
1.Google-Landmarks-v2:ランドマークの認識と検索のためのデータセット(1/2)まとめ
・Googleがランドマーク検索用のデータセットであるGoogle-Landmarksの改良版であるv2を公開
・20万種類を超えるランドマーク(7倍に増加)を含む500万枚を超える画像(最初のリリースの2倍)が含まれる
・同時にKaggleでLandmark Recognition 2019とLandmark Retrieval 2019が賞金$25,000で開催中
2.Google-Landmarks-v2とは?
以下、ai.googleblog.comより「Announcing Google-Landmarks-v2: An Improved Dataset for Landmark Recognition & Retrieval」の意訳です。元記事は2019年5月3日、Bingyi CaoさんとTobias Weyandさんによる投稿です。
昨年、私達はその時点で入手可能な世界最大のランドマーク認識データセットであるGoogle-Landmarksをリリースしました。インスタンスレベルの認識(インスタンスレベルの認識とは、例えば、「滝」ではなく「ナイアガラの滝」を判別する事です)や、画像情報による検索(image retrieval:入力として画像を与え、その画像内の特定物体を他の画像から探す検索)に関する研究の進歩を促進するために、2つのKaggleチャレンジ、Landmark Recognition 2018とLandmark Retrieval 2018も開催し、500以上の研究者チームと機械学習(ML)愛好家が参加してくれました。
ただし、インスタンス認識と画像情報検索の両方で、より優れたより堅牢なシステムをトレーニングするために、画像数と様々なランドマークの両方において、さらに大きなデータセットが必要になります。この目標を支援するため、今年、Google-Landmarks-v2をリリースします。20万種類を超えるランドマーク(7倍に増加)を含む500万枚を超える画像(最初のリリースの2倍)を含む、まったく新しい、さらに大きなランドマーク認識データセットです。
規模の違いにより、このデータセットは更に多様性を増し、最先端のインスタンス認識アプローチに対してさらに大きな課題を生み出しています。
この新しいデータセットに基づいて、2つの新しいKaggleチャレンジ – Landmark Recognition 2019とLandmark Retrieval 2019 – を発表しました。また、特定のオブジェクトインスタンスの検索に適した新しい画像特徴表現であるDetect-to-Retrieveのソースコードとモデルも公開します。
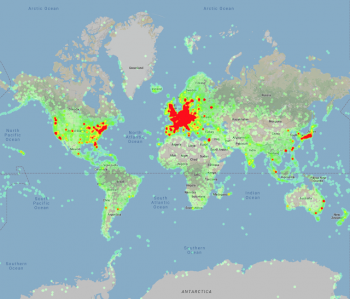
Google-Landmarks-v2のランドマーク位置を示すヒートマップ。データセットの規模が拡大し、対象範囲が昨年のデータセットに比べて大きく広がっている事がわかります。
3.Google-Landmarks-v2:ランドマークの認識と検索のためのデータセット(1/2)関連リンク
1)ai.googleblog.com
Announcing Google-Landmarks-v2: An Improved Dataset for Landmark Recognition & Retrieval
2)github.com
cvdfoundation/google-landmark
3)www.kaggle.com
Google Landmark Retrieval 2019
Google Landmark Recognition 2019
Google-Landmarks Dataset
4)arxiv.org
Detect-to-Retrieve: Efficient Regional Aggregation for Image Search

コメント