
1.RRL:他のエージェントの学習記録を転移する転生強化学習(2/2)まとめ
・RRLでは教師にポリシーベースRL、生徒をバリューベースRLにする事も可能
・RRLは教師への非依存、教師からの脱却、計算・サンプルの効率化を実現
・ゼロから学習せずとも最近のアーキテクチャやアルゴリズムの進歩に転生可能
2.他のアーキテクチャへの転生
以下、ai.googleblog.comより「Beyond Tabula Rasa: Reincarnating Reinforcement Learning」の意訳です。元記事は2022年11月3日、Rishabh AgarwalさんとMax Schwarzerさんによる投稿です。
アイキャッチ画像はstable diffusionの1.5版の生成
ポリシーからバリューへ転生
RRL問題は、提供された先行計算の種類によって、様々な実体を取る事が可能です。
本発表では、広範に適用可能なRRLアプローチを開発するためのステップとして、既存の準最適なポリシー(教師)を独立したバリューベースのRLエージェント(生徒)に効率的に伝達するための「ポリシーからバリューへの転生強化学習(PVRL:Policy to Value reincarnating RL)」の設定に関するケーススタディを紹介します。
ポリシーは与えられた環境の状態(例えばアタリのゲーム画面)を直接行動に対応付けますが、バリューに基づくエージェントは与えられた状態での行動の有効性を達成可能な将来の報酬の観点から推定し、これにより過去に収集したデータから学習することが可能となります。
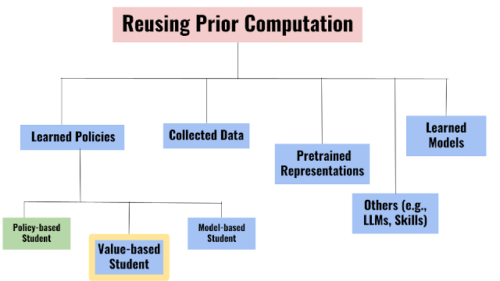
PVRLアルゴリズムが広く有用であるためには、以下の要件を満たす必要があります。
・教師への非依存性
生徒は既存の教師ポリシーのアーキテクチャや学習アルゴリズムに制約されるべきではありません。
・教師からの脱却
過去の最適でない教師に従属した転生を行うのは好ましくありません。
・計算・サンプルの効率化
転生は、ゼロから学習するよりも安価である場合にのみ有効です。
PVRLアルゴリズムの要件を踏まえ、密接に関連する目標で設計された既存のアプローチで十分であるかどうかを評価しました。そのようなアプローチは、ゼロから学習するタブラ・ラサRLと比較してわずかな改善しかもたらされないか、教師から離れると性能が低下することがわかりました。
これらの制限に対処するために、私達はエージェントが模倣アルゴリズムを介して最適でない教師から知識を抽出し、同時に環境との相互作用をRLに使用するシンプルな方法、QDaggerを紹介します。
まず、400Mフレーム(1GPUで1週間)の環境学習を行ったDQN(Deep Q-Network)エージェントを、10Mフレーム(数時間の学習)だけ学習した転生学生エージェントの教師とします。ここで、最初の6Mフレームで教師は離脱します。
ベンチマーク評価として、RLiableライブラリの四分位平均(IQM)指標を報告します。AtariゲームでのPVRL設定について以下に示すように、QDagger RRL手法は先行アプローチを凌駕していることがわかります。
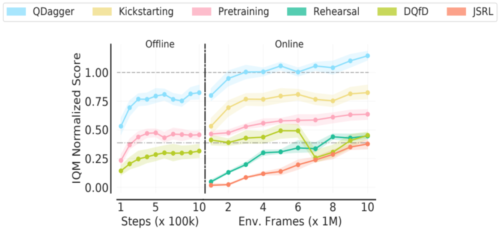
AtariでのPVRL(Policy to Value reincarnating RL)アルゴリズムのベンチマーク。教師で正規化したスコアを10本のゲームで集計。タブラ・ラサDQN(–·–)の正規化スコアは0.4でした。標準的なベースラインアプローチには、キックスタート、JSRL、リハーサル、オフラインRL事前学習、DQfDが含まれます。すべての手法の中で、QDaggerだけが10Mフレーム以内で教師性能を上回り、75%のゲームで教師性能を上回りました。
実践的な転生強化学習
さらに、ディープRLベンチマークとして広く使われているArcade Learning EnvironmentでRRLアプローチを検証します。まず、RMSPropオプティマイザを用いたNature DQNエージェントをAdamオプティマイザで微調整し、DQN(Adam)エージェントを作成します。DQN(Adam)エージェントをゼロから訓練することも可能ですが、Adamオプティマイザーを使ってNature DQNを微調整することで、40倍少ないデータと計算量でゼロから訓練したのと同等の性能を発揮することを実証しています。
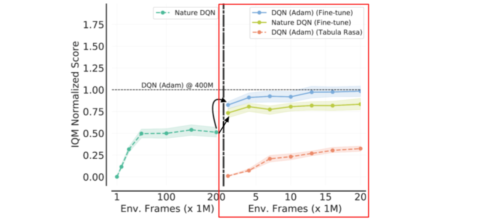
微調整で転生するDQN(Ada)
