔部分にカーソルを持っていくと「猫顔(cat heads)」が検出される。
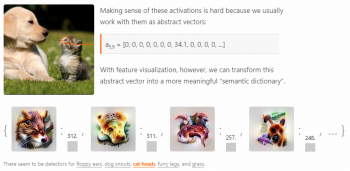
上記デモはdistill.pubで実際に自分で動かす事ができる。凄い事に対象画像を変更して色々と試す事も出来てしまうのでお試しあれ。
人工知能が「たれ耳」や「猫顔」でイメージする画像は相変わらず悪夢っぽいと言うかサイケデリックと言うか、人間がイメージする画像とはかけ離れている。しかし、私自身も「たれ耳」を頭の中でイメージしてもそんなにハッキリと耳のイメージを思い描けるわけではないので、人工知能の性能アップと共に解決していく問題なのだろうか。
lucidを使えば、人工知能が黒人の顔をゴリラと間違えた件が「画像の何処を見て間違えたのか?」が明確に出来そう。しかし、仮に「顔を見て間違えました」と言う結論になったら、それはそれで人工知能による差別や公平性、倫理と言った違う方向で大きな問題になりそうですね。
4.人工知能は画像の何処に注目して画像認識をしているのか?関連リンク
1)distill.pub
The Building Blocks of Interpretability
2)research.googleblog.com
The Building Blocks of Interpretability
3)github.com
tensorflow/lucid
