
1.深層強化学習研究の計算コストの削減(1/2)まとめ
・Rainbowは深層強化学習飛躍のきっかけとなったDQNに更に様々な改良を加えたアルゴリズム
・強化学習で論文掲載レベルの検証を行うためにはGCP換算で500万円の高いコストが必要
・少ない計算予算で行われた研究でどのようにすれば科学的洞察を見出す事ができるか調査
2.Rainbowを評価するために必要な計算コスト
以下、ai.googleblog.comより「Reducing the Computational Cost of Deep Reinforcement Learning Research」の意訳です。元記事は2021年7月13日、Samuel Castroさんによる投稿です。
最近、精度の追求より計算コストの削減を追求する流れが来ていて良い感じだな、と思います。
アイキャッチ画像のクレジットはPhoto by David Brooke Martin on Unsplash
従来の強化学習と深層ニューラルネットワークを組み合わせた深層強化学習研究(deep reinforcement learning research)の巨大な成長は、独創的なDQNアルゴリズムの公開から始まったことは広く認められています。
このDQNの論文では、強化学習と深層学習(ディープラーニング)の組み合わせの可能性を示し、多くのAtari2600ゲームを非常に効果的にプレイできるエージェントを作成できることを示しました。それ以来、DQNに基づいて改善されたいくつかのアプローチが発表されました。
人気のあるRainbowアルゴリズムは、これらの最近の進歩の多くを組み合わせて、ALEベンチマークで最先端のパフォーマンスを実現しました。ただし、この進歩には非常に高い計算コストがかかり、計算リソースに十分にアクセスできる持つものと持たざるものと間のギャップを広げるという不幸な副作用があります。
ICML 2021で発表される「Revisiting Rainbow: Promoting more Insightful and Inclusive Deep Reinforcement Learning Research」では、小規模及び中規模の一連のタスクでこのアルゴリズムを再検討します。
まず、Rainbowアルゴリズムに関連する計算コストについて説明します。
さまざまなアルゴリズムを部品として組み込む利点について、どのようにすれば同等の結果に小規模な実験で到達することができるかを探ります。
そして、そのアイデアをさらに一般化し、より少ない計算予算で行われた研究でどのようにすれば貴重な科学的洞察を提供できるかを探ります。
Rainbowの計算コスト
Rainbowの計算コストが多くなる主な理由は、強化学習エージェントにプレイさせるゲームの本数が多くなるためです。
学術出版の世界的な標準では、Atari 2600から選択した57本のゲームで構成されるALEなどの大規模なベンチマークで新しいアルゴリズムを評価する必要が出て来る場合が多いです。
一般的なゲームの場合、Tesla P100 GPUを使用してモデルをトレーニングするのに約5日かかります。更に、意味のある信頼限界を確立したい場合は、少なくとも5回の独立した実行を実行するのが一般的です。
したがって、57のゲームの完全なスイートでRainbowをトレーニングするには、説得力のある経験的なパフォーマンス統計を提供するために、約34,200GPU時間(または5日×5回×57本=1425日)が必要でした。
言い換えれば、そのような実験は、複数のGPUで並行してトレーニングできる場合にのみ実行可能であり、小規模な研究グループにとっては法外なコストになる可能性があります。
Rainbowの再考
元のRainbow論文と同様に、元のDQNアルゴリズムに以下の部品を追加した場合の効果を評価します
・ダブルQ学習(double Q-learning)
・優先順位付き経験再生(prioritized experience replay)
・決闘ネットワーク(dueling networks)
・マルチステップ学習(multi-step learning)
・分散RL(distributional RL)
・ノイジーネット(noisy nets)
(ALEゲームの5日間と比較すれば)10~20分で完全にトレーニングできる4つの古典的な制御環境のセットで評価します。
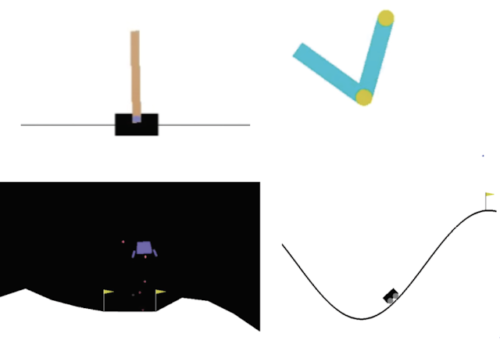
左上:CartPoleタスクは、エージェントが左右に移動できるカートのポールのバランスを取ることです。
右上:Acrobotには、2本の腕と2本の関節があり、エージェントは2本の腕の間の関節に力を加えて、下の腕をしきい値より上に上げます。
左下:LunarLanderでは、エージェントは2つの旗の間に宇宙船を着陸させることを目的としています。
右下:MountainCarでは、エージェントは2つの丘の間に勢いをつけて、右端の丘の頂上まで運転する必要があります。
各コンポーネントをDQNに個別に追加することと、完全なRainbowアルゴリズムからそれぞれを削除することの両方の効果を調査しました。元のRainbowの論文と同様に、全体として、これらの各アルゴリズムを追加すると、ベースとなるDQNの学習が向上することがわかります。
ただし、分散RL(一般にそれ単体でプラス要素になると考えられている)が必ずしもそれ自体で改善をもたらすとは限らないという事実など、いくつかの重要な違いも見つかりました。
3.深層強化学習研究の計算コストの削減(1/2)関連リンク
1)ai.googleblog.com
Reducing the Computational Cost of Deep Reinforcement Learning Research
2)arxiv.org
Rainbow: Combining Improvements in Deep Reinforcement Learning
Revisiting Rainbow: Promoting more Insightful and Inclusive Deep Reinforcement Learning Research
3)github.com
kenjyoung / MinAtar


「GCP上で大きなモデルを動かした際のGPUの性能比較」から持ってきた数字で試算すると「NVIDIA Tesla P100 GPU + n1-highmem-4 + 100G」を使って継続利用割引が適用される前提で試算すると1ゲーム辺りにかかる金額は
$1.2/h × 24時間 × 5日 × 5回 × 120円 = \86,400円
57ゲームだと
\86,400円 × 57本 = \4,924,800円
500万円!ここまでやって予想通りの結果が出なかった時の気持ちを想像すると胃が痛くなるような、喉元に何かがこみあげてくるような気持になりますね。