
1.AndroidのSmart Linkifyを裏で支える機械学習まとめ
・メッセージングアプリ文章の住所や電話番号箇所に自動でリンクを張るSmart Linkifyの技術紹介
・リンクを張るべき対象か調べるFFNと対象の種類を調べるFFNの2つから実装されている
・モデルとコードは、Androidフレームワークの一環として公開されている
2.Android 9 PieでサポートされたSmart Linkifyとは?
以下、ai.googleblog.comより「The Machine Learning Behind Android Smart Linkify」の意訳です。
今週の初めに、GoogleはAndroid 9 Pieをリリースしました。Android 9 Pieは、Androidの最新リリースで、スマートフォンの使用を簡単にするために機械学習を使用しています。 Android 9の機能の1つに、特定の種類のテキストが検出されたときにクリック可能なリンクを追加する新しいAPIであるSmart Linkifyがあります。これは、たとえば、メッセージングアプリの友だちから住所をメッセージとして送られてきて、住所をGooleMapで検索したい時に有用です。Smart Linkifyで注釈付きテキストに変換すると、はるかに簡単に検索できます!
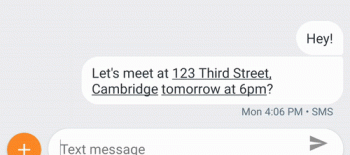
Smart Linkifyは、既存のAndroid Linkify APIの新バージョンです。素早い応答速度(Google Pixel携帯電話では20ms以下)と小さなサイズ(250kB)を備えた小さなフィードフォワードニューラルネットワーク(言語あたり500kB)によって実現されています。Smart Linkifyは、基本的にスマートテキストセレクション(Android Oreoの一部としてリリースされている)と同じ機械学習技術を使用して、リンクを作成します。
Smart Linkifyは、AndroidのオープンソースのTextClassifier APIとして利用できます(リンク作成メソッドとして)。モデルはTensorFlowを使用して訓練され、TensorFlow LiteとFlatBuffersがサポートするカスタム推論ライブラリとしてにエクスポートされます。モデルのC ++推論ライブラリは、ここではAndroid Open-Sourceフレームワークの一部として利用でき、各テキスト選択とSmart Linkify API呼び出しとして実行する事が出来ます。
概念(エンティティ)の検索
文章の中から電話番号や郵便番号を探すのは難しい問題です。人々がそれらをどのように書くか多くのバリエーションがあるだけでなく、どのタイプのエンティティが表現されているのかもしばしば曖昧です(例えば、「確認番号:857-555-3556」は電話番号ではありません)
解決策として、2つの小さなFFN(フィードフォワードニューラルネットワーク)を中心とした推論アルゴリズムを設計しました。このアルゴリズムは、住所や電話番号だけでなく、あらゆる種類のリンクすべきエンティティをグループ化するのに十分役立ちます。
最初に与えられた入力テキストは、スペースで区切られている前提で、単語に分割されます。次に、各単語をどこまで繋げて一連の文章と見なすべきかを調べるため、全ての可能な単語の並びが作成されます。今回は最長15単語まで一連の文章として見なすべきかを調査しています。
それぞれの一連の文章候補について第一のスコアリングニューラルネットは、それが有効なエンティティを表すかどうかに基づいて(0から1の間の)値を推測し、割り当てます。
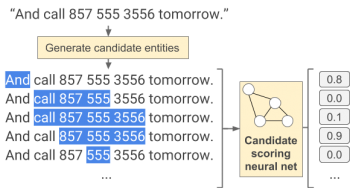
与えられた文字列に対して、第1のネットワークは、電話番号と関係ないと推測される文字列には低いスコアを割り当て、電話番号全体を表現していると思われる部分文字列には高いスコアを割り当てます。次に他よりも高くスコア付けされた文字列を優先するように重複した文字列を削除します。
こうして、電話番号、または住所、その他の何かリンク対象となるエンティティのセットが出来ました。しかし、そのエンティティが何なのかはまだ分かりません。したがって、第2のニューラルネットワークは、電話番号、住所、または場合によってはリンク対象ではない何かとして、エンティティのタイプを分類するために使用されます。
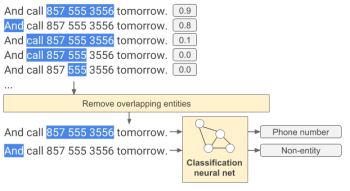
この例では、唯一の重複していないエンティティは「And Call 857 555 3556 tomorrow」の電話番号に分類された「857 555 3556」と非エンティティに分類された「And」です。
テキストの特徴
これまでは、Smart Linkifyがエンティティをテキスト文字列から検索および分類する方法について一般的な説明を行いました。ここでは、テキストがどのように処理され、ネットワークに与えられるかについて詳しく説明します
入力テキストにエンティティ候補が与えられたネットワークは、エンティティが有効であるかどうかを判断し、それを分類する事が仕事になります。
これを行うために、ネットワークはエンティティ自体のテキスト文字列に加えて、エンティティの周囲のコンテキスト(文脈)を知る必要があります。機械学習では、これらの各部分を別個の特徴として表現することによってネットワークに周囲のコンテキストを知らせる事が行われます。具体的には、入力テキストは複数の部分に分割され、ネットワークに別々に供給されます。
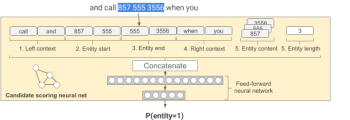
Left context:エンティティの前に存在する5単語
Entity start: エンティティの最初の3単語
Entity end: エンティティの最後の3単語(Entity startと単語が重複してもかまいません。数が足りない場合は詰められます)
Right context: エンティティの後に存在する5単語
