
1.ViT:規模拡大可能な画像認識用のTransformers(2/2)まとめ
・画像タスク用に特化したモデルは不要であるか最適ではない可能性がある
・データのサイズが増え続けており画像タスクに関する新しいアプローチが必要
・ViTは視覚タスクや他のタスクを解決できる汎用的で規模拡大可能なアーキテクチャ
2.Vision Transformerの性能
以下、ai.googleblog.comより「Transformers for Image Recognition at Scale」の意訳です。元記事の投稿は2020年12月3日、Neil HoulsbyさんとDirk Weissenbornさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Talles Alves on Unsplash
規模拡大
最初にImageNetでViTをトレーニングし、77.9%のTop-1精度を達成しました。これは最初の試みとしてはまずまずですが、最先端技術にははるかに及びません。
現在の最高のCNNsは追加の学習データなしでImageNetのみでトレーニングされた際に85.8%を達成します。緩和戦略(正則化など)にもかかわらず、ViTは、画像に関する知識が組み込まれていないため、ImageNetタスクに過剰適合てしまいます。
データセットのサイズがモデルのパフォーマンスに与える影響を調査するために、ImageNet-21k(1400万画像、21,000種)およびJFT(3億画像、18,000種)でViTをトレーニングし、その結果を同じデータセットでトレーニングされた最先端のCNNモデル(BiT:Big Transfer)と比較しました。
上で説明したように、ViTは、ImageNet(100万画像)でトレーニングされた場合、同等のCNNs(BiT)よりも大幅にパフォーマンスが低下します。ただし、ImageNet-21k(1400万画像)ではパフォーマンスは同等であり、JFT(3億画像)ではViTはBiTよりも優れています。
最後に、モデルのトレーニングに必要な計算量の影響を調査します。このために、JFTでいくつかの異なるViTモデルとCNNsをトレーニングしました。これらのモデルは、様々なモデルサイズとトレーニング期間にまたがっており、その結果、トレーニングには様々な量の計算が必要になります。
与えられた量の計算に対して、ViTは同等のCNNsよりも優れたパフォーマンスをもたらすことがわかります。
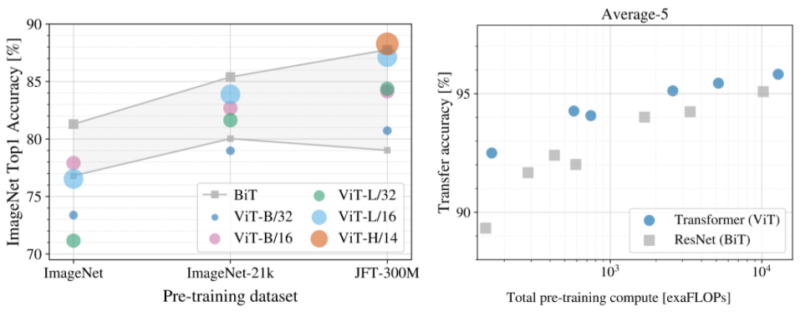
左:さまざまなデータセットで事前トレーニングした場合のViTのパフォーマンス
右:ViTは、優れたパフォーマンスと計算のトレードオフをもたらします。
高性能な大規模画像認識
私達のデータは、
(1)十分なトレーニングがあればViTは非常にうまく機能する
(2)ViTは、小規模または大規模な計算処理が必要になる両方のケースで優れたパフォーマンスと計算のトレードオフをもたらす
ことを示唆しています。従って、パフォーマンスの向上がさらに大規模に引き継がれるかどうかを確認するために、6億パラメーターのViTモデルをトレーニングしました。
この大規模なViTモデルは、ImageNetで88.55%のTop-1精度、CIFAR-10での99.50%を含む、複数の一般的なベンチマークで最先端のパフォーマンスを実現します。
ViTは、クリーンアップされたバージョンのImageNet評価セット「ImageNet-ReaL」でも良好に機能し、90.72%のTop-1精度を達成します。
最後に、ViTは、トレーニングデータポイントが少ない場合でも、さまざまなタスクでうまく機能します。例えば、一連のVTAB-1k(それぞれ1,000データポイントを持つ19のタスク)では、ViTは77.63%を達成し、単一モデルの最先端スコア(SOTA)76.3%を大幅に上回り、さらに、 複数のモデルのアンサンブル(77.6%)をも上回りました。最も重要なことは、これらの結果は、以前のSOTAであるCNNと比較して少ない計算リソースを使用して取得されることです。例えば、事前にトレーニングされたBiTモデルの4分の1です。