縦の区切り線は、微調整のためにネットワークの重みと再生データをロードすることに対応します。左:タブラ・ラサなNature DQNは200M環境フレームでほぼ性能が収束します。右:このNature DQNエージェントをAdamオプティマイザで学習率を下げながら20Mフレームで微調整したところ、400Mフレームでゼロから学習したDQN(Adam)とほぼ同じ結果が得られました。
DQN (Adam)エージェントを出発点とした場合、微調整は3層畳み込みアーキテクチャに限定されます。そこで、ゼロから学習することなく、最近のアーキテクチャやアルゴリズムの進歩を活用した、より汎用的な転生アプローチを検討します。具体的には、微調整したDQNエージェント(Adam)から、より高度なRLアルゴリズム(Rainbow)と優れたニューラルネットワークアーキテクチャ(Impala-CNN ResNet)を用いた別のRLエージェントをQDaggerで生まれ変わらせます。
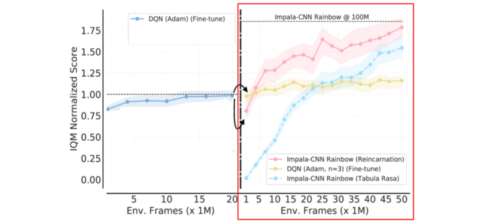
QDaggerを使った別のアーキテクチャ/アルゴリズムへの転生。縦の区切り線は、QDaggerを使ったオフライン事前学習を適用して生まれ変わらせたポイントです。
左:AdamでDQNを微調整。右:タブララサのImpala-CNN Rainbowエージェント(水色)と、微調整したDQN(Adam)からQDagger RRLを用いて学習したImpala-CNN Rainbowエージェント(ピンク)の比較。生まれ変わったImpala-CNN Rainbowエージェントは、ゼロから学習させたエージェントを常に凌駕しています。なお、DQN(Adam)をさらに細かく調整すると、効果が逓減します(黄色)
これらの結果は、エージェントをゼロから再トレーニングするのではなく、RRLアプローチを取り入れてエージェントを設計することで、過去の研究を加速させることができたことを示しています。この論文では、TPUで1ヶ月以上訓練した分散RLエージェントを再利用することで、成層圏気球の航行問題をわずか数時間のTPU計算で進展させることができることを実証しています。
討論
転生アプローチを公平に比較するには、全く同じ計算作業記録とワークフローを使用する必要があります。
また、RRLの研究成果として広く応用できる事は、既存の計算機による計算を利用するアルゴリズムの有効性についてです。例えば、私達はAtariで開発したQDaggerをBalloon Learning Environmentの転生に適用し、成功させました。このように、強化学習転生の研究は2つの方向に分岐することができると推測しています。
・標準化されたベンチマークとオープンソースの計算機
NLPや視覚領域では、少数の事前学習済みモデルが広く使われていますが、RRLの研究も、あるベンチマークにおいて、少数のオープンソースの計算結果(例えば、事前学習済みのポリシー)に収束する可能性があります。
・実世界領域
より高い性能を得ることが実世界に影響を与える領域もあるため、コミュニティが最先端のエージェントを再利用し、その性能を向上させようとする動機付けとなります。
RRLにおける科学的照合、一般化、再現性についてのより広い議論については、私達の論文を参照してください。全体として、私達はこの研究が、他の研究者が直接構築できるような計算作業記録(例えば、モデルのチェックポイント)を公開する動機となることを期待しています。
この観点から、私達は私達のコードと最終的な再生バッファを持つエージェントのトレーニングをオープンソースとして公開しました。私達は、転生強化学習は、常にゼロから学習させる手法とは対照的に、過去の計算作業記録を基にすることで研究の進展を大幅に加速できると考えています。
謝辞
本研究は、Pablo Samuel Castro, Aaron Courville 及び Marc Bellemareとの共同作業で行われたものです。この記事で使用したアニメーション図を提供してくれたTom Smallに感謝します。また、匿名のNeurIPS査読者、Google Researchチーム、DeepMind、Milaのメンバー数名によるフィードバックに感謝します。
3.RRL:他のエージェントの学習記録を転移する転生強化学習(2/2)関連リンク
1)ai.googleblog.com
Beyond Tabula Rasa: Reincarnating Reinforcement Learning
2)arxiv.org
Reincarnating Reinforcement Learning: Reusing Prior Computation to Accelerate Progress
3)github.com
google-research / reincarnating_rl

