
1.RRL:他のエージェントの学習記録を転移する転生強化学習(1/2)まとめ
・強化学習の主流は既存知識を用いずにゼロから効率的に学習するタブラ・ラサ
・タブラ・ラサはアルゴリズムやアーキテクチャ変更時にゼロからやり直しが必要
・RRLは既存の学習済みエージェントを継続的に改善・更新する新しいパラダイム
2.Reincarnating RLとは?
以下、ai.googleblog.comより「Beyond Tabula Rasa: Reincarnating Reinforcement Learning」の意訳です。元記事は2022年11月3日、Rishabh AgarwalさんとMax Schwarzerさんによる投稿です。
アイキャッチ画像はstable diffusionの1.5版の生成で、白紙から連想した弁慶の勧進帳ですが、それっぽい画像と言えばそれっぽいですが、色々混ざってしまっている感がありますね。
強化学習(RL:Reinforcement Learning)は、ビデオゲームのプレイ、成層圏気球の飛行、ハードウェアチップの設計などの意思決定タスクを解決するために学習できるように、関連する経験を使用して知的エージェントを訓練することに焦点を当てた機械学習の分野です。
RLの汎用性から、RL研究の主流は、タブラ・ラサ(tabula rasa:ラテン語で白紙状態の意。つまり、問題に対する既存知識を用いずにゼロから学習すること)を効率的に行えるエージェントを開発することです。
しかし、実際には、大規模なRL問題を解決可能なタブラ・ラサなRLシステムは、標準的というよりもむしろ例外的です。Dota 2で人間レベルのパフォーマンスを達成したOpenAI Fiveのような大規模なRLシステムでは、開発サイクルの間に何度も設計変更(アルゴリズムやアーキテクチャの変更など)が行われます。
この変更作業は数ヶ月に及ぶこともあり、ゼロから再トレーニングすることなくこのような変更を取り入れる必要がありますが、これは法外なコストがかかるでしょう。
さらに、タブラ・ラサRL研究の非効率性は、多くの研究者が計算要求の高い問題に取り組むことを排除しかねません。例えば、ALEで50以上のAtari 2600ゲームに対して2億フレームで深層RLエージェントを訓練するという典型的なベンチマーク(標準的な慣習)は、1000以上のGPU日数を必要とします。深層RLがより複雑で難しい問題に向かうにつれて、RL研究への参入のための計算障壁はさらに高くなると思われます。
タブラ・ラサRLの非効率性を解決するために、私達は論文「Reincarnating Reinforcement Learning: Reusing Prior Computation To Accelerate Progress」をNeurIPS 2022にて発表します。
この論文では、RL研究の代替アプローチを提案します。これは、RLエージェントの再設計作業時、あるいはあるエージェントから別のエージェントへの転移時に過去の計算作業記録を(学習済みモデル、ポリシー、ログデータなど)再利用する手法です。
RLのいくつかの分野では過去の計算結果を利用していますが、ほとんどのRLエージェントはまだほとんどのケースでゼロから訓練されています。これまで、RL研究において、学習ワークフローに先行計算を活用するための広範な取り組みはありませんでした。私達はまた、研究者がこの研究を基に構築できるように、私達のコードと学習済みエージェントを公開しています。
タブラ・ラサRLとRRL(Reincarnating RL)の比較
タブラ・ラサRLが同じ環境であってもゼロから学習する事に焦点を当てているのに対し、RRLは、新しいエージェントを訓練したり、既存のエージェントを改良する際に、以前の計算結果(例えば、以前に学習したエージェント)を再利用するという前提に立っています。RRLでは、新しい問題に最初に取り組む場合を除き、新しいエージェントをゼロから訓練する必要はありません。
なぜ転生強化学習(Reincarnating RL)なのか?
Reincarnating RL(RRL)は、ゼロから学習するよりも計算量とサンプル効率に優れたワークフローです。RRLは、複雑なRL問題に、より広いコミュニティが過剰な計算資源を必要とせずに取り組むことを可能にし、研究を民主化することができます。さらに、RRLは、研究者が既存の学習済みエージェントを継続的に改善・更新するベンチマークパラダイムを実現することができ、特に気球ナビゲーションやチップ設計など、性能向上が実世界に影響を与える問題で有効です。最後に、実世界でのRL採用例は、おそらく先行する計算作業が利用可能なシナリオ(例えば、既存の配備済みRLポリシー)になると思われます。
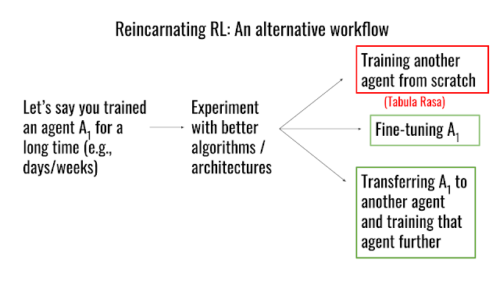
代替研究ワークフローとしてのRRL
ある研究者が、エージェントA1をしばらく訓練した後、より優れたアーキテクチャやアルゴリズムを試したいと考えているとします。タブラ・ラサのワークフローでは、別のエージェントをゼロから訓練し直す必要がありますが、RRLでは、既存のエージェントA1を別のエージェントに転移し、このエージェントをさらに訓練するか、あるいはA1を単に微調整するという、より実行可能なオプションが用意されています。
これまでも適用範囲が限られた即興な大規模転生強化学習の試みは存在しました。Dota2におけるモデルサージェリー、ルービックキューブにおけるポリシー蒸留、AlphaStarにおけるPBT、AlphaGo / Minecraftにおける行動クローンポリシーのRL微調整などです。
しかし、RRLそれ自体を研究課題として検討される事はありませんでした。このため、従来の即興な解決策とは対照的な汎用的なRRLアプローチの開発を主張します。
3.RRL:他のエージェントの学習記録を転移する転生強化学習(1/2)関連リンク
1)ai.googleblog.com
Beyond Tabula Rasa: Reincarnating Reinforcement Learning
2)arxiv.org
Reincarnating Reinforcement Learning: Reusing Prior Computation to Accelerate Progress
3)github.com
google-research / reincarnating_rl