Entity content: エンティティをbag of words形式にしたもの
Entity length: エンティティの単語の数
これらは次に連結され、ニューラルネットワークへの入力として供給されます。
特徴抽出は単語単位で行われます。文字Nグラムと大文字小文字の特徴を使用して、個々の単語をニューラルネットワークの入力として適切な実ベクトルに変換します。
・文字Nグラム。
単語を表現するために標準的な手法であるembeddingはサイズが大きくなってしまうためモバイルデバイスではほぼ実行不可能です。その代わりに、ハッシュ化したキャラクターグラムをembeddingに使用しました。このテクニックでは、単語を特定の長さの文字列の集合として表現します。今回は1から5までの長さの文字列としました。これらの文字列は、さらにハッシュ化され、固定数のバケットにマップされます。(このテクニックの詳細については、論文「Natural Language Processing with Small Feed-Forward Networks」を参照してください。)
結果として、最終モデルは、各単語/文字のサブシーケンスではなく、各ハッシュバケットのベクトルのみを格納するので、サイズを小さく維持することができます。私たちがハッシュ化キャラクターグラムに使用したembedding行列は、20,000個のバケットと12次元で構成されます。
・単語が大文字で始まるかどうかを示すバイナリ特徴。これは、郵便住所では大文字と小文字が明白な区別に繋がり、ネットワークの認識力を助けるため重要です。
トレーニングデータセット
今回の人工知能を訓練させるために使えるチャット会話を記録したデータセットは存在しないため、現実世界の一部分からデータセットを合成するアルゴリズムを考えました。
具体的には、アドレス、電話番号、名前付きエンティティ(製品名、場所名、ビジネス名など)とその他のランダムな単語をWebからSchema.orgのデータ定義(アノテーション)を使用して収集し、それを使用してニューラルネットワーク用にトレーニングデータを合成しました。
我々はエンティティをそのまま取り込み、それらの周りにランダムなテキストのコンテキストを生成しました。(Web上のランダムな単語のリストを用いて)さらに、電話番号と間違えやすいネガティブトレーニングデータとして「Confirmation number:」や「ID:」などのフレーズを追加して、これらのコンテキストで電話番号と誤認識しないようにネットワークを学習させました。
実際に動かすために
ニューラルネットワークをトレーニングし、実際のモバイル機器に展開を行うために使用しなければならなかった多くの追加のテクニックがあります。
・embedding行列を8ビットに量子化する。embedding行列の値を8ビットの整数に量子化することで、性能を損なうことなく、モデルのサイズをほぼ1/4に縮小できることがわかりました。
・最初のエンティティ部分を選択するネットワークと次のエンティティタイプを分類するネットワークとの間でembedding行列を共有する。これにより無駄がほとんどなくなり、モデルサイズが1/2倍になります。
・エンティティの前後のコンテキストのサイズを変更します。モバイルの画面では、文章の長さが不十分なため、テキストが短くなることが多く、トレーニング中にネットワークにその事を学習させる必要があります。
・エンティティ選択ネットワークのために正答例と人工的な誤答例を作成する。
たとえば、「call me 857 555-3556 today」の「857 555-3556」の分部に正答例としてラベル「電話」、「me 857 555-3556 today」にはラベル「その他」として誤答例を作成します。これにより、エンティティ範囲についてより正確に分類ネットワークが検出できるようになります。これを行わないと、ネットワークは、スパンに関係なく入力のどこかに電話番号があるかどうかだけの検出器になってしまい役には立ちません。
国際化は重要
自動的にデータを抽出することにより、言語固有のモデルの学習が容易になります。しかし、すべての言語で動作させることは、専門家による言語ニュアンスの慎重なチェックと十分な量の学習データを必要とする挑戦的な課題となります。私達は全てのラテンスクリプト言語(例:チェコ語、ポーランド語、ドイツ語、英語)は1つのモデルで上手く機能することがわかりました。 また、中国語、日本語、韓国語、タイ語、アラビア語、ロシア語のそれぞれの別のモデルが必要だと言う事もわかりました。
Smart Linkifyは現在16言語をサポートしています。モバイルモデルのサイズの制約や単語がスペースで分割できない言語を扱うトリッキーさを考えると困難ですが、もっと沢山の言語をサポートするモデルを試しています。
次のステップ
この記事で説明しているテクニックでは、電話番号と郵便住所のテキストでの迅速かつ正確な注釈付けが可能ですが、現在、標準正規表現を使用してより伝統的な手法でフライトナンバーや、日時、またはIBANの認識が実装されています。しかし、私たちは、「次の木曜日」や「3週間」のような、メッセージングのコンテキストで一般的ですが非公式な日付/時刻の仕様を認識するために、日付と時刻のMLモデルを作成することを検討しています。
小さなモデルとバイナリサイズ、および素早い応答速度は、モバイル展開にとって非常に重要です。私たちが開発したモデルとコードは、Androidフレームワークの一環として公開されています。このアーキテクチャは、他のデバイス上のテキスト注釈の問題にも拡張できると考えており、デベロッパーコミュニティから新しいユースケースが見られることを楽しみにしています。
3.AndroidのSmart Linkifyを裏で支える機械学習関連リンク
1)ai.googleblog.com
The Machine Learning Behind Android Smart Linkify
2)arxiv.org
Natural Language Processing with Small Feed-Forward Networks


コメント