1.DELG:インスタンスレベルの画像認識の進歩(1/2)まとめ
・インスタンスレベルの画像認識(ILR)とは特定の実体(インスタンス)を認識するタスク
・GoogleはGoogleランドマークデータセットなどでILRの進歩に貢献してきた
・ILRにはグローバル(大域的)な特徴表現とローカル(局所的)な特徴表現の2種が必要
2.インスタンスレベルの画像認識とは?
以下、ai.googleblog.comより「Advancing Instance-Level Recognition Research」の意訳です。元記事の投稿は2020年9月25日、 Cam AskewさんとAndré Araujoさんによる投稿です。
アイキャッチ画像はランドマークの例として箱根神社の鳥居でクレジットはPhoto by Eutah Mizushima on Unsplash
「インスタンスレベルの画像認識(ILR:Instance-Level Recognition)」とは、物体が属するカテゴリだけでなく、物体の特定の実体(インスタンス)までを認識するコンピュータビジョンタスクです。
例えば、画像に「ポスト印象派の絵画」というラベルを付けるのではなく「ヴィンセント・ヴァン・ゴッホのローヌ川の星月夜」、もしくは「アーチ型の門」の代わりにく「凱旋門、パリ、フランス」などの固有の実体がわかるレベルのラベルを付与する事に私達は関心を持っています。
インスタンスレベルの認識の問題は、ランドマーク(その土地を特徴づけるような印象的な建造物や地形)、美術品、製品、ロゴなどの多くの領域に存在し、ビジュアル検索アプリ、個人的な写真の整理、ショッピングなどの支援に利用可能です。
過去数年間、GoogleはGoogleランドマークデータセットとGoogleランドマークデータセットv2(GLDv2:Google Landmarks Dataset v2)、およびDELFやDetect-to-Retrieveなどの新しいモデルを使用してILRの研究に貢献してきました。

美術品、ランドマーク、および製品に対する、画像認識タスクの違い
基本(basic)、きめ細かい(fine-grained)、インスタンスレベル(instance-level)、でラベルの粒度が異なります。私達の研究では、インスタンスレベルの認識に焦点を当てています。
本日の投稿では、ECCV’20でのインスタンスレベル認識ワークショップの結果をいくつか取り上げます。
このワークショップには、この分野の専門家や愛好家が集まり、多くの有益な議論が行われました。その中には、例えば私達がECCV’20で発表した論文「DEepLocal and Global features(DELG)」で紹介した最先端の画像機能モデルDELGや、DELGおよびその他の関連するILR技術をサポートするオープンソースのコードが含まれていました。
また、GLDv2に基づく2つの新しい画期的な課題(認識と検索に関するタスク)と、ランドマークを超えて他の領域にILRを拡張する将来の課題(美術品認識と製品検索)も提示されました。
ワークショップと課題の長期的な目標は、ILRの分野での進歩を促進し、これまで主に個別の問題として取り組んできた様々な領域の研究の流れを統合することにより、最先端技術を推進することです。
DELG:DEep Local and Global Features
効果的な画像特長表現は、インスタンスレベルの認識問題を解決するために必要な重要なコンポーネントです。
多くの場合、グローバル(大域的な)とローカル(局所的な)の2種類の特徴表現が必要です。
グローバルな特徴は、画像のコンテンツ全体を要約し、コンパクトな特徴表現に導きますが、視覚要素の(撮影時の向きなど)空間配置に関する情報を破棄します。この破棄される情報には実体が持つ固有の特徴が含まれている可能性があります。
一方、ローカルな特徴は、特定の画像領域に関する記述子と位置情報(geometry information)で構成されます。それらは、同じ物体を異なる側面から描いた画像同士を照合する際に特に役立ちます。
現在、これらのタイプの特徴の両方に依存するほとんどのシステムは、異なるモデルを使用してそれぞれを個別に画像処理させる必要があります。これにより、計算が冗長になり、全体的な効率が低下します。これに対処するために、ローカルおよびグローバルな画像特長表現の統合モデルであるDELGを提案しました。
DELGモデルは、2つの異なるヘッドを持つ完全畳み込みニューラルネットワークを活用します。1つはグローバル特徴用で、もう1つはローカル特徴用です。
グローバルな特徴表現は、深いネットワーク層のプールされた特徴マップを使用して取得されます。これは、入力画像の顕著な特徴を事実上要約し、入力の微妙な変化に対してモデルをより堅牢にします。
ローカルな特徴表現を抽出する処理は、中間特徴マップを活用して、特徴的な画像領域を検出します。その後、Attentionモジュールの助けを借りて、局所的なコンテンツを識別するための記述子を生成します。
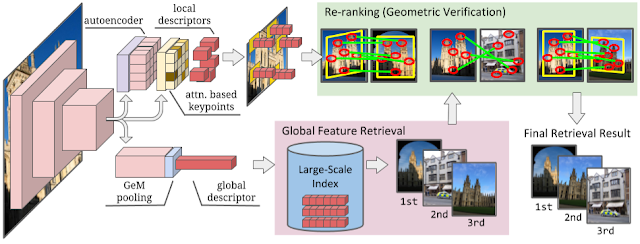
提案されたDELGモデル(左)。グローバルな特徴は、検索タスク用のシステムの最初の段階で使用され、最も類似した画像を効率的に選択します。(下段)次に、ローカルな特徴を使用して上位の結果を再ランク付けし(上段の右側)、システムの精度を高めることができます。
この斬新な設計により、単一のモデル内でグローバルおよびローカルの特徴を抽出できるため、効率的な推論が可能になります。
このような統合モデルを直接トレーニングし、インスタンスレベルの認識タスクに対して最先端のスコアを提供できることを初めて実証しました。
以前のグローバル特徴と比較した場合、このDELGは他の手法よりもmAPが最大7.5%優れています。また、ローカル特徴を使った再ランク付け段階では、DELGベースの結果は以前の手法よりも最大7%向上します。
全体として、DELGはGLDv2の認識タスクで61.2%の平均精度を達成しました。これは、2019年のチャレンジに参加した2つの手法を除いて全てを上回ります。そのチャレンジの上位の手法は全て複雑なモデルを複数実行して出力結果の平均を使うアンサンブル手法を採用していましたが、DELGは単一モデルでこれを達成している事に着目してください。
3.DELG:インスタンスレベルの画像認識の進歩(1/2)関連リンク
1)ai.googleblog.com
Advancing Instance-Level Recognition Research
2)github.com
models/research/delf
3)arxiv.org
Unifying Deep Local and Global Features for Image Search
4)www.kaggle.com
Google Landmark Retrieval 2020
5)storage.googleapis.com
Google Landmarks Dataset V2
6)www.metmuseum.org
Open Access at The Met
7)ilr-workshop.github.io
Instance-Level Recognition Workshop at ECCV’20
