
1.LaBSE:言語に依存しないBERT仕様のEmbedding(2/2)まとめ
・Tatoebaに登録されている言語を使った検証では主要14言語では他の手法と大きな差はなかった
・全112言語を含めてテストを行った場合、従来手法に20%近い精度差をつけてLaBSEが勝った
・トレーニングデータがないでもLaBSEは75%以上の精度を達成できる場合があった
2.LaBSEとは?
以下、ai.googleblog.comより「Language-Agnostic BERT Sentence Embedding」の意訳です。元記事の投稿は2020年8月18日、Yinfei YangさんとFangxiaoyu Fengさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Jen Vazquez Photography on Unsplash
LaBSEでは、言語モデルに関する最近の進歩、すなわちMLMやTLMを含むBERTのような事前トレーニングを活用し、これに続いて翻訳ランキングタスクを使った微調整を行いました。
モデルとボキャブラリの対応可能範囲を増やすため、12層のトランスフォーマーが使用されます。これは、MLMとTLMを使用して109言語で事前トレーニングされ、50万ボキャブラリを備えています。
結果として得られるLaBSEモデルは、1つのモデルで109言語に対する拡張サポートを提供します。
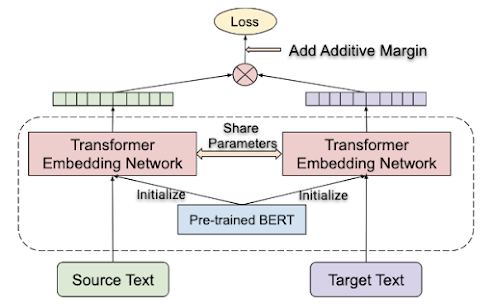
デュアルエンコーダーアーキテクチャ
翻譯元言語と翻訳先言語の文章は、共有のtransformer embeddingネットワークを使用して個別にエンコードされます。翻訳のランクキングタスクが適用され、言い換えテキスト同士が類似した特徴表現になるように強制されます。transformer embeddingネットワークは、MLMおよびTLMタスクでトレーニングされたBERTのチェックポイントから初期化されます。
クロスリンガルテキスト検索のパフォーマンス
Tatoebaプロジェクトに登録されている言語資料を使用して、今回のモデルを評価します。Tatoebaは、112の言語で構成されるデータセットで、言語と英文に対応する文のペアが最大1,000ペア登録されています。
モデルはデータセット内の30を超える言語で、トレーニングデータを持ちません。指定された文に最も近い最近傍翻訳をコサイン距離を使用して計算して見つけることをタスクとして課せられます。
トレーニングデータ分布のヘッドまたはテイルに位置する言語に対するモデルのパフォーマンスを理解するために、言語のセットをいくつかのグループに分割し、各セットの平均精度を計算しました。
最初の14言語グループは、m~USE(multilingual Universal Sentence Encoder)がサポートする言語から選択されました。これは、分布のヘッドに位置する言語(主要言語)をカバーしています。次に、XTREMEベンチマーク用の36言語で構成される第2言語グループを評価しました。LASERトレーニングデータでカバーされる言語から選択された3番目の82言語グループには、分布のテイルに位置する多くの言語が含まれています(テイル言語)。最後に、すべての言語の平均精度を計算します。
以下の表は、各言語グループについて、m~USEおよびLASERモデルと比較した、LaBSEによって達成された平均精度を示しています。予想通り、すべてのモデルは、ほとんどの主要言語をカバーする14言語グループで強力に機能します。より多くの言語を含めると、LASERとLaBSEの両方の平均精度は低下します。ただし、言語数の増加に伴うLaBSEモデルからの精度の低下はそれほど顕著ではなく、特に112言語が完全に含まれている場合(83.7%の精度対65.5%)、LASERを大幅に上回っています。
| Model | 14 Langs | 36 Langs | 82 Langs | All Langs |
| m~USE* | 93.9 | — | — | — |
| LASER | 95.3 | 84.4 | 75.9 | 65.5 |
| LaBSE | 95.3 | 95 | 87.3 | 83.7 |
Tatoebaデータセットの平均精度(%)
「14 Langs」グループは、m~USEがサポートする言語で構成されています。
「36 Langs」グループには、XTREMEが選択した言語が含まれます。
「82 Langs」グループは、LASERモデルでカバーされる言語を表します。
