
1.RLiable: 強化学習における信頼性の高い性能評価指標(1/2)まとめ
・平均値や中央値などを評価指標にしたままでは強化学習の性能を見誤る可能性がある
・より多く試行して性能評価する事は限られた計算機資源の観点から現実的ではない
・実行回数が少なくとも信頼性を高めるための手法を新たにオープンソースで発表した
2.RLiableとは?
以下、ai.googleblog.comより「RLiable: Towards Reliable Evaluation & Reporting in Reinforcement Learning」の意訳です。元記事は2021年11月17日、Rishabh AgarwalさんとPablo Samuel Castroさんによる投稿です。
少数回しか試行していない実験結果の平均値や中央値で強化学習の性能を測るのはちょっとオカシイですよねって最もなお話なのですが、未読なら以下のお話も読んでおくとちょっと視野が広がるかもしれません。
深層強化学習研究の計算コストの削減(1/2)
アイキャッチ画像のクレジットはPhoto by Erik Mclean on Unsplash
強化学習(RL:Reinforcement Learning)は、機械学習の一分野であり、経験から学習して意思決定が必要なタスクを解決することに焦点を当てています。RLの分野は大きな進歩を遂げており、ビデオゲームのプレイ、成層圏の気球の飛行、ハードウェアチップの設計などの複雑なタスクで素晴らしい実証結果が得られています。しかし、現在の経験的評価を指標にしたままでは、科学技術の進歩が速いという誤った感覚を与える一方で、科学技術の進歩を遅らせる可能性があることが次第に明らかになってきています。
そこで、NeurIPS 2021で口頭発表として採択された「Deep RL at the Edge of the Statistical Precipice」では、結果の統計的不確実性をどのように考慮する必要があるかを議論しています。
深層強化学習の評価が信頼できるものであるためには、統計的不確実性を考慮する必要があります。私達は特に試行を少数回しか実施しない場合について議論します。
具体的には、点推定(point estimation:平均や分散など。母集団のパラメーターを一つの値で推定する事)で結果を報告するという一般的な方法では、この不確実性が無視され、結果の再現性が妨げられます。
例えば、一般的に報告されているタスク毎のスコア表は、タスクの数が増えるとわかりにくくなってしまい、標準偏差が省略されることが多いです。更に、平均値のような単純なパフォーマンス指標は、少数の外れ値となったタスクから強い影響を受ける可能性があります。一方、中央値は、スコアの半分が0点であっても影響を受けません。
このように、わずかな実行回数で報告された結果に対する信頼性を高めるために、私たちは、層別ブートストラップ信頼区間(stratified bootstrap confidence intervals)、パフォーマンスプロファイル(performance profiles)、および四分位平均(interquartile mean)や改善確率(probability of improvement)などのより良い指標を含む、さまざまな統計ツールを提案します。
また、研究者がこれらのツールを取り入れることができるように、使いやすいPythonライブラリ「RLiable」を簡単に開始できるようにColabで公開しています。
強化学習の評価における統計的不確実性
RLの実証研究では、Atari 2600ビデオゲームのような多様なタスクのパフォーマンスを評価することで進歩を評価しています。一般的に、RLベンチマークの結果は、タスク間で集計された平均値と中央値の点推定値を比較しています。これらのスコアは、異なるタスク間でスコアを比較できるように、ある定義されたベースラインおよび最適なパフォーマンス(例えば、Atariゲームにおけるランダムなエージェントおよび「平均的な」人間のパフォーマンス)と比較されるのが一般的です。
ほとんどのRL実験では、トレーニング実施時に得られるスコアにはランダム性があるため、点推定値だけを報告しても、新たに独立して実行した場合に同様の結果が得られるかどうかはわかりません。トレーニング実施の回数が少ないことと、ディープRLアルゴリズムの性能のばらつきが大きいことが相まって、点推定値の統計的不確実性が大きくなることが多いです。
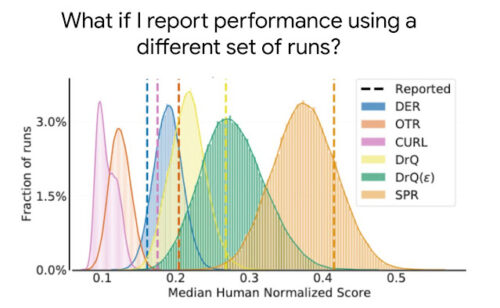
最近発表された5つのアルゴリズム,DER,OTR,CURL,2種類のDrQ,SPRについて,26種類のゲームを含むAtari 100kベンチマークにおける人間のスコアで正規化された中央値の分布。
破線で示したように、論文で報告されている数回の実行に基づく中央値の点推定値は、中央値のばらつきに関する情報を提供しておらず、通常、期待される中央値を過大評価(CURL、SPR、DrQなど)または過小評価(DERなど)しており、誤った結論につながる可能性があります。
ベンチマークがますます複雑になるにつれて、そのようなタスクを解決するために必要な計算とデータが増えるため、数回以上の実行を評価することがますます要求されるようになります。
たとえば、2億フレームの50 Atariゲームでの5回の実行には、1000GPU日以上かかります。したがって、より多くの回数を実行して評価することは、計算量の多いベンチマークの統計的不確かさを減らすための実行可能なソリューションではありません。
以前の研究では、解決策として統計的有意性検定の使用が推奨されていましたが、そのような検定は本質的に二分されているため(「有意」または「有意ではない」)、意味のある洞察を得るのに必要な粒度が不足していることが多く、広く誤解されています。
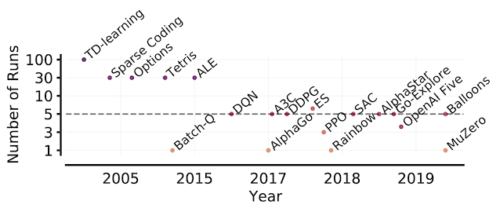
強化学習論文内の試行回数の推移。アーケードゲームの学習環境(ALE:Arcade Learning Environment)から始まり、計算量の多いベンチマークへの移行により、タスクごとにほんの一握りの実行のみを評価する慣行が生まれ、点推定の統計的不確かさが増しています。
3.RLiable: 強化学習における信頼性の高い性能評価指標(1/2)関連リンク
1)ai.googleblog.com
RLiable: Towards Reliable Evaluation & Reporting in Reinforcement Learning
2)agarwl.github.io
Deep RL at the Edge of the Statistical Precipice
3)github.com
google-research / rliable
4)colab.research.google.com
deep_rl_precipice_colab.ipynb

