
1.学習データが少ない言語でテキスト読み上げシステムを作成まとめ
・コーパス(言語資料)が少ないマイナー言語でTTSを作る研究についての最終報告
・言語間で最大限に共有可能な音韻表現を設計し、それをベースに学習させた
・最終的には学習データにないOdia語を音声合成し、ネイティブからお墨付きを得た
2.マイナー言語でTTSを作成する方法
以下、ai.googleblog.comより、「Text-to-Speech for Low-Resource Languages (Episode 4): One Down, 299 to Go」の意訳です。
これは、コンピュータで扱いやすい形の言語資料が多くないマイナーな言語用のTTS(Text-to-Speech:文章読み上げシステム)を構築するために我々がやっている作業について報告した一連の記事の第4話です。2015年9月の最初のエピソードでは、Project Unisonのクラウドソースによる音声データ収集の取り組みについて説明しました。 2015年12月の2番目のエピソードでは、そのデータに基づいてパラメトリック音声をどのように構築したかを説明しました。 2016年2月の3番目のエピソードでは、TTSシステムの発音辞書の編集について説明しました。このエピソードでは、単一のTTSシステムで複数の言語を扱う方法を説明します。
任意の言語のTTSシステムを開発することは重要な課題ですが、それには高品質な音声データと言語に関するアノテーション(注釈)を大量に必要とします。このため、これらのシステムは、世界のメジャーな言語のごく一部でしか利用できません。
この状況で発生する自然な問題は、マイナーな言語では複数の話者の音声データを用いて高品質の音声データを大量に作成するのが難しい事です。前の3つのエピソードで説明したように、複数の話者が話す単一言語の音声データを元に単一言語用のTTSを作成する代わりに、複数の話者が話す複数言語の音声から限られた単一言語用データを何らかの形で組み合わせ、どのような言語も話すことができる単一の多言語音声読み上げシステムを構築する事ができるでしょうか?
1つのモデルで複数言語の音声合成を行える多言語TTSシステムを作成するために行った初期の調査結果をベースに、全ての言語で統一された音韻表現(IPA:国際音声アルファベット)を使用できる新しいモデルを開発しました。この表現を用いて訓練されたモデルは、訓練データ内の言語とデータ外の言語の両方を合成することができ、これには主に2つのメリットがあります。まず、関連する言語のトレーニングにより、カバーする音素が増え合成音声の品質が向上します。次に、モデル内には多くの言語が蓄えられているため、データ外の言語にも関連する情報が存在し、音声合成をガイドし助けてくれる可能性が高くなります。
インドネシア語と密接に関連する言語を探る
私達はこの多言語アプローチをインドネシアの言語に適用しました。インドネシアの公用語はIndonesian(インドネシア語)で、ネイティブ、もしくは第二言語としている話者が2億人以上います。続いて約9000万人のネイティブスピーカーを持つJavanese(ジャワ語)、および約4000万人のネイティブスピーカーを持つSundanese(スンダ語)がインドネシアの2大地域言語を構成しています。
自然言語処理を専門にするコンピュータ技術者や言語学者から長年注目を集めてきたインドネシア語と異なり、ジャワ語とスンダ語はともに、公開されている高品質のコーパス(言語資料)が多くありません。私たちは、インドネシアの大学と協力して、クラウドソースサービスを利用してジャワ語とスンダ語の音声データのレコーディングを行いました。
インドネシア語の標準コーパスは、プロのスタジオではるかに大規模に記録されていたため、3つの言語を組み合わせれば「古典的な」単一言語アプローチを使用して構築されたシステムに比べて大幅な改善がもたらされるという仮説がありました。
これを検証するために、我々はまず、これらの3つの言語の音韻間の類似点と重要な違いを分析し、これらの情報を使用して、言語間で最大限に共有を可能とする音韻表現を設計しました。
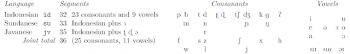
インドネシア語、ジャワ語、スンダ語の国際音韻アルファベット表記による音素目録
標準インドネシア語と共同で訓練された結果として得られたジャワ語とスンダ語の声は、ベースラインとして使用した単一言語版のマルチスピーカーの音声を品質で大きく上回りました。これによりGoogle翻訳やAndroidなどのGoogleサービスでジャワ語とスンダ語のTTSシステムを立ち上げることができました。
より多様な言語への拡大:南アジアの同様なケース
次に、我々は南アジアの言語に焦点を当てました。非常に異なった2つの言語、Indo-Aryan(インドアリアン語)とDravidian(ドラビディアン語)です。前述のインドネシア語とは異なり、これらの言語ははるかに多様です。特に、それらの音韻の重複が著しく小さいです。
下の表は、私達が実験で使用した言語のスーパーセットです。「文化(culture)」を意味するサンスクリット文字を翻訳した結果と具体的なつづり(orthography)、および発音の多様性を確認できます。これらの言語は、各グループ間のバラツキと類似性がない事を示しますが、幾つかのグループ間では類似性も示します。
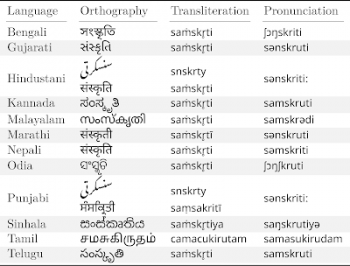
サンスクリット語の子孫にあたる言語の「文化」に相当する単語
この作業では前述の統一された音韻表現を最大限に活用し、私たちが持っている音声データに特定の音素データが不足している問題を解消しました。これは、多言語音素データ内の類似の音素を単一音素データに融合させることによって達成されました。私達は可能であれば、音韻的に近い言語同士で同じ音声目録(インベントリ)を使用します。例えば、我々はTeluguとKannadaのための同じ音素インベントリを持ち、West BengaliとOdiaのためのもう一つの音素インベントリを持っています。