「All Langs」グループには、Tatoebaがサポートする全ての言語が含まれています。
※m~USEモデルには2つの種類があり、1つは畳み込みニューラルネットワークアーキテクチャ上に構築され、もう1つはtransformerのようなアーキテクチャ上に構築されます。 ここでは、Transformerバージョンとのみ比較しています。
トレーニングデータが存在しない言語をサポートする
Tatoebaプロジェクトに含まれる全言語の平均パフォーマンスは非常に有望です。
興味深いことに、LaBSEは、Tatoebaプロジェクトに含まれるがトレーニングデータが存在しない30以上の言語の多くに対して比較的優れたパフォーマンスを発揮します。(下図を参照)。これらの言語の3分の1で、LaBSEは75%以上の精度を達成し、精度が25%未満になるのは8言語のみです。
トレーニングデータのない言語であっても非常に強力な転移パフォーマンスを示しています。このような否定しがたい言語転送能力は、LaBSEが超多言語対応の性質を持つからこそ、達成可能です。
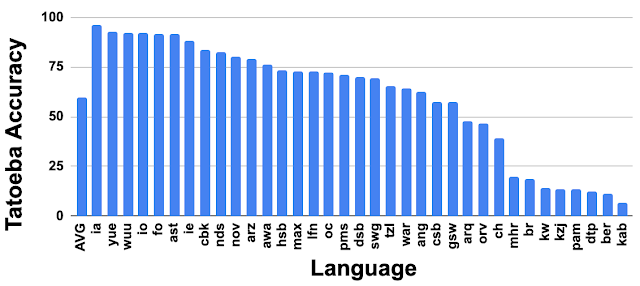
Tatoebaプロジェクトに含まれるトレーニングデータがない言語(ISOコードの639-1/639-2)に対するLaBSEの精度
インターネットから並列テキストを掘り出す
LaBSEは、インターネット上の文書データからパラレルテキスト(bi-text)を掘り出すために使用できます。例えば、私達は、大規模な単一言語資料であるCommonCrawlにLaBSEを適用して、5億6000万の中国語と3億3千万のドイツ語の文を処理して、並列テキストを抽出しました。中国語とドイツ語の各文のペアはLaBSEモデルを使用してエンコードされます。次に、エンコードされたembeddingを使用して、モデルによって前処理およびエンコードされた77億の英語の文章群から翻訳候補を見つけます。
近似最近傍探索を使用して、文章の高次元embedding をすばやく検索します。単純なフィルタリングの後、モデルは英語-中国語および英語-ドイツ語のそれぞれに対して2億6100万および1億400万の潜在的な並列テキストのペアを返します。
掘り出したデータを使用してトレーニングされたNMTモデルは、WMT変換タスク(英語から中国語の場合はwmt17、英語からドイツ語の場合はwmt14)でBLEUスコア35.7および27.2を達成しました。このパフォーマンスは、高品質の並列データでトレーニングされた現在の最先端モデルのスコアに、ほんの数ポイント足りないだけです。
まとめ
この研究とモデルをコミュニティと共有できることを嬉しく思います。事前トレーニング済みモデルはtfhubでリリースされ、これに続く更なる研究と可能になるアプリケーションをサポートします。また、ここで示しているのはほんの始まりにすぎず、全ての言語をサポートするためのより優れたモデルの構築など、取り組むべきより重要な研究上の問題があると考えています。
謝辞
コアチームには、Wei Wang, Naveen Arivazhagan, Daniel Cerが含まれます。
フィードバックと提案をいただいた他のGoogleグループのパートナーとともに、Google Research Languageチームに感謝いたします。データ処理を支援してくれたSidharth MudgalとJax Lawにも感謝します。 BERTの事前トレーニングを支援してくださったJialu Liu, Tianqi Liu, Chen Chen及び Anosh Rajにも感謝します。
3.LaBSE:言語に依存しないBERT仕様のEmbedding(2/2)関連リンク
1)ai.googleblog.com
Language-Agnostic BERT Sentence Embedding
2)arxiv.org
Language-agnostic BERT Sentence Embedding
3)research.fb.com
LASER LANGUAGE-AGNOSTIC SENTENCE REPRESENTATIONS
4)www.ijcai.org
Improving Multilingual Sentence Embedding using Bi-directional Dual Encoder with Additive Margin Softmax(PDF)
5)tfhub.dev
LaBSE
6)github.com
LASER/data/tatoeba/v1/