Vision Transformerは、人気のあるベンチマークで最先端のCNNに匹敵するか、それを上回ります。
左:人気のある画像分類タスク(ImageNet、新しい検証ラベルセットのReaL、CIFAR、Pets、Flowersを含みます)
右:一連のVTABの19の分類タスクの平均。
視覚化
モデルが何を学習しているのかを直感的に理解するために、モデルの内部動作の一部を視覚化しました。まず、位置embeddingsを確認します。これは、モデルが画像内でのツギハギ画像の相対位置をエンコードするために学習するパラメータです。そして、ViTが直感的な画像構造を再現できていることを発見しました。
各位置embeddingsは、同じ行と列の他のembeddingsと最も類似しており、モデルが元の画像の格子構造を復元できた事を示しています。
次に、各Transformerブロックについて、要素間の平均空間距離を調べます。上位層(深さ10~20)では、大域的な特徴のみが使用されています(つまり、Attentionの距離が長い)。しかし、平均Attentionが広範囲に散らばっている事からわかるように、下位層(深度0~5)は大域的な特徴と局所的な特徴の両方を捕捉しています。
対照的に、CNNsの下位層には局所的な特徴のみが存在します。これらの実験は、ViTがCNNsでは決め打ちされている特徴(格子構造の認識など)を学習できる事を示していますが、一般化を支援できる、下位層での局所的特徴と大域的特徴の混合など、より一般的なパターンも自由に学習できています。
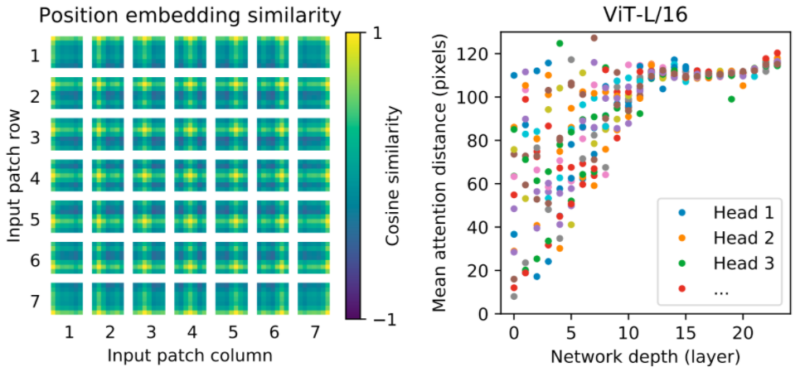
左:ViTは、位置embeddingsを介してツギハギ画像の格子配置を学習します。
右:ViTの下位層には大域的な特徴と局所的な特徴の両方が含まれ、上位層には大域的な特徴のみが含まれます。
概要
CNNsはコンピュータービジョンに革命をもたらしましたが、私達の研究結果は、画像タスク用にカスタマイズされたモデルが不要であるか、最適ではない可能性があることを示しています。
データセットのサイズが増え続け、教師なしおよび半教師ありの方法が継続的に開発されているため、これらのデータセットをより効率的にトレーニングする新しいビジョンアーキテクチャの開発がますます重要になっています。
私達はViTは、多くの視覚タスク、さらには多くの領域固有のタスクを解決できる、汎用的で規模拡大可能なアーキテクチャへの準備段階と信じており、将来の発展に興奮しています。
私達の研究のプレプリント、コード、モデルはgithubで公開されています。
謝辞
ベルリン、チューリッヒ、アムステルダムの共著者に感謝します。
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly そして Jakob Uszkoreit。
インフラストラクチャとオープンソース化に関して重要な支援をしてくれたAndreas Steiner、大規模なトレーニングインフラストラクチャに取り組んでくれたJoan PuigcerverとMaxim Neumannに感謝します。
有益な議論をしてくれた Dmitry Lepikhin、 Aravindh Mahendran、 Daniel Keysers, Mario Lučić、 Noam Shazeer、Colin Raffel。最後に、この投稿でVisualTransformerアニメーションを作成してくれたTom Smallに感謝します。
3.ViT:規模拡大可能な画像認識用のTransformers(2/2)関連リンク
1)ai.googleblog.com
Transformers for Image Recognition at Scale
2)arxiv.org
An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
3)github.com
google-research / vision_transformer