GujaratiやMarathiのような他の言語のペアについては、ある言語のインベントリを別の言語のインベントリにコピーしましたが、音素インベントリの違いを反映するためにいくつかの変更が加えられました。
これらの実験で使用した全て言語は、類似の音素を異なるインベントリにマッピングする共通の基礎的表現を保持していました。そのため、私達はある言語のデータを他の言語のトレーニングに使用することができました。
さらに、私たちが使った代表表現では、綴りではなく、使用されている音韻によって分類されるようにしました。たとえば、Marathiの長母音と短母音では異なる文字が使われますが、音声的には異なっているわけではありません。そのため、私達は単一の表現を割り当てて、訓練データの堅牢性を高めました。
同様に、もし2つの言語が同じサンスクリット文字に歴史的に近いが音声的に異なる語を割り当ており、違う文字に音声的に近い語を割り当てていた場合、私達は歴史的経緯や綴りではなく、音韻的な近さを優先しました。統一された音素インベントリのすべての機能についての説明はこの記事の範囲外ですが、その詳細は論文で見つけることができます。
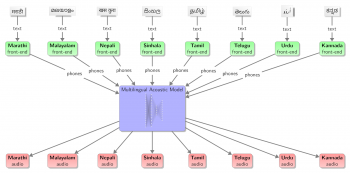
多言語テキスト読み上げの概念図。入力テキストは、言語固有の言語フロントエンドによって処理され、言語に依存しない音響モデルへの入力として機能し、共通の音素表現を生成します。人工知能はそれぞれの問い合わせに対して音声を生成します。
私たちの実験は、インドのBengali、Gujarati、Kannada、Malayala、Marathi、Tamil、Telugu、そしてUrduに焦点を当てました。ベンガル語(Bengali )とマラーティー語(Marathi)を除いて、これらの言語のほとんどでは、録音データと言語資料はクラウドーソーシングで集められました。
これらの言語のそれぞれについて、利用可能なすべてのデータを使用する多言語音響モデルを構築しました。加えて、音響モデルには、以前、クラウドーソーシングで集めたネパール語(Nepali)とシンハラ語(Sinhala)のデータ、ヒンディー語(Hindi)とバングラデシュベンガル語(Bangladeshi Bengali)が含まれていました。
結果は勇気づけられるものでした。ほとんどの言語で、多言語音声アプローチは従来の単一言語アプローチを使用して構築された音声よりも優れていました私達は、さらに野心的な実験を行いました。トレーニングデータがないOdia語を、南アジアの多言語モデルを使用して合成しようと試みたのです。
主観的な聴取テストでは、Odiaのネイティブスピーカーが、結果として出力された合成音声の内容を理解できわかりやすいと判断しました。スピーチチームと共同で多言語アプローチを使用して構築されたMarathi、Tamil、Telugu、Malayalamの音声合成は、最近の「Google for India」イベントで発表され、現在、Google翻訳や他のGoogleサービスに利用されています。
データ収集におけるグラウドソーシングの活用は、研究の観点からは興味深いものであり、ネイティブスピーカーコミュニティとの実り多い協力を確立するという面でも報酬がありました。Malayo-Polynesian語、Indo-Aryan語およびDravidian言語ファミリーの実験では、ディープラーニングを使用して単一の多言語音響モデルを複数の言語にまたがってデータを慎重に共有することで、マイナー言語の深刻なデータ不足問題が緩和され、得られた良質の音声はGoogleの製品で使用される事になりました。
このTTSの研究は、言語と言語技術を世界の多くの言語に適用するための第一歩です。より多く人がこの取り組みに参加することが私たちの希望です。
研究コミュニティに貢献するために、ネパール、シンハラ、ベンガル、クメール、ジャワ、スンダのためのオープンソースのコーパスを用意しました。私達はSLTUとInterspeechカンファレンスから戻ってきました。私たちは今後、プロジェクトで他の言語のデータセットを引き続き公開する予定です。
3.学習データが少ない言語でテキスト読み上げシステムを作成感想
ブログ発表を読んでいると華々しい成果が次から次へと発表されているように錯覚してしまいますが、本件もEpisode1の発表は2015年8月なので3年間の研究成果なのですね。
また、GoogleのTTSと言えばTacotron 2が有名ですが、特に記事内で言及がないので別のチームなのでしょうね。もちろん、Tacotron 2は流暢な発音を目指したTTSで、こちらはマルチリンガル対応を目指したTTSと違いはありますが、Tacotron 2もいずれは多言語対応を目指すでしょうし、本研究もいずれはより流暢な発音を目指すでしょうから、協力関係でありつつライバル関係でもあるのでしょうね。
4.学習データが少ない言語でテキスト読み上げシステムを作成関連リンク
1)ai.googleblog.com
Text-to-Speech for Low-Resource Languages (Episode 4): One Down, 299 to Go
Text-to-Speech for Low-Resource Languages (Episode 3): But can it say “Google”?
Text-to-Speech for Low-Resource Languages (Episode 2): Building a Parametric Voice
Crowdsourcing a Text-to-Speech Voice for Low-Resource Languages (Episode 1)
A Unified Phonological Representation of South Asian Languages for Multilingual Text-to-Speech
2)www.internationalphoneticassociation.org
International Phonetic Association

