
1.弱いヒントを使って多腕バンディット問題を改善(2/2)まとめ
・従来のUCBアルゴリズムをアームの組に対して実行し、最高のスコアを出したペアのどちらが良いかを弱いヒントから得る
・弱いヒントの概念を利用すると、時間軸に対する後悔の依存性を指数関数的に改善、または完全に取り除く事ができる
・本件はバンディッツ問題以外にもオンライン線形・凸最適化などのより複雑な設定にも適用可能で応用範囲が広い
2.多腕バンディット問題の難しさ
以下、ai.googleblog.comより「Learning with queried hints」の意訳です。元記事は2023年1月25日、Sreenivas GollapudiさんとKostas Kolliasさんによる投稿です。
アイキャッチ画像はstable diffusionを自分でカスタムマイズしたモデルによる生成
アルゴリズムの考え方
バンディット設定に対する私達のアルゴリズムは、よく知られた上方信頼境界(UCB:Upper Confidence Bound)アルゴリズムを利用します。
UCBアルゴリズムは、各アームのスコアとして、そのアームでこれまでに観察された平均報酬を維持し、それにアームが引かれた回数によって小さくなる楽観的パラメータを追加します。これにより、探索と活用の間のバランスを取ります。
私達のアルゴリズムは、主に2つのアームのうちより良いものを指定することができるペアワイズ比較モデルを利用するために、アームのペアにUCBスコアを適用します。
各アームiとjのペアは、各回の報酬が2つのアーム間の最大報酬に等しいメタアーム(i、j)としてグループ化されます。私達のアルゴリズムは、メタアームのUCBスコアを観察し、最も高いスコアを持つペア(i、j)を選択します。このペアはMLの補助的なペアワイズ予測モデルに問い合わせとして渡され、2つのアームのうち最も良いものを回答します。この応答が、最終的にアルゴリズムで使用されるアームとなります。
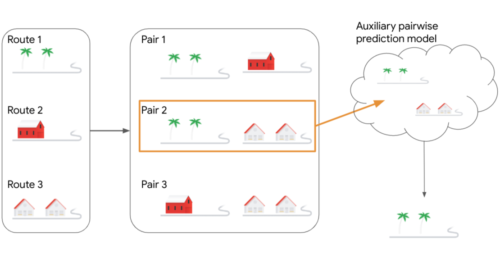
3つの候補経路を考慮する決定問題の例
私達のアルゴリズムでは、代わりに候補経路のすべてのペアを考慮します。ペア2が現在の回で最も高いスコアを持つペアであるとします。このペアは補助的なMLペアワイズ予測モデルに渡され、2つのルートのうちどちらが優れているかを出力します。
専門家問題設定における私達のアルゴリズムは、FtRL(Follow-the-Regularized-Leader)アプローチを採用しています。これは、各専門家の総報酬を維持し、ランダムなノイズをそれぞれに加え、現在の回でのベストを選択するものです。このアルゴリズムはこのプロセスを2回繰り返し、ランダムなノイズを2回引き、2回の反復のそれぞれで最も報酬の高い専門家を選択します。選択された2人の専門家は、補助的なMLモデルへの問い合わせに使用されます。2人の専門家間のどちらがベストかに対するモデルの応答が、アルゴリズムによって選択されるものです。
結果
私達のアルゴリズムは、弱いヒント(weak hints)の概念を利用し、時間軸に対する後悔の依存性を指数関数的に改善、あるいはこの依存性を完全に取り除くなど、理論的保証の面で強力な改善を達成することができます。
本アルゴリズムが従来手法による解法をどのように上回ることができるかを説明するために、n個のアーム候補のうち1個が残りのn-1個のアームより常に僅かに優れているという設定を提示します。
私達は、標準的なUCBアルゴリズムを使用して、ペアワイズ比較モデルに提出する2つのアームを選択するベースラインと、私達のML探索アルゴリズムを比較します。UCBを使用する比較対象手法は後悔を蓄積し続けますが、探索アルゴリズムは後悔を蓄積することなく、迅速に最良の腕を特定し、それを選択し続けることが観察されました。
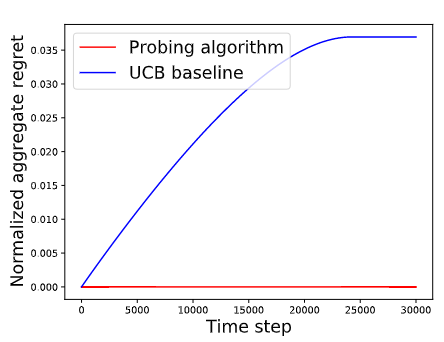
私達のアルゴリズムがUCBベースの比較対象手法より優れている例
この例では、n個のアームが検討され、そのうちの1個は残りのn-1個よりも常に僅かに優れています。
結論
本研究では、単純なペアワイズ比較(pairwise comparison)のMLモデルが、専門家問題やバンディッツ問題などの設定において、いかに強力なヒントを与えることができるかを探りました。この論文ではさらに、これらのアイデアがオンライン線形・凸最適化などのより複雑な設定にどのように適用されるかを紹介します。私達は、この手本が、MLや組合せ最適化問題において、より興味深い応用が可能であると信じています。
謝辞
共著者のAditya Bhaskara(ユタ大学)、Sungjin Im(カリフォルニア・マーセッド大学)、Kamesh Munagala (デューク大学)に感謝の意を表します。
3.弱いヒントを使って多腕バンディット問題を改善(2/2)関連リンク
1)ai.googleblog.com
Learning with queried hints
2)arxiv.org
Online Learning and Bandits with Queried Hints

